Abstract: Beschreibung des Inertial Motion Tracking Systems Bitalino R-IoT und dessen Software
Verantwortliche: Prof. Dr. Marlon Schumacher, Eveline Vervliet
Introduction
In this blog, I will explain how we can use machine learning techniques to recognize specific conductor gestures sensed via the the BITalino R-IoT platform in Max. The goal of this article is to enable you to create an interactive electronic composition for a conductor in Max.
This project is based on research by Tommi Ilmonen and Tapio Takala. Their article ‚Conductor Following with Artificial Neural Networks‘ can be downloaded here. This article can be an important lead in further development of this project.
Demonstration Patches
In the following demonstration patches, I have build further on the example patches from the previous blog post, which are based on Ircam’s examples. To detect conductor’s gestures, we need to use two sensors, one for each hand. You then have the choice to train the gestures with both hands combined or to train a model for each hand separately.
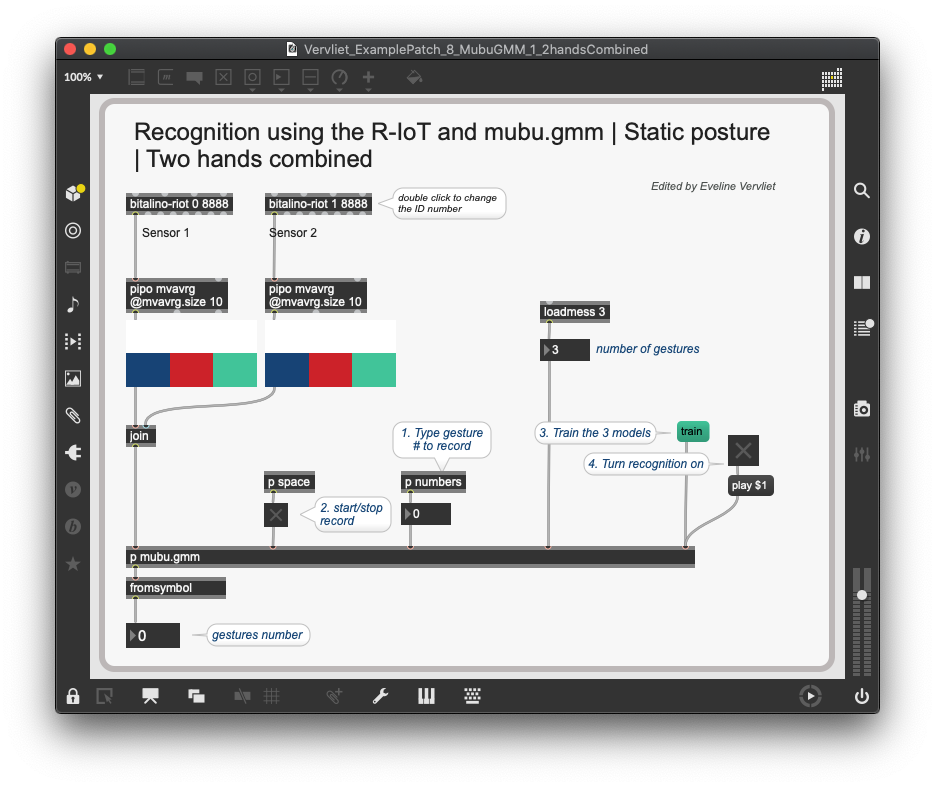
Detect static gestures with 2 hands combined
When training both hands combined, there are only a few changes we need to make to the patches for one hand.
First of all, we need a second [bitalino-riot] object. You can double click on the object to change the ID. Most likely, you’ll have chosen sensor 1 with ID 0 and sensor 2 with ID 1. The data from both sensors are joined in one list.
In the [p mubu.gmm] subpatch, you will have to change the @matrixcols parameter of the [mubu.record] object depending on the amount of values in the list. In the example, two accelerometer data lists with each 3 values were joined, thus we need 6 columns.
The rest of the process is exactly the same as in previous patches: we need to record two or more different static postures, train the model, and then click play to start the gesture detection.
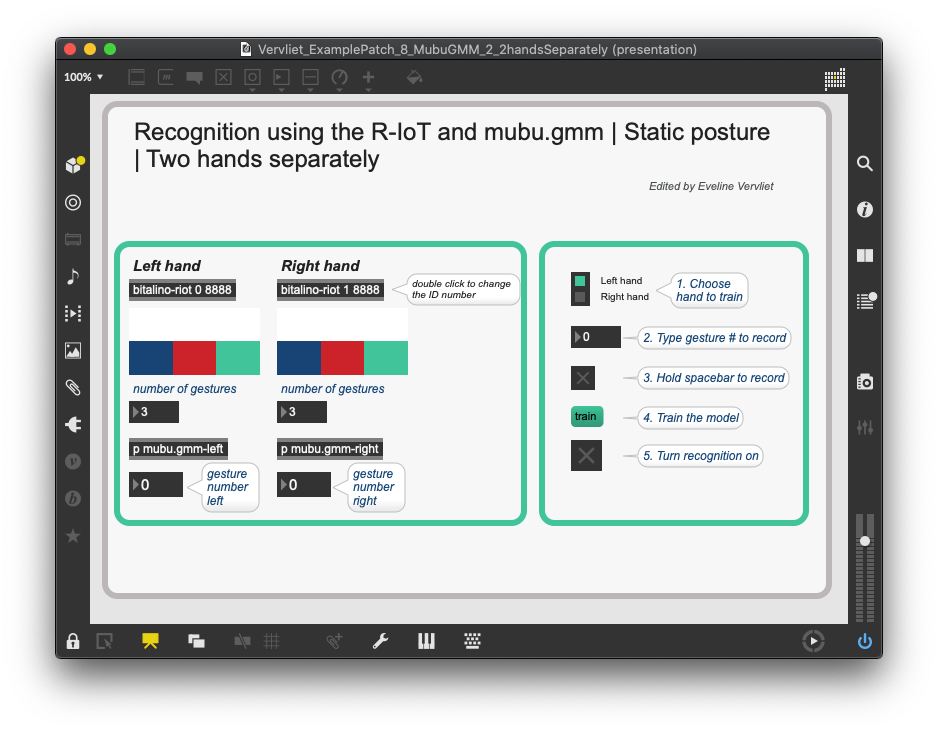
When training both hands separately, the training process becomes a bit more complex, although most steps remain the same. Now, there is a unique model for each hand, which has to be trained separately. You can see the models in the [p mubu.gmm-left] and [p mubu.gmm-right] subpatches. There is a switch object which routes the training data to the correct model.
In the above example, I personally found the training with both hands separate to be most efficient: even though the training process took slightly longer, the programming after that was much easier. Depending on your situation, you will have to decide which patch makes most sense to use. Experimentation can be a useful tool in determining this.
Detect dynamic gestures with 2 hands
The detection with both hands of dynamic gestures follow the same principles as the above examples. You can download the two Max patches here:
The mentioned tools can be used to detect ancillary gestures in musicians in real-time, which in turn could have an impact on a musical composition or improvisation. Ancillary gestures are „musician’s performance movements which are not directly related to the production or sustain of the sound“ (Lähdeoja et al.) but are believed to have an impact both in the sound production as well as in the perceived performative aspects. Wanderley also refers to this as ‘non-obvious performer gestures’.
In a following article, Marlon Schumacher worked with Wanderley on a framework for integrating gestures in computer-aided composition. The result is the Open Music library OM-Geste. This article is a helpful example of how the data can be used artistically.
Links to articles:
Marcelo M. Wanderley – Non-obvious Performer Gestures in Instrumental Musicdownload
O. Lähdeoja, M. M. Wanderley, J. Malloch – Instrument Augmentation using Ancillary Gestures for Subtle Sonic Effectsdownload
M. Schumacher, M. Wanderley – Integrating gesture data in computer-aided composition: A framework for representation, processing and mappingdownload
Detecting gestures in musicians has been a much-researched topic in the last decades. This folder holds several other articles on this topic that could interest.
In diesem Projekt entstand im Rahmen der Lehrveranstaltung „Studienprojekte Musikprogrammierung“ eine audio-only Augmented Reality Klanginstallation an der Hochschule für Musik Karlsruhe. Wichtig für den nachfolgenden Text ist die terminologische Abgrenzung zur Virtual Reality (kurz: VR), bei welcher der Benutzer komplett in die virtuelle Welt eintaucht. Bei der Augmented Reality (kurz: AR) handelt es sich um die Erweiterung der Realität durch das technische Hinzufügen von Information.
Motivation
Zum einen soll diese Klanginstallation einem gewissen künstlerischen Anspruch gerecht werden, zum anderen war auch mein persönliches Ziel dabei, den Teilnehmern das AR und besonders das auditive AR näher zu bringen und für diese neu Technik zu begeistern. Unter Augmented Reality wird leider sehr oft nur die visuelle Darstellung von Informationen verstanden, wie sie zum Beispiel bei Navigationssystemen oder Smartphone-Applikationen vorkommen. Allerdings ist es meiner Meinung nach wichtig die Menschen auch immer mehr für die auditive Erweiterung der Realität zu sensibilisieren. Ich bin der Überzeugung, dass diese Technik auch ein enormes Potential hat und bei der Aufmerksamkeit in der Öffentlichkeit, im Vergleich zum visuellen Augmented Reality, ein sehr großer Nachholbedarf besteht. Es gibt mittlerweile auch schon zahlreiche Anwendungsbereiche, in welchen der Nutzen des auditiven AR präsentiert werden konnte. Diese erstrecken sich sowohl über Bereiche, in welchen sich bereits viele Anwendung des visuellen AR vorfinden, wie z.B. der Bildung, Steigerung der Produktivität oder zu reinen Vergnügungszwecken als auch in Spezialbereichen wie der Medizin. So gab es bereits vor zehn Jahren Unternehmungen, mithilfe auditiver AR eine Erweiterung des Hörsinnes für Menschen mit Sehbehinderung zu kreieren. Dabei konnte durch Sonifikation von realen Objekten eine rein auditive Orientierungshilfe geschaffen werden.
Methodik
In diesem Projekt sollen Teilnehmer*innen sich frei in einem Raum, in welchem Gegenstände positioniert sind, bewegen können und obwohl diese in der Realität keine Klänge erzeugen, sollen die Teilnehmer*innen Klänge über Kopfhörer wahrnehmen können. In diesem Sinne also eine Erweiterung der Realität („augmented reality“), da mithilfe technischer Mittel Informationen in auditiver Form der Wirklichkeit hinzugefügt werden. Im Wesentlichen erstrecken sich die Bereiche für die Umsetzung zum einen auf die Positionsbestimmung der Person (Motion-Capture) und die Binauralisierung und zum anderen im künstlerischen Sinne auf die Gestaltung der Klang-Szene durch Positionierung und Synthese der Klänge.
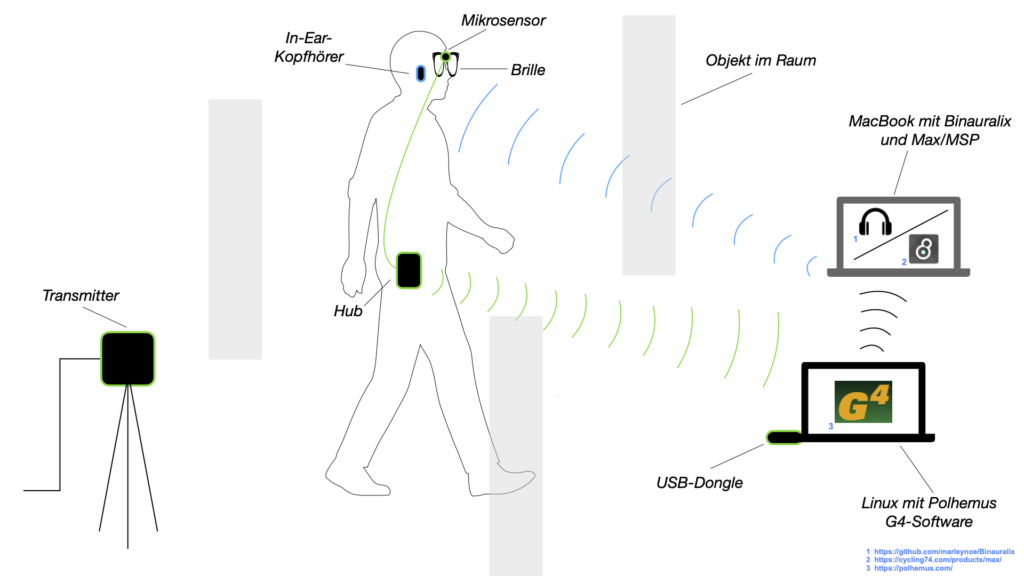
Abbildung 1
Das Motion-Capture wird in diesem Projekt mit dem Polhemus G4 System realisiert. Die Richtung- und Positionsbestimmung eines Micro-Sensors, welcher an einer vom Teilnehmer getragenen Brille befestigt wird, geschieht durch ein Magnetfeld, welches von zwei Transmittern erzeugt wird. Ein Hub, der über ein Kabel mit dem Micro-Sensor verbunden ist, sendet die Daten des Motion-Captures an einen USB-Dongle, der an einem Laptop angeschlossen ist. Diese Daten werden an einen weiteren Laptop gesendet, auf welchem zum einen die Binauralisierung geschieht und der zum anderen letztendlich mit den kabellosen Kopfhörern verbunden ist.
In Abbildung 2 kann man zwei der sechs Objekte in je einer Variante (Winkel von 45° und 90°) betrachten. In der nächsten Abbildung (Abb. 3) ist die Überbrille (Schutzbrille die auch über einer Brille getragen werden kann) zu sehen, welche in der Klanginstallation zum Einsatz kommt. Diese Brille verfügt über einen breiten Nasensteg, auf welchem der Micro-Sensor mit einem Micro-Mount von Polhemus befestigt ist.
Abbildung 2
Abbildung 3
Wie schon zuvor erläutert, müssen für den Aufbau der Klanginstallation auch diverse Entscheidung vor einem künstlerischen Aspekt getroffen werden. Dabei geht es um die Positionierung der Gegenstände / Klangquellen und die Klänge selbst.
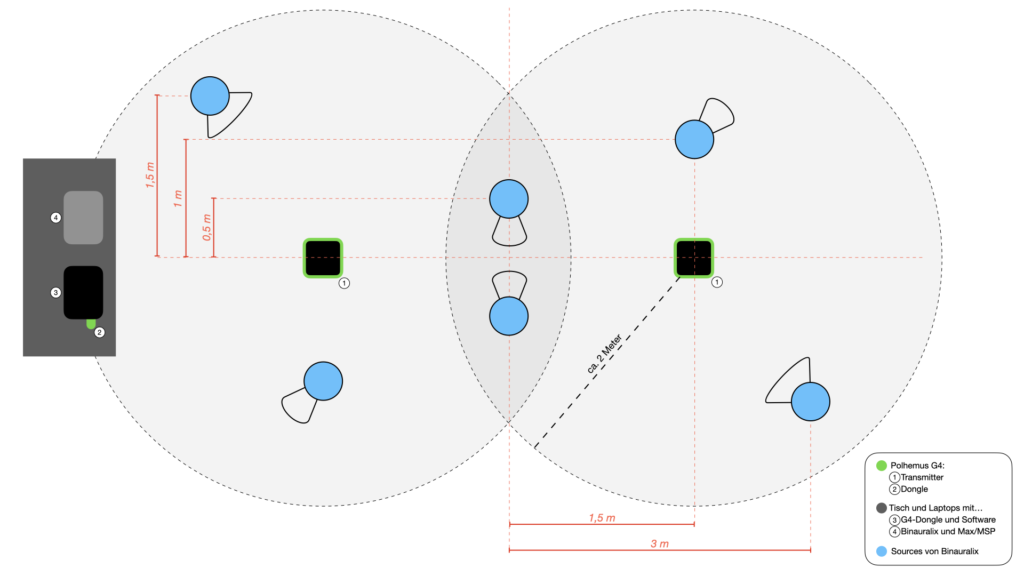
Abbildung 4
Abbildung 5
Die Abbildung 4 zeigt eine skizzierte Draufsicht des kompletten Aufbaus. Die sechs blau gefärbten Kreise markieren die Positionen der Gegenstände im Raum und natürlich gleichzeitig die der Klangquellen der Szene in Binauralix, welche in Abbildung 5 zu erkennen ist. Den farblosen Bereichen (in Abb. 4), im entweder 45° oder 90° Winkel, um die Klangquellen, können Richtung und Winkel der Quellen entnommen werden.
Die komplett kabellose Positionserfassung und Datenübertragung, ermöglicht den Teilnehmer*innen das uneingeschränkte Eintauchen in dieses Erlebnis der interaktiven realitätserweiternden Klangwelt. Die Klangsynthese wurde mithilfe der Software SuperCollider vorgenommen. Die Klänge entstanden hauptsächlich durch diverse Klopf- und Klickgeräusche, welche durch das SoundIn-Objekt aufgenommen wurden, und schließlich Veränderungen und Verfremdungen der Klänge durch Amplituden- und Frequenzmodulation und diverse Filter. Durch Audio-Routing der Klänge auf insgesamt 6 Ausgangskanäle und „s.record(numChannels:6)“ konnte ich in SuperCollider eine zweiminütige Mehrkanal Audio-Datei erstellen. Beim Abspielen der Datei in Binauralix wird automatisch der erste Kanal auf die Source eins, der zweite Kanal auf die Source 2 usw. gemappt.
Technische Umsetzung
Die technische Herausforderung für die Umsetzung des Projekts bestand zuerst grundlegen aus dem Empfangen und dem Umformatieren der Daten des Sensors, sodass diese in Binauralix verwertet werden können. Dabei bestand zunächst das Problem, dass Binauralix nur für MacOS und die Software für das Polhemus G4 System nur für Windows und Linux verfügbar sind. Da mir zu diesem Zeitpunkt neben einem MacBook auch ein Laptop mit Ubuntu Linux als Betriebssystem zur Verfügung stand, installierte ich die Polhemus Software für Linux.
Nach dem Bauen und Installieren der Polhemus G4 Software auf Linux, standen einem die fünf Anwendungen „G4DevCfg“, „CreateSrcCfg“, „g4term“, „g4display“ und „g4export“ zur Verfügung. Für mein Projekt muss zuerst mit „G4DevCfg“ alle verwendeten Devices miteinander verbunden und konfiguriert werden. Mit der Terminal-Anwendung „g4export“ kann man durch Angabe der zuvor erstellten Source-Configuration-File, der lokalen IP-Adresse des Empfänger-Gerätes und einem Port die Daten des Sensors über UDP übermitteln. Die Source-Configuration-File ist eine Datei, in welcher zum einen Position und Orientierung der Transmitter durch einen „Virtual Frame of Reference“ festgelegt werden und zum anderen Einstellungen zu Eintritts-Hemisphäre in das Magnetfeld, Floor Compansation und Source-Calibration-File vorgenommen werden können. Zum Ausführen der Anwendung müssen zu diesem Zeitpunkt die Transmitter und der Hub angeschaltet, der USB-Dongle am Laptop und der Sensor am Hub angeschlossen und der Hub mit dem USB-Dongle verbunden sein. Wenn sich nun das MacBook im selben Netzwerk wie der Linux-Laptop befindet, kann mit der Angabe des zuvor genutzten Ports die Daten empfangen werden. Dies geschieht bei meiner Klanginstallation in einem selbst erstellen MaxMSP-Patch.
Abbildung 6
In dieser Anwendung muss zuerst auf der linken Seite der passende Port gewählt werden. Sobald die Verbindung steht und die Nachrichten ankommen, kann man diese unter dem Auswahlfeld in der raw-Form betrachten. Die sechs Werte, die oben im mittleren Bereich der Anwendung zu sehen sind, sind die aus der rohen Nachricht herausgetrennten Werte für die Position und Orientierung. In dem Aktionsfeld darunter können nun finale Einstellung für die richtige Kalibrierung vorgenommen werden. Darüber hinaus gibt es auch noch die Möglichkeit die Achsen individuell zu spiegeln oder den Yaw-Wert zu verändern, falls unerwartete Probleme bei der Inbetriebnahme der Klanginstallation aufkommen sollten. Nachdem die Werte in Nachrichten formatiert wurden, die von Binauralix verwendet werden können (zu sehen rechts unten in der Anwendung), werden diese an Binauralix gesendet.
Das folgenden Videos bieten einen Blick auf die Szene in Binauralix und einen Höreindruck, während sich der Listener — gesteuert von den Sensor-Daten — durch die Szene bewegt.
Vergangene Vorstellungen der Klanginstallation
Die Klanginstallation als Beitrag im Rahmen der EFFEKTE-Vortragsreihe des Wissenschaftsbüro-Karlsruhe
Die Klanginstallation als Gegenstand eines Workshops für die Kulturakademie an der HfM-Karlsruhe
Im folgenden möchte ich einen Einblick in die künstlerische und technische Entwicklung meines Stückes „Warten auf die Nacht“ geben. Dieser Beitrag wird fortlaufend aktualisiert und wird so den Entwicklungsprozess dokumentieren.
Das Stück soll von einer Performerin und einer Zeichnerin ausgeführt werden.
Technischer Bericht
Setup
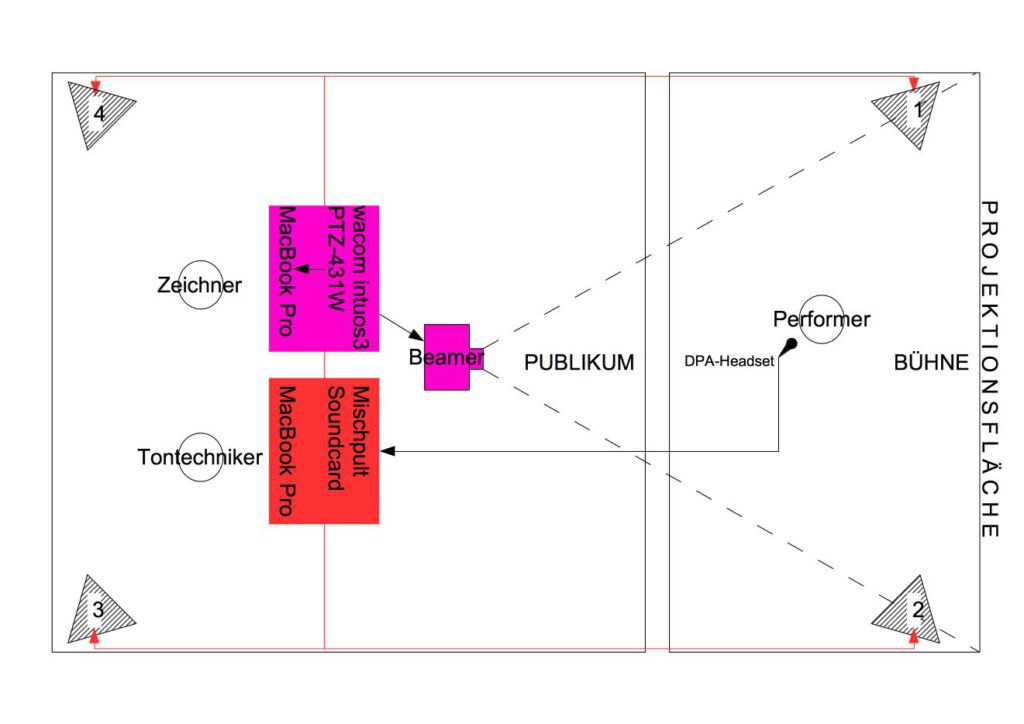
Auf der Bühne steht die Performerin. Der Beamer muss so positioniert werden, dass das Bild über die Performerin hinweg auf die Projektionsfläche geworfen wird. Es sollte kein Schattenwurf der Performerin entstehen.
Bis letzten August, waren meine Vorstellung zu Anwendungen maschinellen Lernens meist funktional, getrennt von einer ästhetischen Referenz zu meiner künstlerischen Praxis: PKWs, die Verkehrsampeln erkennen, oder Radiolog*innen die bösartige Regionen in menschlichem Gewebe entdecken – das sind die ersten Dinge, die mir einfallen. Es gibt bestimmt eine Kunst hinter der Programmierung dieser Anwendungen. Jedoch war mir noch nicht klar, wie sich maschinelles Lernen auf meine Welt der zeitgenössischen Musik beziehen könnte. Deswegen war meine Hauptinteresse, als ich anArtemi-Maria GiotisMachine Learning Workshop bei der 2021 impuls Akademie teilgenommen habe, persönliche künstlerische Verbindungen zu diesem Forschungsbereich herzustellen und zu sehen, auf welche Weise ich meine zugrundeliegenden ästhetischen Annahmen über künstlerischen Anwendungen von maschinellen Lernen hinterfragen kann. Das Ziel dieses Textes ist es, mit euch die Verbindungen zu teilen, die ich hergestellt habe. Ich werde den Kompositionsprozess meines Stücks für Stimme und Live-ElektronikShepherddurchgehen und es als Rahmen verwenden, um grundlegende Theorien und Methoden von maschinellen Lernen vorzustellen und zu skizzieren, wie ich ästhetisch auf sie reagiert habe. Ich werde nicht tief in technische Details gehen. Jedoch möchte ich anmerken, dass der technische Inhalt dieses Blogposts stark von Artemi-Maria Gioti inspiriert ist, die diesen Workshop geleitet hat und deren Forschung sich mit den kreativen Anwendungen von maschinellen Lernen in einer viel tieferen Weise beschäftigt. Ein tieferes Eintauchen in die vielfältigen Beziehungen zwischen maschinellen Lernen und Musik kann auf ihrerWebsitebegonnen werden.
Die grundlegende Idee von maschinellen Lernen lautet „Verbesserung durch Erfahrung“. Der Informatiker Tom M. Mitchell beschreibt es so: „Der Bereich maschinellen Lernen befasst sich mit der Frage, wie man Computerprogramme konstruiert, die sich durch Erfahrung automatisch verbessern.“ (Mitchell, T. (1998). Machine Learning. McGraw-Hill.). Diese Prämisse der „Verbesserung“ hat mich bereits mit nicht-trivialen Fragen konfrontiert. Wenn zum Beispiel maschinelles Lernen eingesetzt wird, um einen improvisierenden Duopartner zu schaffen, was genau versteht der Computer dann als „gute“ oder „schlechte“ Improvisation, wenn er an Erfahrung gewinnt? Das Beantwort dieser ersten Frage ist nötig, bevor man überhaupt mit der Entwicklung eines robusten Algorithmus für maschinelles Lernen beginnen kann. In meinem Stück Shepherd wurde die Elektronik darauf trainiert, meine Stimme zu erkennen, insbesondere ob ich flüstere, rede, schreie oder schweige. Mein Ziel war es jedoch nicht, einen perfekt genauen Erkennungsalgorithmus zu schaffen. Vielmehr wollte ich, dass die Effektivität und die Ineffektivität des Algorithmus bei der Konzeption des Stücks gleiche Wichtigkeit haben. Shepherd ist ein Performance-Stück nach einer Metapher von Jesus aus der christlichen Bibel: Schafe erkennen einen Hirten am Klang seiner Stimme (Johannes 10). Die Elektronik reagiert auf meine Stimme in einer Weise, die gleichzeitig sicher und unsicher ist. Diese Performance ist eine Reflexion über die Nuancen des spirituellen Glaubens, über die Art und Weise, wie Ungewissheit ein notwendige Teil an der Bildung von Überzeugung und Glauben ist. Hier war die Elektronik kein funktionales Instrument (etwas, das von meiner Stimme gesteuert werden sollte), sondern fungierte eher als zweiter Spieler (ein Duopartner, der auf meine Stimme mit einer eingeschränkte Unvorhersehbarkeit reagierte).
Klicken Sie hier für eine deutsche Version dieses Textes.
Up until this past August, my impressions of what machine learning could be used for was mostly functional, detached from any aesthetic reference point within my artistic practice. Cars recognizing stop signs, radiologists detecting malignant legions in tissue; these are the first things to come to my mind. There is definitely an art behind programming these tasks. However, it wasn’t clear to me yet how machine learning could relate to my world of contemporary concert music. Therefore, when I participated in Artemi-Maria Gioti’s machine learning workshop at impuls Academy 2021, my primary interest was to make personal artistic connections to this body of research, and to see what ways I could interrogate my underlying aesthetic assumptions in artistic applications of machine learning. The purpose of this text is to share with you the connections I made. I will walk through the composition process of my piece Shepherd for voice and live electronics, using it as a frame to touch upon basic machine learning theories and methods, as well as outline how I aesthetically reacted to them. I will not go deep into the technicalities of machine learning – there are far more qualified people than I for that specific task. However, I will say that the technical content of this blogpost is inspired heavily from Artemi-Maria Gioti, who led this workshop and whose research covers the creative applications of machine learning in a much deeper way. A further dive into the already rich world of machine learning and music can be begun at her website.
A fundamental definition of machine learning can be framed around the idea of improvement through experience. As computer scientist Tom M. Mitchell describes it, “The field of machine learning is concerned with the question of how to construct computer programs that automatically improve with experience.” (Mitchell, T. (1998). Machine Learning. McGraw-Hill.). This premise of ‘improvement’ already confronted me with non-trivial questions. For example, if machine learning is utilized to create an improvising duo partner, what exactly does the computer understand as ‘good’ or ‘bad’ improvisation, as it gains experience? Before even beginning to build a robust machine learning algorithm, answering this preliminary question is an entire undertaking in and of itself. In my piece Shepherd, the electronics were trained to recognize the sound of my voice, specifically whether I was whispering, talking, yelling, or being silent. However, my goal was not to create a perfectly accurate recognition algorithm. Rather, I wanted the effectiveness and the ineffectiveness of the algorithm to both play equal roles in achieving the piece’s concept. Shepherd is a performance piece takes after a metaphor from Jesus in the christian bible – sheep recognize a shepherd by the sound of their voice (John 10). The electronics reacts to my voice in a way that is simultaneously certain and uncertain. It is a reflection, through performance, on the nuances of spiritual faith, the way uncertainty necessarily partakes in the formation of conviction and belief. Here the electronics were not functional instrument (something designed to be controlled by my voice), but rather were functioning more as a second player (a duo partner, reacting to my voice with a level of unpredictability).
Concretely in the program, the electronics returned two separate answers for every input it is given (see figure 1). It gives a decisive, classification answer (“this is ‘silence’, this is ‘whispering’, this is ‘talking’, etc.), and it gives an indecisive, erratic answer via regression (‘silence: 0.833; whispering: 0.126; talking: 0.201; yelling: 0.044’). And important for this concept of conceiving belief through doubt, the classification answer is derived from the regression answer. The decisive answer (classification) was generally stable in its changes over time, while the indecisive answer (regression) moved more quickly and erratically. Overall, this provided a useful material for creating dynamic control of the actual digital sounds that the electronics produced. But before touching on the DSP, I want to outline how exactly these machine learning algorithms operate, how the electronics learn and evaluate the sound of my voice.
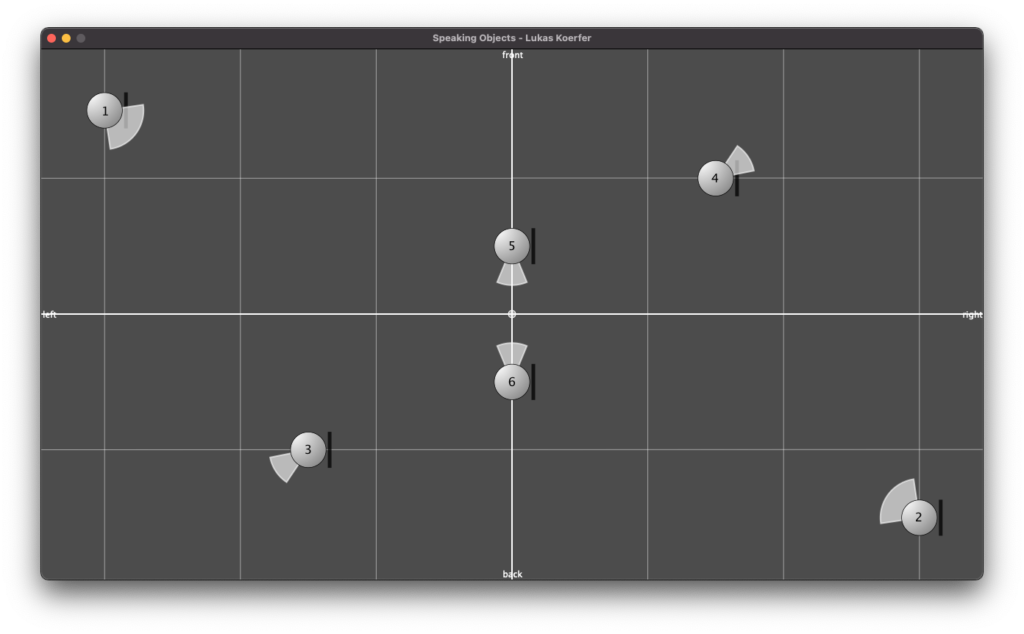
Figure 1: Max MSP and Wekinator (off-screen) analyze an audio’s MFCCs to give two outputs on the nature of the input audio. The first output is from a regression algorithm, the second is from a classification algorithm.
In order for the electronics to evaluate my input voice, it first needs a training set, a collection of data extracted from audio of my voice, with which it could use to ‘learn’ my voice. An important technical point is that the machine learning algorithm never observes actual audio data. With training and testing data, the algorithm is always looking at numerical data (here called ‘descriptors’) extracted from the audio. This is one reason machine learning algorithms can work in realtime, even with audio. As I alluded to, my voice recognition program is underpinned by two machine learning concepts: classification and regression. A classification algorithm will return a discrete value from its input data. In my case, those values are ‘silence’, ‘whispering’, ’talking’, and ‘yelling’. To make a training set then, I recorded audio of each of these classes (4 audio files in total), and extracted MFCCs (Mel-Frequency Cepstrum Coefficients) from it. MFCC’s are a representation a sound’s spectral energy calibrated to the range of typical human auditory perception, and are already commonly used in speech recognition programs, music-information retrieval applications, and other applications based around timbre-recognition.
I used the Max MSP library Zsa.descriptors to calculate my MFCCs. I also experimented with other audio descriptors such as spectral centroid, spectral flatness, amplitude peaks, as well as varying numbers of MFCC’s. Eventually I discovered that my algorithm was most accurate when 13 MFCCs were the only descriptor, and that description data was taken only about fivetimes a second. I realized that, on a micro-level timescale, my four classes had a lot similarity. For example, the word ‘synthesizer,’ carried lots of ’s’ noise, which is virtually the same when whispered as when talked. Because of this, extracting data at an intentionally slower rate gave the algorithm a more general picture of each of my voice-classes, allowing these micro-moments of similarity to be smoothed out.
The standard algorithm used for my voice recognition concept was classification. However, my classification algorithm was actually built using a second common machine learning algorithm: regression. As I mentioned before, I wanted to build into my electronics a level of ‘indecision’, something erratic that would contrast the stable nature of a standard classification algorithm. Rather than returning discrete values, a regression algorithm gives a new ‘predictive’ value, based on a function derived from the training set data. In the context of my piece, the regression algorithm does not return a specific voice-class. Rather, it gives four percentage values, each corresponding to how close or far my input is to each of the four voice-classes. Therefore, though I may be whispering, the algorithm does not say whether I am whispering or not. It merely tells me how close or far away I am from the ‘whispering’ data that it has been trained on.
I used a regression algorithm in Wekinator, a simple and powerful machine learning tool, to build my model (see figure 2). Input audio was analyzed in Max MSP, and the descriptor data was sent via OSC to Wekinator. Wekinator built the predictive regression model from this data and then sent output back to Max MSP to be used for DSP control. In Max, I made my own version of a classification algorithm based on this regression data.
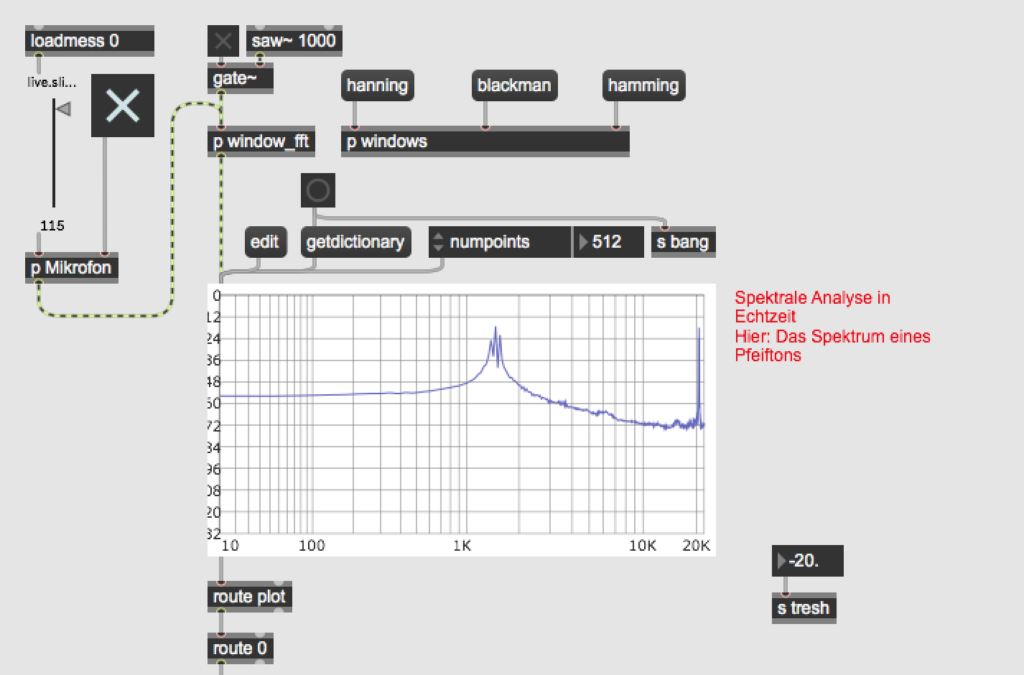
Figure 2: Wekinator is evaluating MFCC data from Max MSP and returning 4 values from 0.0-1.0, indicating the input’s similarity to the four voice classes (silence, whispering, talking, yelling). The evaluation is a regression model trained on 752 data samples.
All this algorithm-building once again returns me to my original concern. How can I make an aesthetic connection with these concepts? As I mentioned, this piece, Shepherd is for my solo voice and live electronics. In the piece I stand alone on a stage, switching through different fictional personas (a speaker at a farming convention, a disgruntled restaurant chef, a compilation video of Danny Wolfers saying the word ‘synthesizer,’ and a preacher), and the electronics reacts to these different characters by switching through its own set of personas (sheep; a whispering, whimpering sous chef; a literal synthesizer; and a compilation of christian music). Both the electronics and I change our personas in reaction to each other. I exercise some level control over the electronics, but not total. As I said earlier, the performance of the piece is a reflection on the intertwinement of conviction and doubt, decision and indecision, within spiritual faith. Within this concept, the idea of a machine ‘improving’ towards ‘perfection’ is no longer an effective framework. In the concept, and consequently in the music I attempted to make, stable belief (classification) and unstable indecision (regression) were equal contributors towards the musical relationship between myself and the electronics.
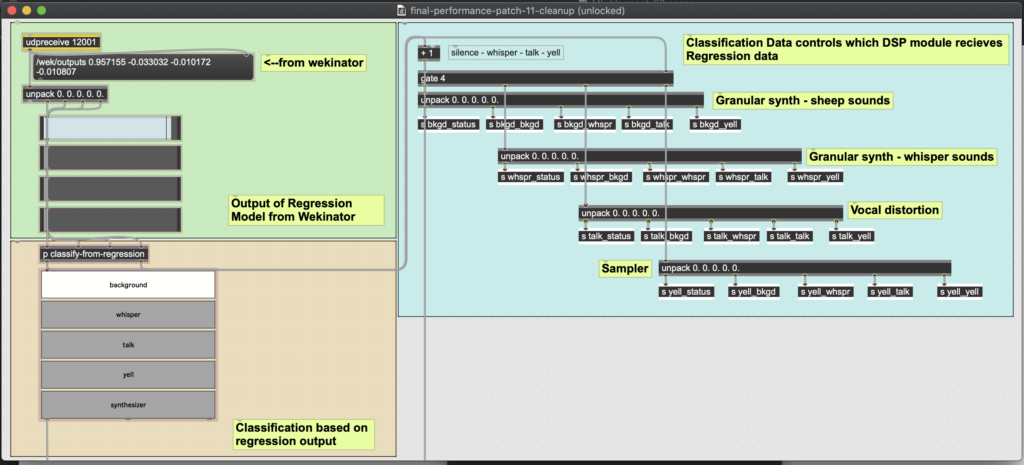
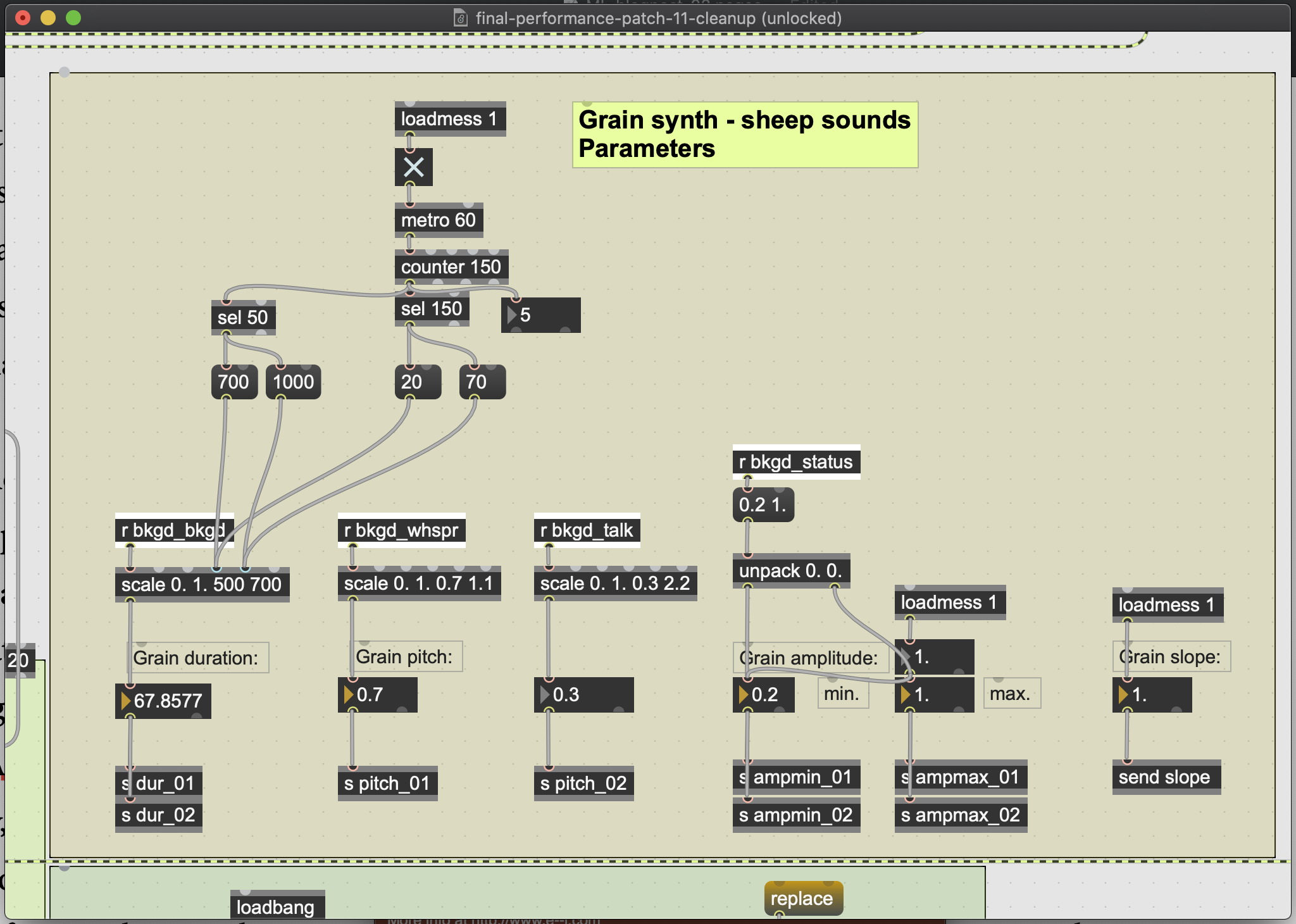
Based on how my voice was classified, the electronics operated one of four DSP modules. The individual parameters of a given module were controlled by the erratic output data of the regression algorithm (see figure 3). For example, when my voice was classified as silent, a granular synthesizer would create textures of sheep-like noises. Within that synthesizer, the percentage levels of whispering and talking ‘detected’ within the silence would manipulate the pitch shifting in the synthesizer (see figure 4). In this way, the music was not just four distinct sound modules. The regression algorithm allowed for each module to bend and flex in certain directions, as my voice subtly suggested hints of one voice class from within another. For example, in one section I alternate rapidly between the persona of a farmer talking at a farming convention, and a chef frustratingly whispering at his sous chef. The electronics moved consequently between my whispering and talking DSP modules. But also, as my whispering became more frustrated and exasperated, the electronics would output higher levels of talking in its regression algorithm. Thus, the internal drama of my theatricalperformances is reacted to by the electronics.
Figure 3: The classification data would trigger one of four DSP modules. A given DSP module would receive the regression values for all four vocal classes. These four values would control the parameters of the DSP module.
Figure 4: Parameter window for granular synth triggered when the electronics classifies my voice as ‘silent’. The amount of whispering and talking detected in the silence would control the pitch of the grain. The amount of silence detected in the silence controlled the grain’s duration. Because this value is relatively static during actual silence from my voice, a level of artificial duration manipulation (seen a the top of the window) was programmed.
I want to return to Tom Mitchell’s thesis that machine learning involves computer improvingautomatically through experience. If Shepherd is a voice recognition tool, then it is inefficient at improvement. However, Shepherd was not conceived as a tool. Rather, creating Shepherd was more so a cultivation of a relationship between my voice and the electronics. The electronics were more of a duo partner, and less of an instrument. To put this more concretely, I was never looking for ‘accurate’ results from the machine. As I programmed, I was searching for results that illustrated Shepherd’s artistic concept of belief intertwined with doubt. In this way, ‘improving’ the piece did not mean improving the algorithm’s accuracy. It meant ‘improving‘ the relationship between myself and the electronics. One positive from this approach is that the compositional process was never separated from the programming of the electronics. Both developed in tandem. The composing this piece brought me to the realization that creative applications of machine learning can be applied at every level of its discourse. If you ware interested in hearing a recording of this performance, a bootleg recording of the premiere can be found here.
References:
Artemi-Maria Gioti – composer and artistic researcher working in the field of artificial intelligence.
Wekinator – free, open-source software created by Rebecca Fiebrink that uses machine learning to create musical instruments, game interfaces, computervision, and other tools in sound and animation.
Zsa.descriptors – library for real-time sound descriptors analysis for Max MSP developed by Mikhail Malt and Emmanuel Jourdan.