Die Installation „Immersive Bodies / Immersive Körper“ im Auftrag der GEDOK Karlsruhe ist eine immersive, intermediale Installation, die die Auswirkungen des Klimawandels auf die allgemeine Befindlichkeit der Bevölkerung untersucht. Da das aktuelle Thema von GEDOK der Klimawandel ist, wollte ich mich den anderen Künstlern anschließen, um dieses Thema zu erforschen. Diese Arbeit konzentriert sich jedoch auf die Erforschung einer etwas anderen Perspektive, die sich nicht auf die Auswirkungen der Veränderung auf der Erde konzentriert, sondern auf den mentalen Zustand der Bevölkerung.
Diese Installation bietet den Menschen einen sicheren und entspannenden Raum, den sie genießen können und gleichzeitig ein Bewusstsein dafür verbreiten, wie wir der Erde und uns selbst sowohl physisch als auch mental helfen können. Die Installation wird immersiv sein und alle Sinne der Besucher berühren. Während der Installation werden mehrere Konzerte gespielt, darunter das Eröffnungskonzert am 23.06.2023 um 20 Uhr. Über die Musik, die während der Installation und der Konzerte gespielt wird, werden wir heute sprechen!
Abstract: Beschreibung des Inertial Motion Tracking Systems Bitalino R-IoT und dessen Software
Verantwortliche: Prof. Dr. Marlon Schumacher, Eveline Vervliet
Introduction
In this blog, I will explain how we can use machine learning techniques to recognize specific conductor gestures sensed via the the BITalino R-IoT platform in Max. The goal of this article is to enable you to create an interactive electronic composition for a conductor in Max.
This project is based on research by Tommi Ilmonen and Tapio Takala. Their article ‚Conductor Following with Artificial Neural Networks‘ can be downloaded here. This article can be an important lead in further development of this project.
Demonstration Patches
In the following demonstration patches, I have build further on the example patches from the previous blog post, which are based on Ircam’s examples. To detect conductor’s gestures, we need to use two sensors, one for each hand. You then have the choice to train the gestures with both hands combined or to train a model for each hand separately.
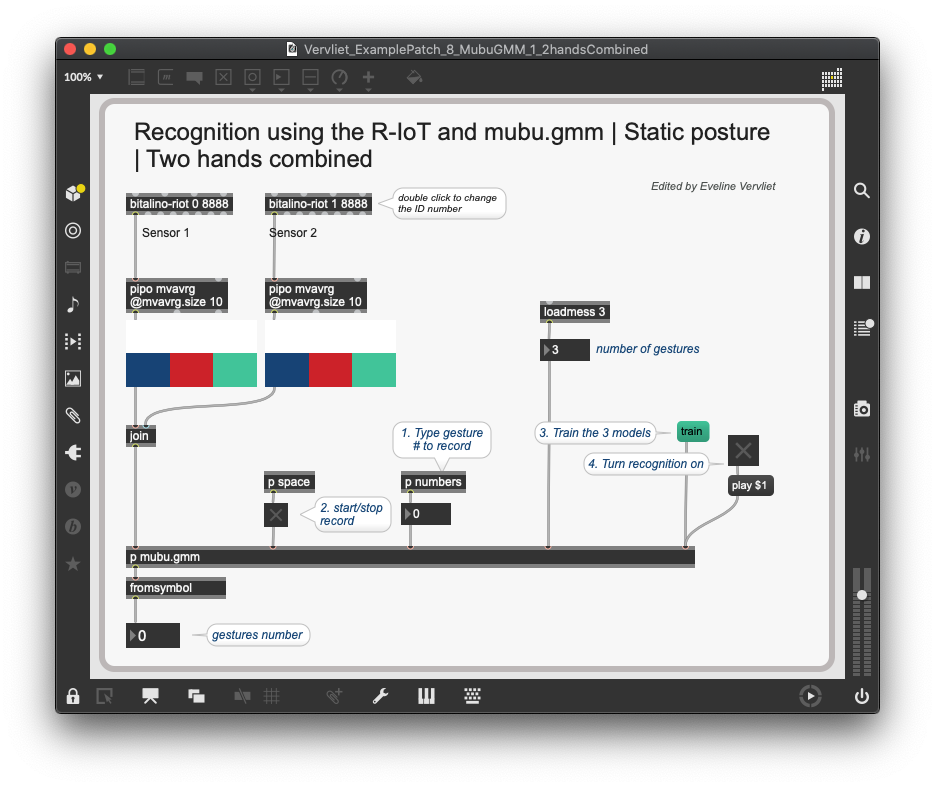
Detect static gestures with 2 hands combined
When training both hands combined, there are only a few changes we need to make to the patches for one hand.
First of all, we need a second [bitalino-riot] object. You can double click on the object to change the ID. Most likely, you’ll have chosen sensor 1 with ID 0 and sensor 2 with ID 1. The data from both sensors are joined in one list.
In the [p mubu.gmm] subpatch, you will have to change the @matrixcols parameter of the [mubu.record] object depending on the amount of values in the list. In the example, two accelerometer data lists with each 3 values were joined, thus we need 6 columns.
The rest of the process is exactly the same as in previous patches: we need to record two or more different static postures, train the model, and then click play to start the gesture detection.
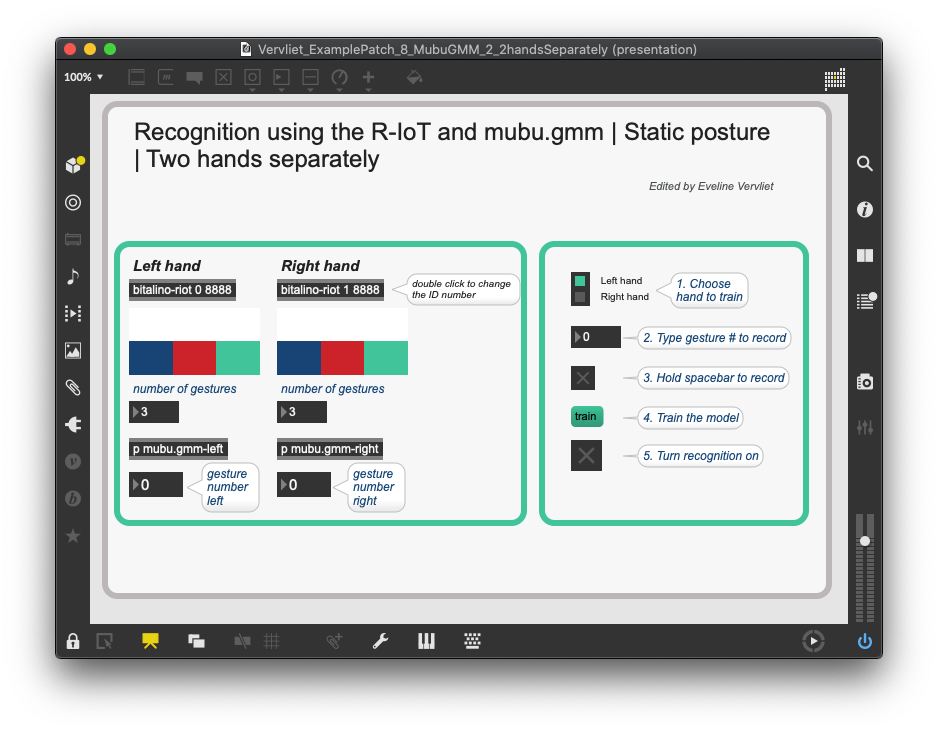
When training both hands separately, the training process becomes a bit more complex, although most steps remain the same. Now, there is a unique model for each hand, which has to be trained separately. You can see the models in the [p mubu.gmm-left] and [p mubu.gmm-right] subpatches. There is a switch object which routes the training data to the correct model.
In the above example, I personally found the training with both hands separate to be most efficient: even though the training process took slightly longer, the programming after that was much easier. Depending on your situation, you will have to decide which patch makes most sense to use. Experimentation can be a useful tool in determining this.
Detect dynamic gestures with 2 hands
The detection with both hands of dynamic gestures follow the same principles as the above examples. You can download the two Max patches here:
The mentioned tools can be used to detect ancillary gestures in musicians in real-time, which in turn could have an impact on a musical composition or improvisation. Ancillary gestures are „musician’s performance movements which are not directly related to the production or sustain of the sound“ (Lähdeoja et al.) but are believed to have an impact both in the sound production as well as in the perceived performative aspects. Wanderley also refers to this as ‘non-obvious performer gestures’.
In a following article, Marlon Schumacher worked with Wanderley on a framework for integrating gestures in computer-aided composition. The result is the Open Music library OM-Geste. This article is a helpful example of how the data can be used artistically.
Links to articles:
Marcelo M. Wanderley – Non-obvious Performer Gestures in Instrumental Musicdownload
O. Lähdeoja, M. M. Wanderley, J. Malloch – Instrument Augmentation using Ancillary Gestures for Subtle Sonic Effectsdownload
M. Schumacher, M. Wanderley – Integrating gesture data in computer-aided composition: A framework for representation, processing and mappingdownload
Detecting gestures in musicians has been a much-researched topic in the last decades. This folder holds several other articles on this topic that could interest.
Inspiriert vom „Infinite Bad Guy“ Projekt und all den sehr unterschiedlichen Versionen, wie manche Leute ihre Fantasie zu diesem Song beflügelt haben, dachte ich, vielleicht könnte ich auch damit experimentieren, eine sehr lockere, instrumentale Coverversion von Billie Eilish’s „Bad Guy“ zu erstellen.
Betreuer: Prof. Dr. Marlon Schumacher
Eine Studie von: Kaspars Jaudzems
Wintersemester 2021/22
Hochschule für Musik, Karlsruhe
Zur Studie:
Ursprünglich wollte ich mit 2 Audiodateien arbeiten, eine FFT-Analyse am Original durchführen und dessen Klanginhalt durch Inhalt aus der zweiten Datei „ersetzen“, lediglich basierend auf der Grundfrequenz. Nachdem ich jedoch einige Tests mit einigen Dateien durchgeführt hatte, kam ich zu dem Schluss, dass diese Art von Technik nicht so präzise ist, wie ich es gerne hätte. Daher habe ich mich entschieden, stattdessen eine MIDI-Datei als Ausgangspunkt zu verwenden.
Sowohl die erste als auch die zweite Version meines Stücks verwendeten nur 4 Samples. Die MIDI-Datei hat 2 Kanäle, daher wurden 2 Dateien zufällig für jede Note jedes Kanals ausgewählt. Das Sample wurde dann nach oben oder unten beschleunigt, um dem richtigen Tonhöhenintervall zu entsprechen, und zeitlich gestreckt, um es an die Notenlänge anzupassen.
Die zweite Version meines Stücks fügte zusätzlich einige Stereoeffekte hinzu, indem 20 zufällige Pannings für jede Datei vor-generiert wurden. Mit zufällig angewendeten Kammfiltern und Amplitudenvariationen wurde etwas mehr Nachhall und menschliches Gefühl erzeugt.
Akusmatische Studie Version 1
Akusmatische Studie Version 2
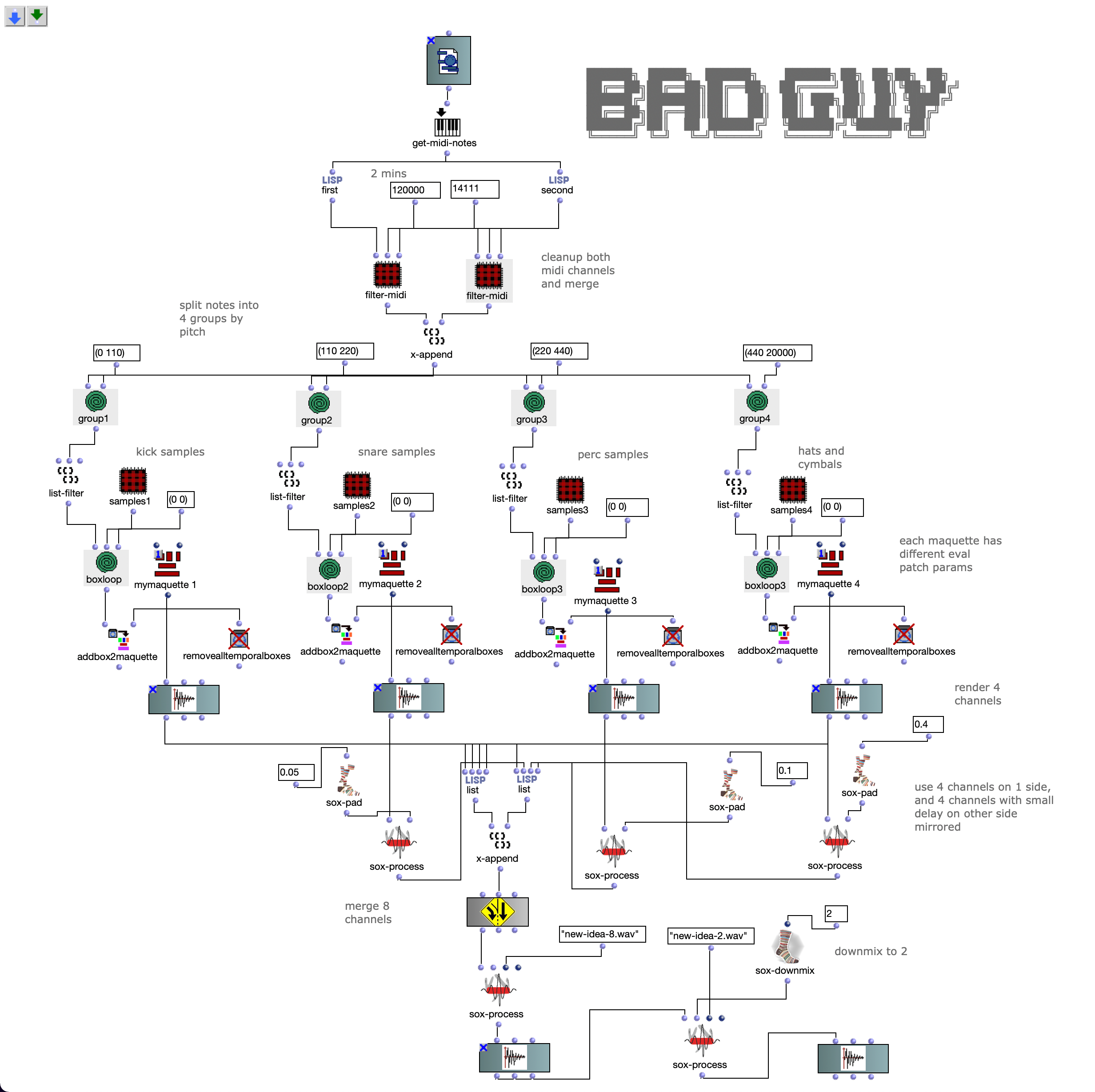
Die dritte Version war eine viel größere Änderung. Hier werden die Noten beider Kanäle zunächst nach Tonhöhe in 4 Gruppen eingeteilt. Jede Gruppe umfasst ungefähr eine Oktave in der MIDI-Datei.
Dann wird die erste Gruppe (tiefste Töne) auf 5 verschiedene Kick-Samples abgebildet, die zweite auf 6 Snares, die dritte auf perkussive Sounds wie Agogo, Conga, Clap und Cowbell und die vierte Gruppe auf Becken und Hats, wobei insgesamt etwa 20 Samples verwendet werden. Hier wird eine ähnliche Filter-und-Effektkette zur Stereoverbesserung verwendet, mit dem Unterschied, dass jeder Kanal fein abgestimmt ist. Die 4 resultierenden Audiodateien werden dann den 4 linken Audiokanälen zugeordnet, wobei die niedrigeren Frequenzen kanale zur Mitte und die höheren kanale zu den Seiten sortiert werden. Für die anderen 4 Kanäle werden dieselben Audiodateien verwendet, aber zusätzliche Verzögerungen werden angewendet, um Bewegung in das Mehrkanalerlebnis zu bringen.
Akusmatische Studie Version 3
Die 8-Kanal-Datei wurde auf 2 Kanäle in 2 Versionen heruntergemischt, einer mit der OM-SoX-Downmix-Funktion und der andere mit einem Binauralix-Setup mit 8 Lautsprechern.
Akusmatische Studie Version 3 – Binauralix render
Erweiterung der akousmatischen Studie – 3D 5th-order Ambisonics
Die Idee mit dieser Erweiterung war, ein kreatives 36-Kanal-Erlebnis desselben Stücks zu schaffen, also wurde als Ausgangspunkt Version 3 genommen, die nur 8 Kanäle hat.
Ausgangspunkt Version 3
Ich wollte etwas Einfaches machen, aber auch die 3D-Lautsprecherkonfiguration auf einer kreativen weise benutzen, um die Energie und Bewegung, die das Stück selbst bereits gewonnen hatte, noch mehr hervorzuheben. Natürlich kam mir die Idee in den Sinn, ein Signal als Quelle für die Modulation von 3D-Bewegung oder Energie zu verwenden. Aber ich hatte keine Ahnung wie…
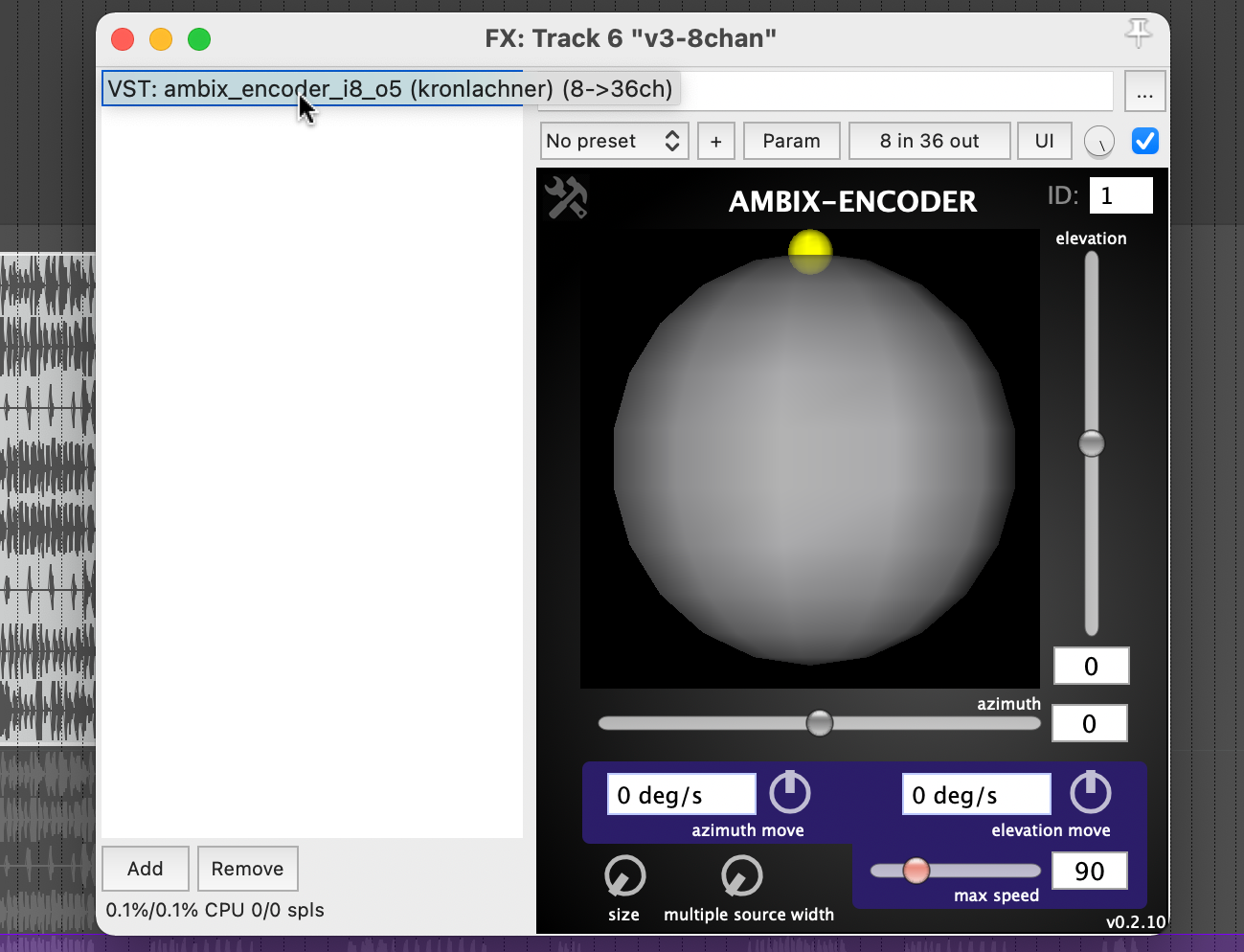
Plugin „ambix_encoder_i8_o5 (8 -> 36 chan)“
Bei der Recherche zur Ambix Ambisonic Plugin (VST) Suite bin ich auf das Plugin „ambix_encoder_i8_o5 (8 -> 36 chan)“ gestoßen. Dies schien aufgrund der übereinstimmenden Anzahl von Eingangs- und Ausgangskanälen perfekt zu passen. In Ambisonics wird Raum/Bewegung aus 2 Parametern übersetzt: Azimuth und Elevation. Energie hingegen kann in viele Parameter übersetzt werden, aber ich habe festgestellt, dass sie am besten mit dem Parameter Source Width ausgedrückt wird, weil er die 3D-Lautsprecherkonfiguration nutzt, um tatsächlich „nur“ die Energie zu erhöhen oder zu verringern.
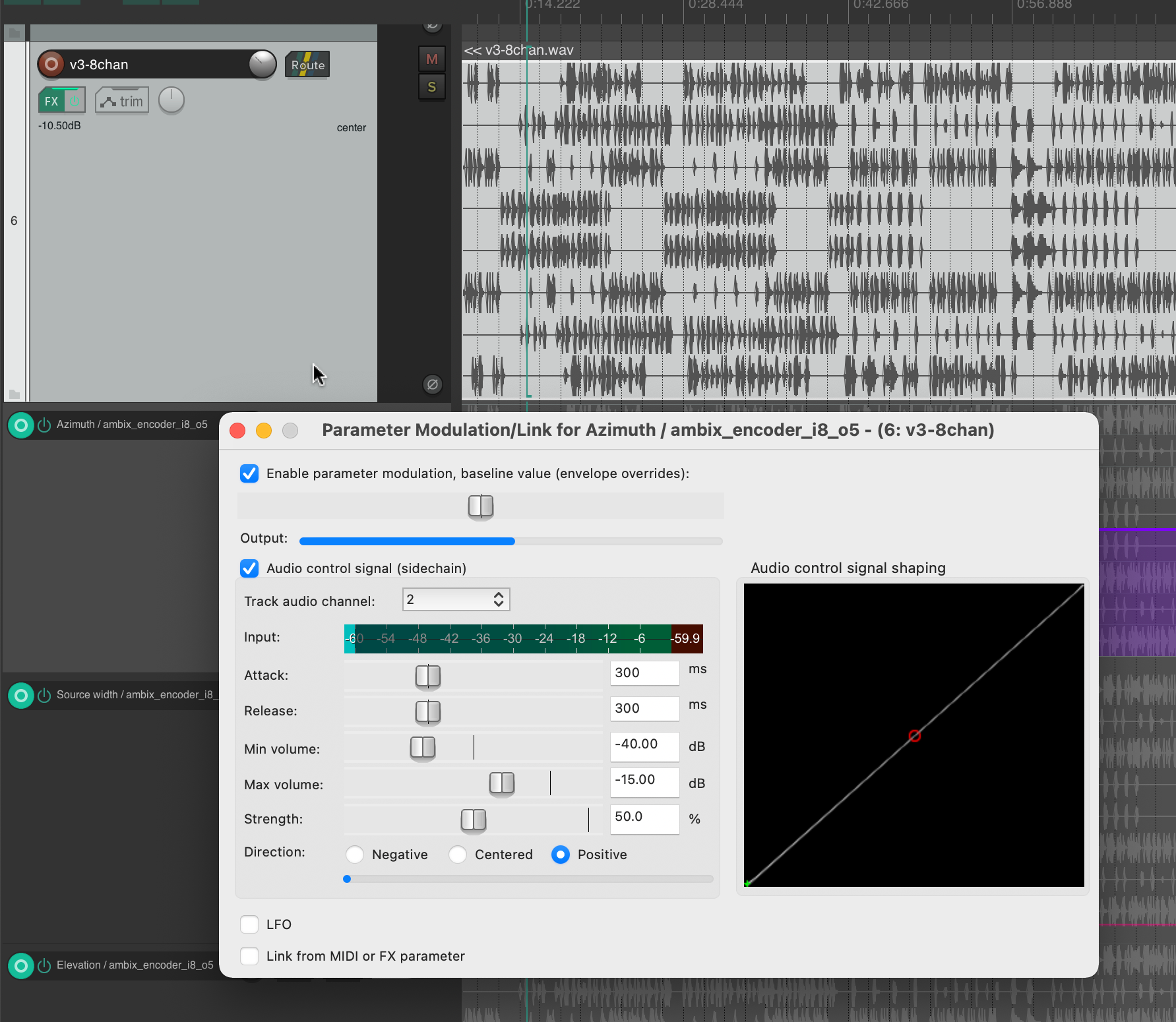
Da ich wusste, welche Parameter ich modulieren muss, begann ich damit zu experimentieren, verschiedene Spuren als Quelle zu verwenden. Ehrlich gesagt war ich sehr froh, dass das Plugin nicht nur sehr interessante Klangergebnisse lieferte, sondern auch visuelles Feedback in Echtzeit. Bei der Verwendung beider habe ich mich darauf konzentriert, ein gutes visuelles Feedback zu dem zu haben, was im Audiostück insgesamt vor sich geht.
Dies half mir, Kanal 2 für Azimuth, Kanal 3 für Source Width und Kanal 4 für Elevation auszuwählen. Wenn wir diese Kanäle auf die ursprüngliche Eingabe-Midi-Datei zurückverfolgen, können wir sehen, dass Kanal 2 Noten im Bereich von 110 bis 220 Hz, Kanal 3 Noten im Bereich von 220 bis 440 Hz und Kanal 4 Noten im Bereich von 440 bis 20000 Hz zugeordnet ist. Meiner Meinung nach hat diese Art der Trennung sehr gut funktioniert, auch weil die Sub-bass frequenzen (z. B. Kick) nicht moduliert wurden und auch nicht dafur gebraucht waren. Das bedeutete, dass der Hauptrhythmus des Stücks als separates Element bleiben konnte, ohne den Raum oder die Energiemodulationen zu beeinflussen, und ich denke, das hat das Stück irgendwie zusammengehalten.
Akusmatische Studie Version 4 – 36 channels, 3D 5th-order Ambisonics – Datei war zu groß zum Hochladen
In diesem Projekt entstand im Rahmen der Lehrveranstaltung „Studienprojekte Musikprogrammierung“ eine audio-only Augmented Reality Klanginstallation an der Hochschule für Musik Karlsruhe. Wichtig für den nachfolgenden Text ist die terminologische Abgrenzung zur Virtual Reality (kurz: VR), bei welcher der Benutzer komplett in die virtuelle Welt eintaucht. Bei der Augmented Reality (kurz: AR) handelt es sich um die Erweiterung der Realität durch das technische Hinzufügen von Information.
Motivation
Zum einen soll diese Klanginstallation einem gewissen künstlerischen Anspruch gerecht werden, zum anderen war auch mein persönliches Ziel dabei, den Teilnehmern das AR und besonders das auditive AR näher zu bringen und für diese neu Technik zu begeistern. Unter Augmented Reality wird leider sehr oft nur die visuelle Darstellung von Informationen verstanden, wie sie zum Beispiel bei Navigationssystemen oder Smartphone-Applikationen vorkommen. Allerdings ist es meiner Meinung nach wichtig die Menschen auch immer mehr für die auditive Erweiterung der Realität zu sensibilisieren. Ich bin der Überzeugung, dass diese Technik auch ein enormes Potential hat und bei der Aufmerksamkeit in der Öffentlichkeit, im Vergleich zum visuellen Augmented Reality, ein sehr großer Nachholbedarf besteht. Es gibt mittlerweile auch schon zahlreiche Anwendungsbereiche, in welchen der Nutzen des auditiven AR präsentiert werden konnte. Diese erstrecken sich sowohl über Bereiche, in welchen sich bereits viele Anwendung des visuellen AR vorfinden, wie z.B. der Bildung, Steigerung der Produktivität oder zu reinen Vergnügungszwecken als auch in Spezialbereichen wie der Medizin. So gab es bereits vor zehn Jahren Unternehmungen, mithilfe auditiver AR eine Erweiterung des Hörsinnes für Menschen mit Sehbehinderung zu kreieren. Dabei konnte durch Sonifikation von realen Objekten eine rein auditive Orientierungshilfe geschaffen werden.
Methodik
In diesem Projekt sollen Teilnehmer*innen sich frei in einem Raum, in welchem Gegenstände positioniert sind, bewegen können und obwohl diese in der Realität keine Klänge erzeugen, sollen die Teilnehmer*innen Klänge über Kopfhörer wahrnehmen können. In diesem Sinne also eine Erweiterung der Realität („augmented reality“), da mithilfe technischer Mittel Informationen in auditiver Form der Wirklichkeit hinzugefügt werden. Im Wesentlichen erstrecken sich die Bereiche für die Umsetzung zum einen auf die Positionsbestimmung der Person (Motion-Capture) und die Binauralisierung und zum anderen im künstlerischen Sinne auf die Gestaltung der Klang-Szene durch Positionierung und Synthese der Klänge.
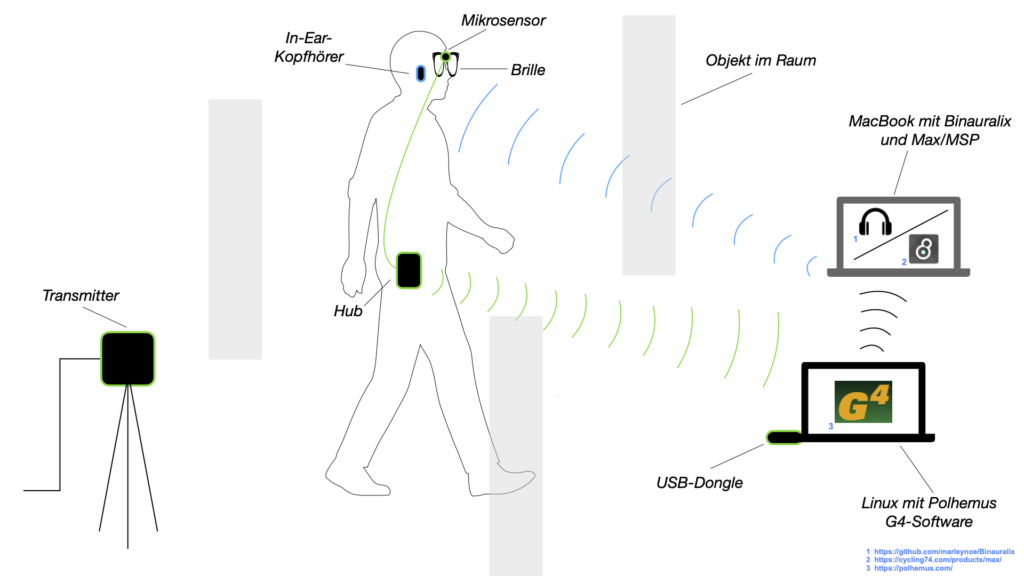
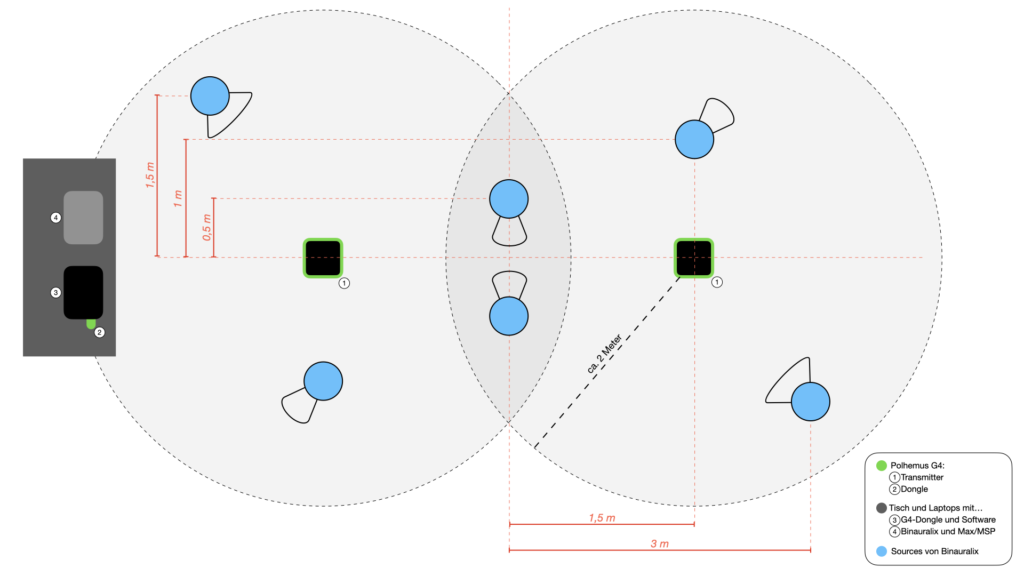
Abbildung 1
Das Motion-Capture wird in diesem Projekt mit dem Polhemus G4 System realisiert. Die Richtung- und Positionsbestimmung eines Micro-Sensors, welcher an einer vom Teilnehmer getragenen Brille befestigt wird, geschieht durch ein Magnetfeld, welches von zwei Transmittern erzeugt wird. Ein Hub, der über ein Kabel mit dem Micro-Sensor verbunden ist, sendet die Daten des Motion-Captures an einen USB-Dongle, der an einem Laptop angeschlossen ist. Diese Daten werden an einen weiteren Laptop gesendet, auf welchem zum einen die Binauralisierung geschieht und der zum anderen letztendlich mit den kabellosen Kopfhörern verbunden ist.
In Abbildung 2 kann man zwei der sechs Objekte in je einer Variante (Winkel von 45° und 90°) betrachten. In der nächsten Abbildung (Abb. 3) ist die Überbrille (Schutzbrille die auch über einer Brille getragen werden kann) zu sehen, welche in der Klanginstallation zum Einsatz kommt. Diese Brille verfügt über einen breiten Nasensteg, auf welchem der Micro-Sensor mit einem Micro-Mount von Polhemus befestigt ist.
Abbildung 2
Abbildung 3
Wie schon zuvor erläutert, müssen für den Aufbau der Klanginstallation auch diverse Entscheidung vor einem künstlerischen Aspekt getroffen werden. Dabei geht es um die Positionierung der Gegenstände / Klangquellen und die Klänge selbst.
Abbildung 4
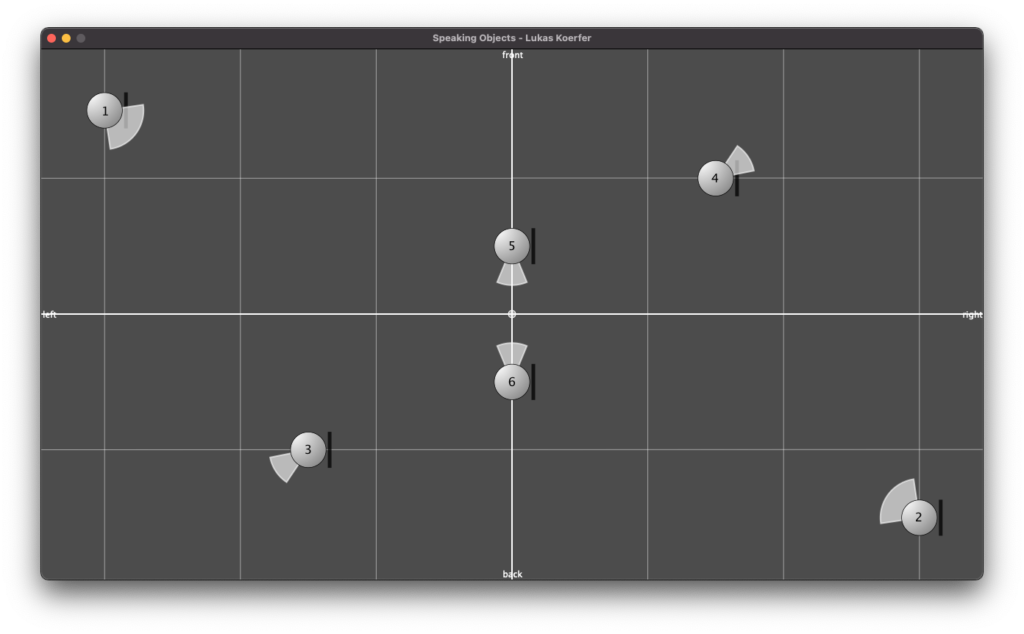
Abbildung 5
Die Abbildung 4 zeigt eine skizzierte Draufsicht des kompletten Aufbaus. Die sechs blau gefärbten Kreise markieren die Positionen der Gegenstände im Raum und natürlich gleichzeitig die der Klangquellen der Szene in Binauralix, welche in Abbildung 5 zu erkennen ist. Den farblosen Bereichen (in Abb. 4), im entweder 45° oder 90° Winkel, um die Klangquellen, können Richtung und Winkel der Quellen entnommen werden.
Die komplett kabellose Positionserfassung und Datenübertragung, ermöglicht den Teilnehmer*innen das uneingeschränkte Eintauchen in dieses Erlebnis der interaktiven realitätserweiternden Klangwelt. Die Klangsynthese wurde mithilfe der Software SuperCollider vorgenommen. Die Klänge entstanden hauptsächlich durch diverse Klopf- und Klickgeräusche, welche durch das SoundIn-Objekt aufgenommen wurden, und schließlich Veränderungen und Verfremdungen der Klänge durch Amplituden- und Frequenzmodulation und diverse Filter. Durch Audio-Routing der Klänge auf insgesamt 6 Ausgangskanäle und „s.record(numChannels:6)“ konnte ich in SuperCollider eine zweiminütige Mehrkanal Audio-Datei erstellen. Beim Abspielen der Datei in Binauralix wird automatisch der erste Kanal auf die Source eins, der zweite Kanal auf die Source 2 usw. gemappt.
Technische Umsetzung
Die technische Herausforderung für die Umsetzung des Projekts bestand zuerst grundlegen aus dem Empfangen und dem Umformatieren der Daten des Sensors, sodass diese in Binauralix verwertet werden können. Dabei bestand zunächst das Problem, dass Binauralix nur für MacOS und die Software für das Polhemus G4 System nur für Windows und Linux verfügbar sind. Da mir zu diesem Zeitpunkt neben einem MacBook auch ein Laptop mit Ubuntu Linux als Betriebssystem zur Verfügung stand, installierte ich die Polhemus Software für Linux.
Nach dem Bauen und Installieren der Polhemus G4 Software auf Linux, standen einem die fünf Anwendungen „G4DevCfg“, „CreateSrcCfg“, „g4term“, „g4display“ und „g4export“ zur Verfügung. Für mein Projekt muss zuerst mit „G4DevCfg“ alle verwendeten Devices miteinander verbunden und konfiguriert werden. Mit der Terminal-Anwendung „g4export“ kann man durch Angabe der zuvor erstellten Source-Configuration-File, der lokalen IP-Adresse des Empfänger-Gerätes und einem Port die Daten des Sensors über UDP übermitteln. Die Source-Configuration-File ist eine Datei, in welcher zum einen Position und Orientierung der Transmitter durch einen „Virtual Frame of Reference“ festgelegt werden und zum anderen Einstellungen zu Eintritts-Hemisphäre in das Magnetfeld, Floor Compansation und Source-Calibration-File vorgenommen werden können. Zum Ausführen der Anwendung müssen zu diesem Zeitpunkt die Transmitter und der Hub angeschaltet, der USB-Dongle am Laptop und der Sensor am Hub angeschlossen und der Hub mit dem USB-Dongle verbunden sein. Wenn sich nun das MacBook im selben Netzwerk wie der Linux-Laptop befindet, kann mit der Angabe des zuvor genutzten Ports die Daten empfangen werden. Dies geschieht bei meiner Klanginstallation in einem selbst erstellen MaxMSP-Patch.
Abbildung 6
In dieser Anwendung muss zuerst auf der linken Seite der passende Port gewählt werden. Sobald die Verbindung steht und die Nachrichten ankommen, kann man diese unter dem Auswahlfeld in der raw-Form betrachten. Die sechs Werte, die oben im mittleren Bereich der Anwendung zu sehen sind, sind die aus der rohen Nachricht herausgetrennten Werte für die Position und Orientierung. In dem Aktionsfeld darunter können nun finale Einstellung für die richtige Kalibrierung vorgenommen werden. Darüber hinaus gibt es auch noch die Möglichkeit die Achsen individuell zu spiegeln oder den Yaw-Wert zu verändern, falls unerwartete Probleme bei der Inbetriebnahme der Klanginstallation aufkommen sollten. Nachdem die Werte in Nachrichten formatiert wurden, die von Binauralix verwendet werden können (zu sehen rechts unten in der Anwendung), werden diese an Binauralix gesendet.
Das folgenden Videos bieten einen Blick auf die Szene in Binauralix und einen Höreindruck, während sich der Listener — gesteuert von den Sensor-Daten — durch die Szene bewegt.
Vergangene Vorstellungen der Klanginstallation
Die Klanginstallation als Beitrag im Rahmen der EFFEKTE-Vortragsreihe des Wissenschaftsbüro-Karlsruhe
Die Klanginstallation als Gegenstand eines Workshops für die Kulturakademie an der HfM-Karlsruhe
Im folgenden möchte ich einen Einblick in die künstlerische und technische Entwicklung meines Stückes „Warten auf die Nacht“ geben. Dieser Beitrag wird fortlaufend aktualisiert und wird so den Entwicklungsprozess dokumentieren.
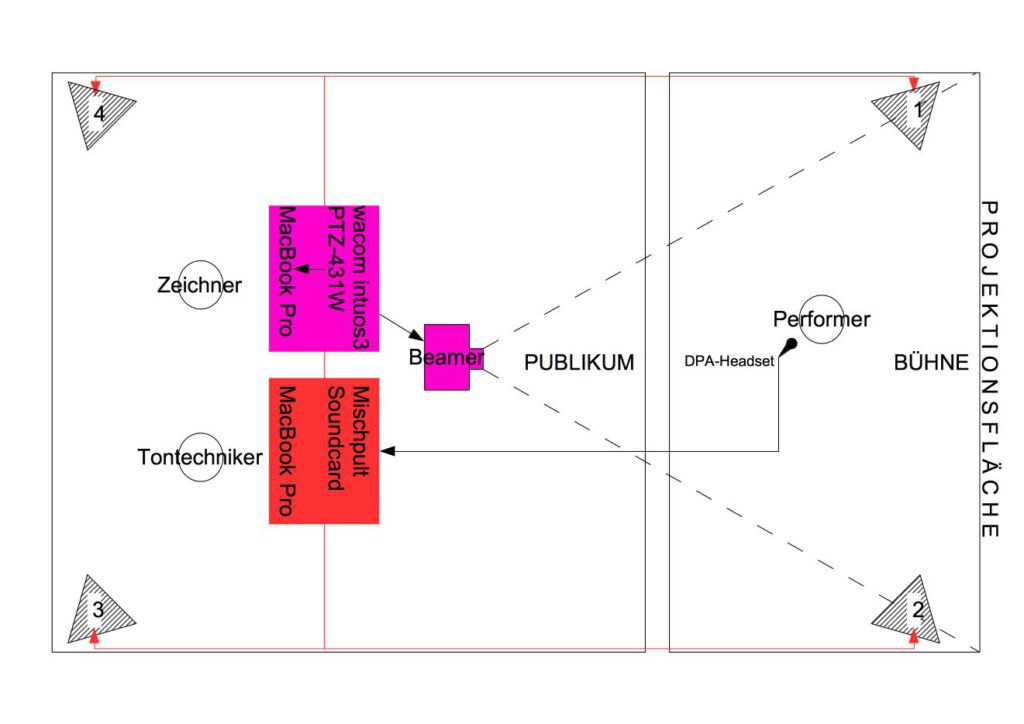
Das Stück soll von einer Performerin und einer Zeichnerin ausgeführt werden.
Technischer Bericht
Setup
Auf der Bühne steht die Performerin. Der Beamer muss so positioniert werden, dass das Bild über die Performerin hinweg auf die Projektionsfläche geworfen wird. Es sollte kein Schattenwurf der Performerin entstehen.