Abstract
In this project, an audio-only augmented reality sound installation was created as part of the course „Studienprojekte Musikprogrammierung“ (“Study Projects Music Programming”) at the Karlsruhe University of Music. It is important for the following text to distinguish the terminology from virtual reality (VR for short), in which the user is completely immersed in the virtual world. Augmented reality (AR for short) is the extension of reality through the technical addition of information.
Motivation
On the one hand, this sound installation should meet a certain artistic standard, on the other hand, my personal goal was to bring AR and especially auditory AR closer to the participants and to get them excited about this new technology. Unfortunately, augmented reality is very often only understood as the visual representation of information, as is the case with navigation systems or smartphone applications, for example. However, in my opinion, it is important to sensitize people more and more to the auditory extension of reality. I am convinced that this technology also has enormous potential and that there is a lot of catching up to do in terms of public awareness compared to visual augmented reality. There are already numerous areas of application in which the benefits of auditory AR have been demonstrated. These range from areas in which many applications of visual AR can already be found, such as education, increasing productivity or purely for entertainment purposes, to specialist areas such as medicine. Ten years ago, for example, there were already attempts to use auditory AR to enhance the sense of hearing for people with visual impairments. By sonifying real objects, it was possible to create a purely auditory orientation aid.
Methodology
In this project, participants should be able to move freely in a room in which objects are positioned and although these do not produce sounds in reality, the participants should be able to perceive sounds through headphones. In this sense, it is an extension of reality (“augmented reality”), as information is added to reality in auditory form using technical means. Essentially, the areas for implementation extend on the one hand to the positioning of the person (motion capture) and binauralization and on the other hand in the artistic sense to the design of the sound scene by positioning and synthesizing the sounds.
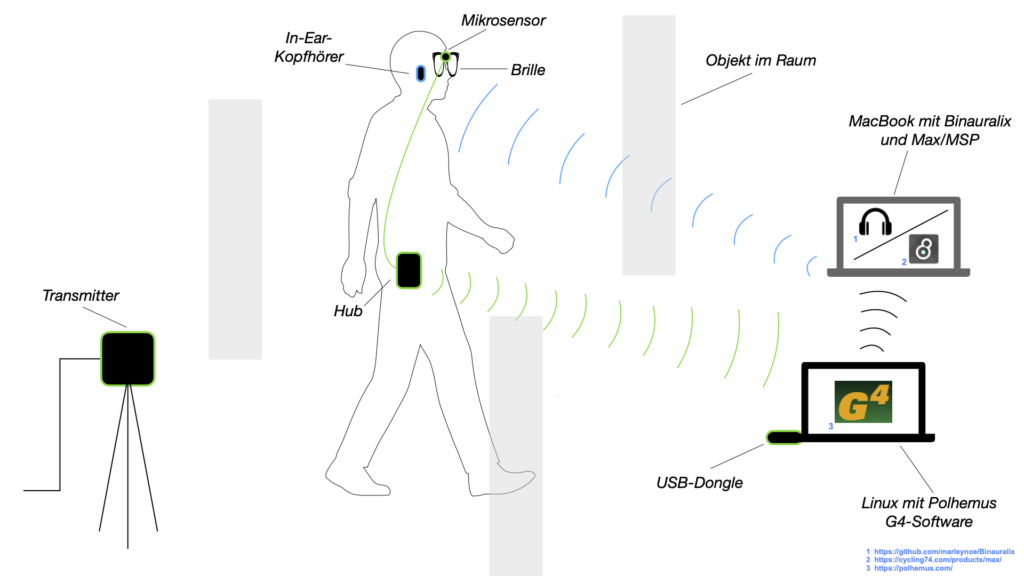
Figure 1
The motion capture in this project is realized with the Polhemus G4 system. The direction and position of a micro-sensor, which is attached to a pair of glasses worn by the participant, is determined by a magnetic field generated by two transmitters. A hub, which is connected to the micro-sensor via a cable, sends the motion capture data to a USB dongle connected to a laptop. This data is sent to another laptop, on which the binauralization takes place and which is ultimately connected to the wireless headphones.
Figure 2 shows two of the six objects in one variant each (angles of 45° and 90°). The next illustration (Fig. 3) shows the over-glasses (protective glasses that can also be worn over glasses) that are used in the sound installation. These goggles have a wide nose bridge to which the micro-sensor is attached with a micro-mount from Polhemus.

Figure 2

Figure 3
As previously explained, various decisions have to be made before the artistic aspect of the sound installation can be realized. This involves the positioning of the objects / sound sources and the sounds themselves.
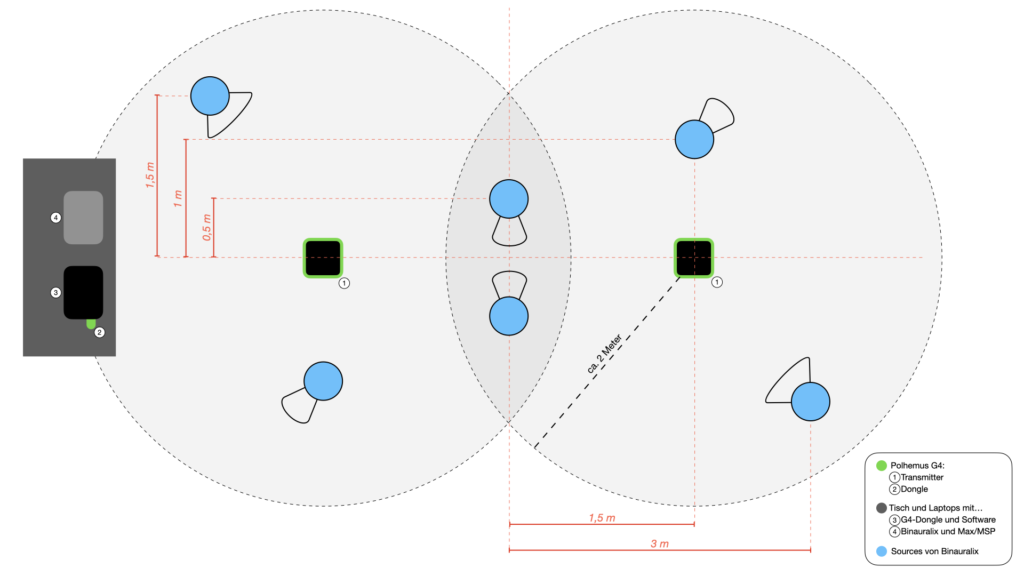
Figure 4
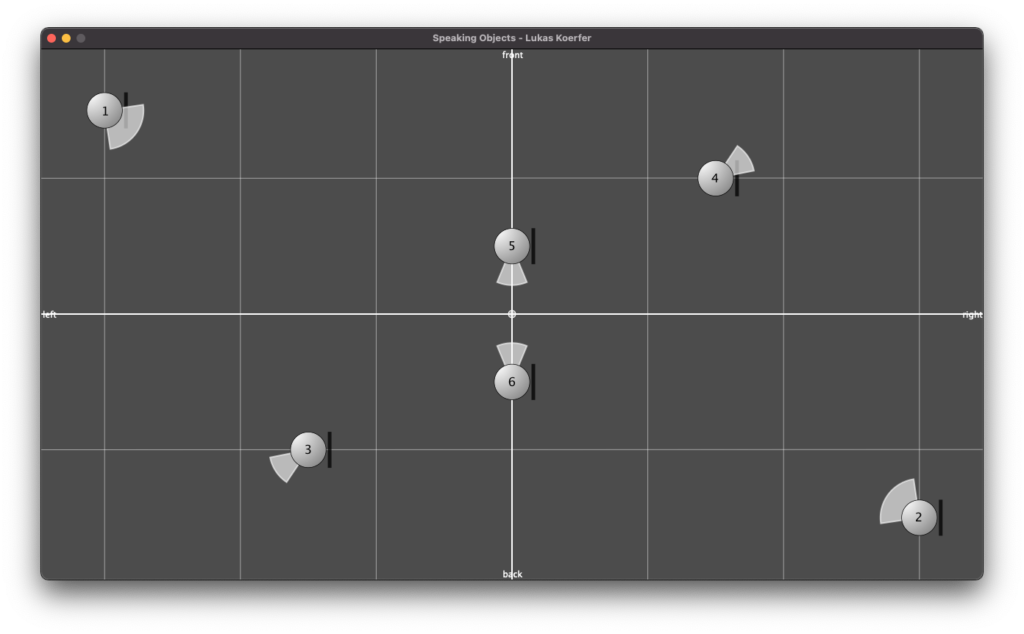
Figure 5
Figure 4 shows a sketched top view of the complete structure. The six blue-colored circles mark the positions of the objects in the room and, of course, the sound sources of the scene in Binauralix, which can be seen in Figure 5. The direction and angle of the sources can be taken from the colorless areas (in Fig. 4), at either 45° or 90° angles, around the sound sources.
The completely wireless position detection and data transmission enables the participants to immerse themselves fully in this experience of the interactive reality-expanding sound world. The sound synthesis was carried out using the SuperCollider software. The sounds were mainly created through various tapping and clicking noises recorded by the SoundIn object, and finally changes and alienation of the sounds through amplitude and frequency modulation and various filters. By routing the sounds to a total of 6 output channels and “s.record(numChannels:6)”, I was able to create a two-minute multi-channel audio file in SuperCollider. When playing the file in Binauralix, the first channel is automatically mapped to source one, the second channel to source 2 and so on.
Technical implementation
The technical challenge for the implementation of the project initially consisted of receiving and reformatting the data from the sensor so that it could be used in Binauralix. The initial problem was that Binauralix is only available for MacOS and the software for the Polhemus G4 system is only available for Windows and Linux. As I had a MacBook and a laptop with Ubuntu Linux as my operating system at the time, I installed the Polhemus software for Linux.
After building and installing the Polhemus G4 software on Linux, the five applications “G4DevCfg”, “CreateSrcCfg”, “g4term”, “g4display” and “g4export” were available. For my project, all devices used must first be connected and configured with “G4DevCfg”. The terminal application “g4export” can be used to transmit the sensor data via UDP by specifying the previously created source configuration file, the local IP address of the receiver device and a port. The source configuration file is a file in which the position and orientation of the transmitter are defined by a “virtual frame of reference” and settings can be made for the entry hemisphere into the magnetic field, floor compensation and source calibration file. To run the application, the transmitters and the hub must be switched on at this point, the USB dongle must be connected to the laptop and the sensor to the hub, and the hub must be connected to the USB dongle. If the MacBook is now in the same network as the Linux laptop, the data can be received by specifying the previously used port. This is done with my sound installation in a self-created MaxMSP patch.

Figure 6
In this application, the appropriate port must first be selected on the left-hand side. As soon as the connection is established and the messages arrive, you can view them in raw form under the selection field. The six values that can be seen at the top in the middle of the application are the values for position and orientation that have been separated from the raw message. Final settings for the correct calibration can now be made in the action field below. There is also the option to mirror the axes individually or to change the Yaw value if unexpected problems should arise when setting up the sound installation. Once the values have been formatted into messages that can be used by Binauralix (visible at the bottom right of the application), they are sent to Binauralix.
The following videos provide a view of the scene in Binauralix and an auditory impression as the listener — driven by the sensor data — moves through the scene.
Past performances of the sound installation