Abstract:
Inspired by the “Infinite Bad Guy” project, and all the very different versions of how some people have fueled their imaginations on that song, I thought maybe I could also experiment with creating a very loose, instrumental cover version of Billie Eilish’s “Bad Guy”.
Supervisor: Prof. Dr. Marlon Schumacher
A study by: Kaspars Jaudzems
Winter semester 2021/22
University of Music, Karlsruhe
To the study:
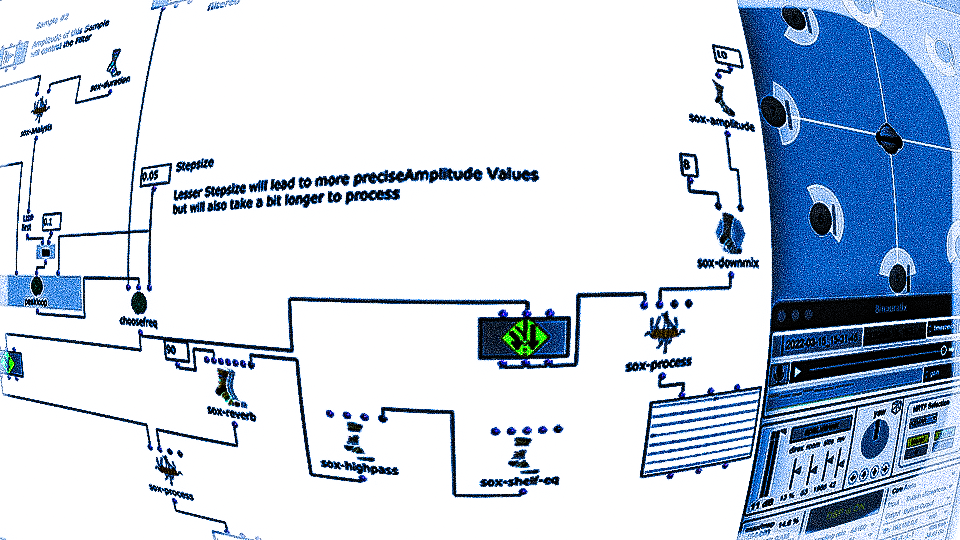
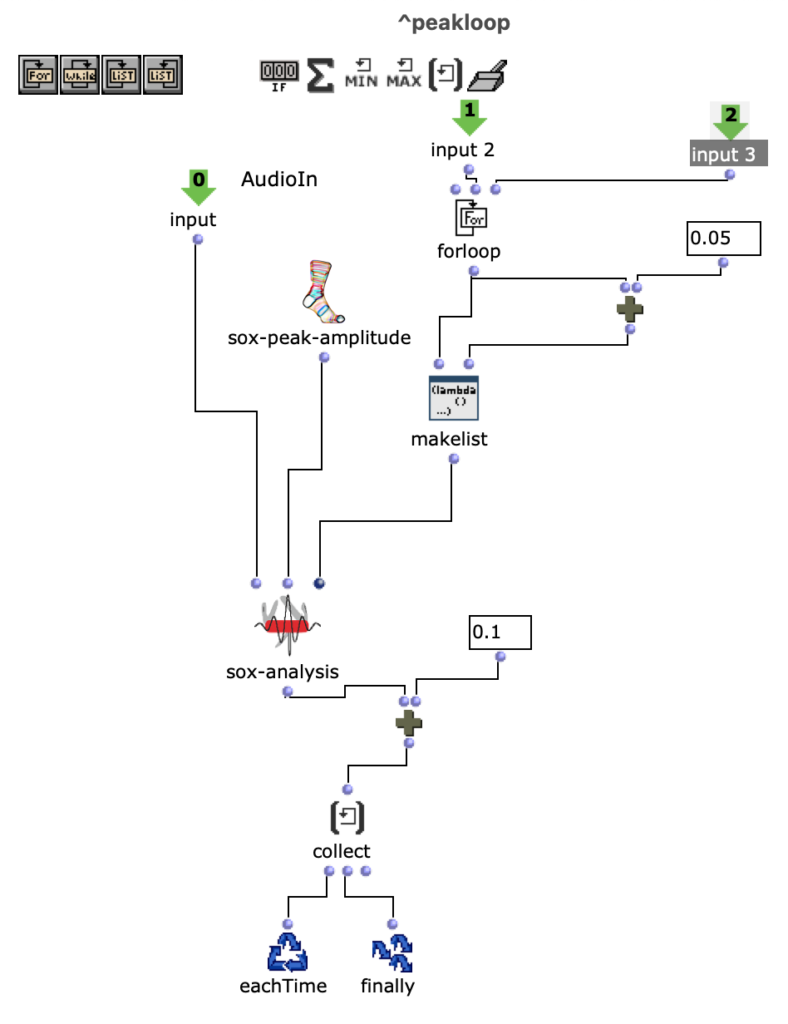
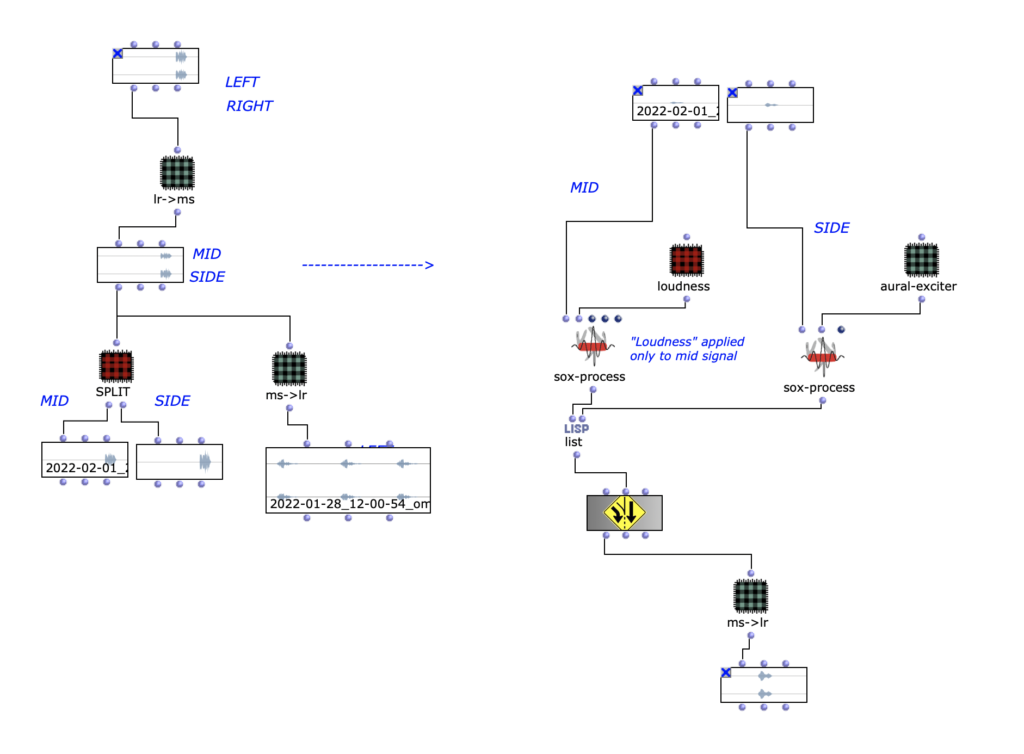
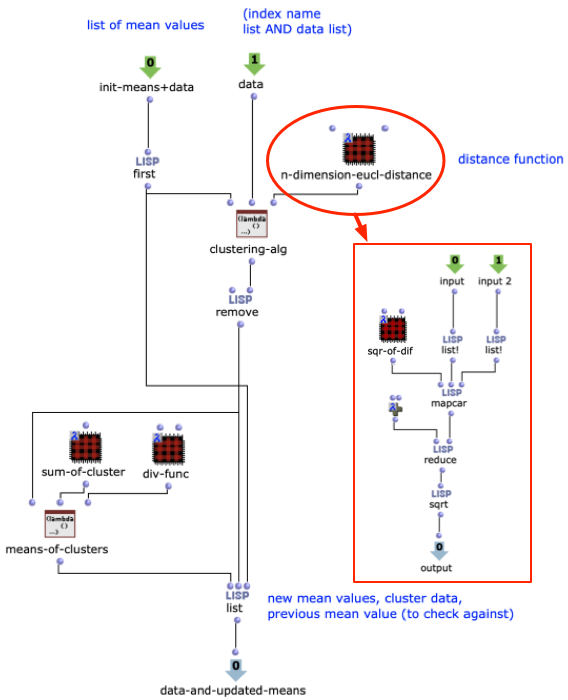
Originally, I wanted to work with 2 audio files, perform an FFT analysis on the original and “replace” its sound content with content from the second file, based only on the fundamental frequency. However, after doing some tests with a few files, I came to the conclusion that this kind of technique is not as accurate as I would like it to be. So I decided to use a MIDI file as a starting point instead.
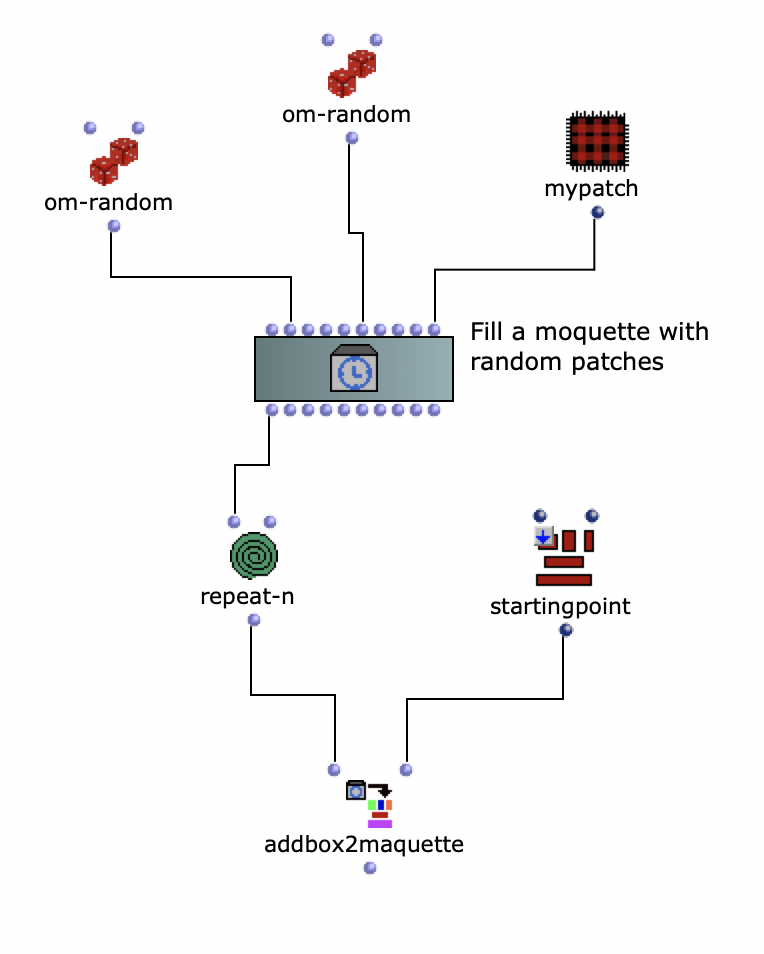
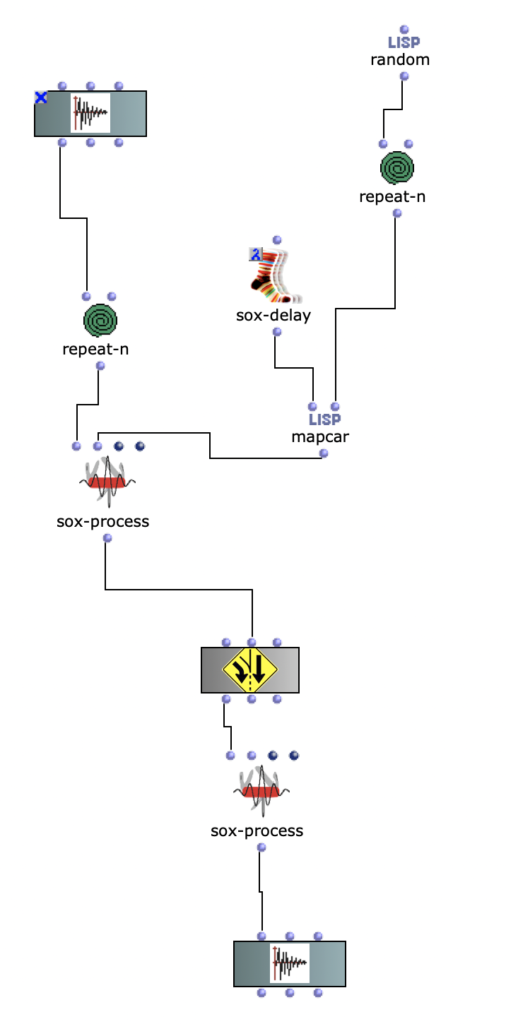
Both the first and second versions of my piece only used 4 samples. The MIDI file has 2 channels, so 2 files were randomly selected for each note of each channel. The sample was then sped up or down to match the correct pitch interval and stretched in time to match the note length.
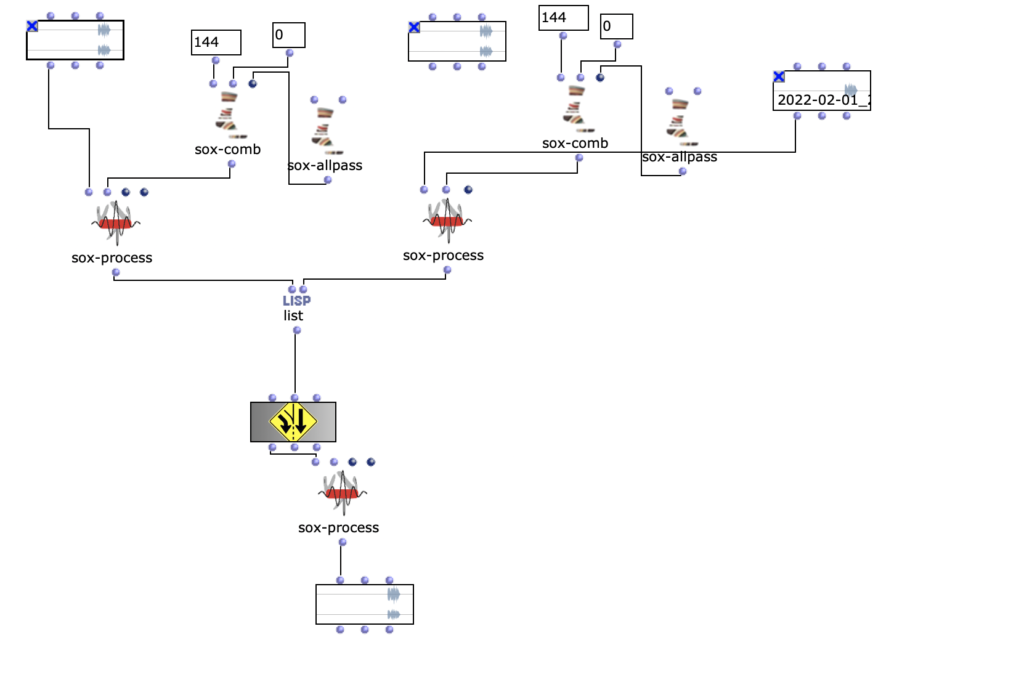
The second version of my piece added some additional stereo effects by pre-generating 20 random pannings for each file. With randomly applied comb filters and amplitude variations, a bit more reverb and human feel was created.
Acoustic study version 1
Acousmatic study version 2
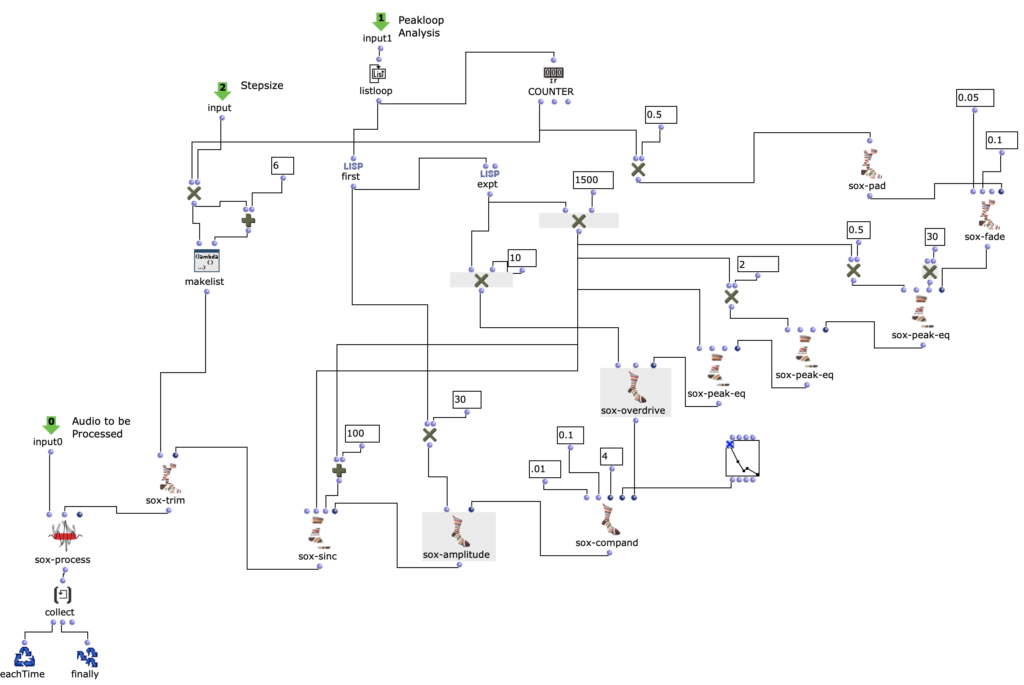
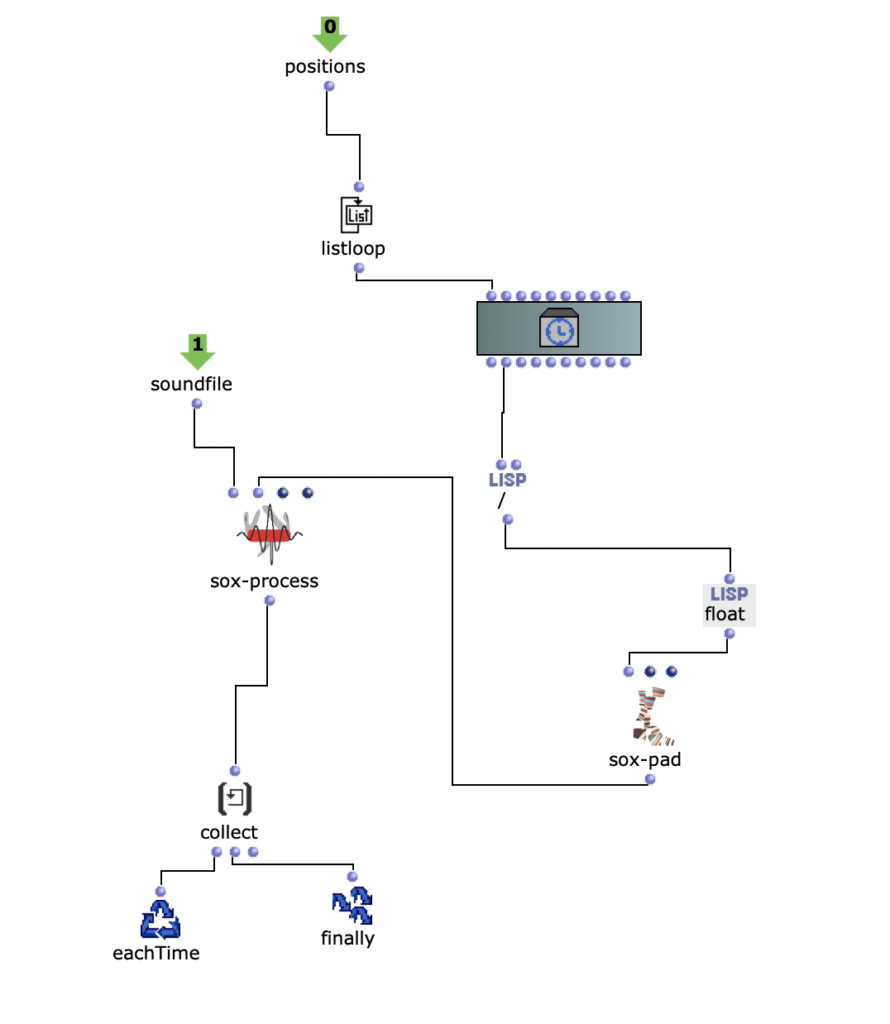
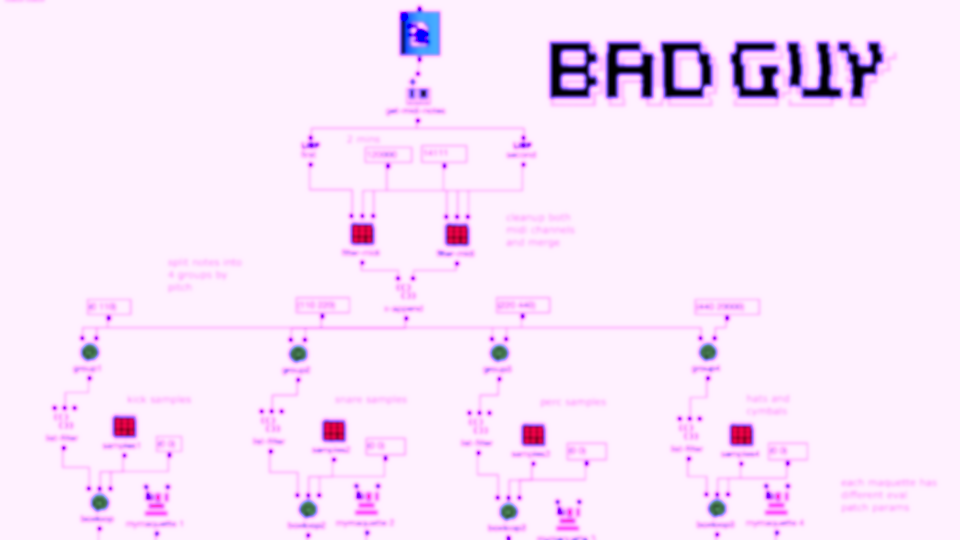
The third version was a much bigger change. Here the notes of both channels are first divided into 4 groups according to pitch. Each group covers approximately one octave in the MIDI file.
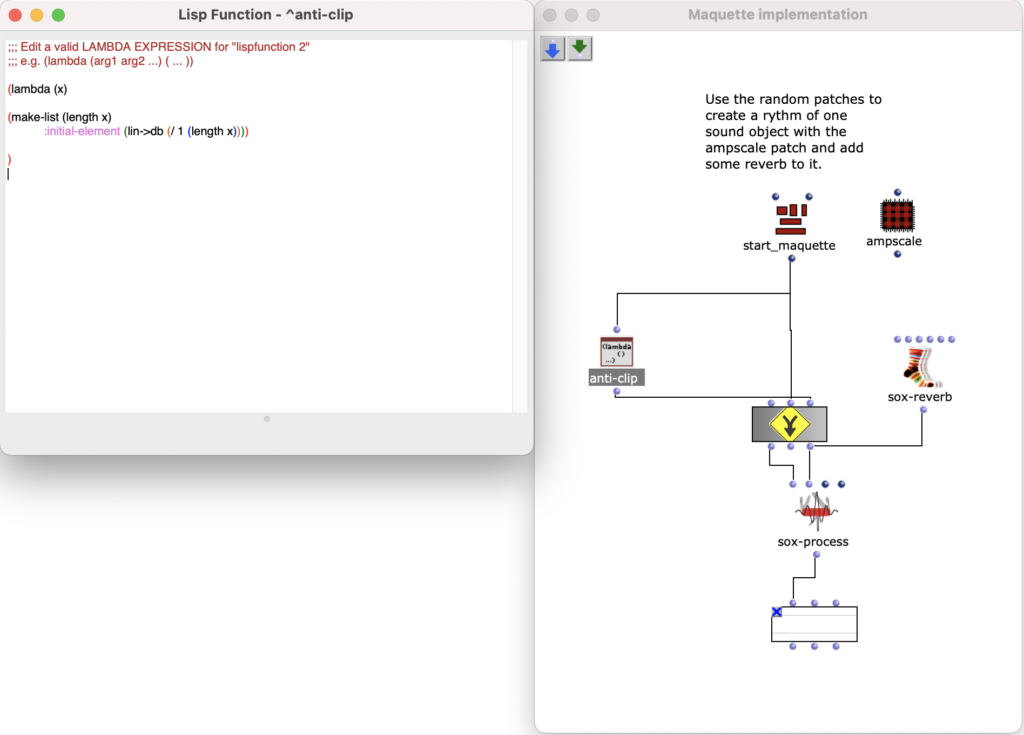
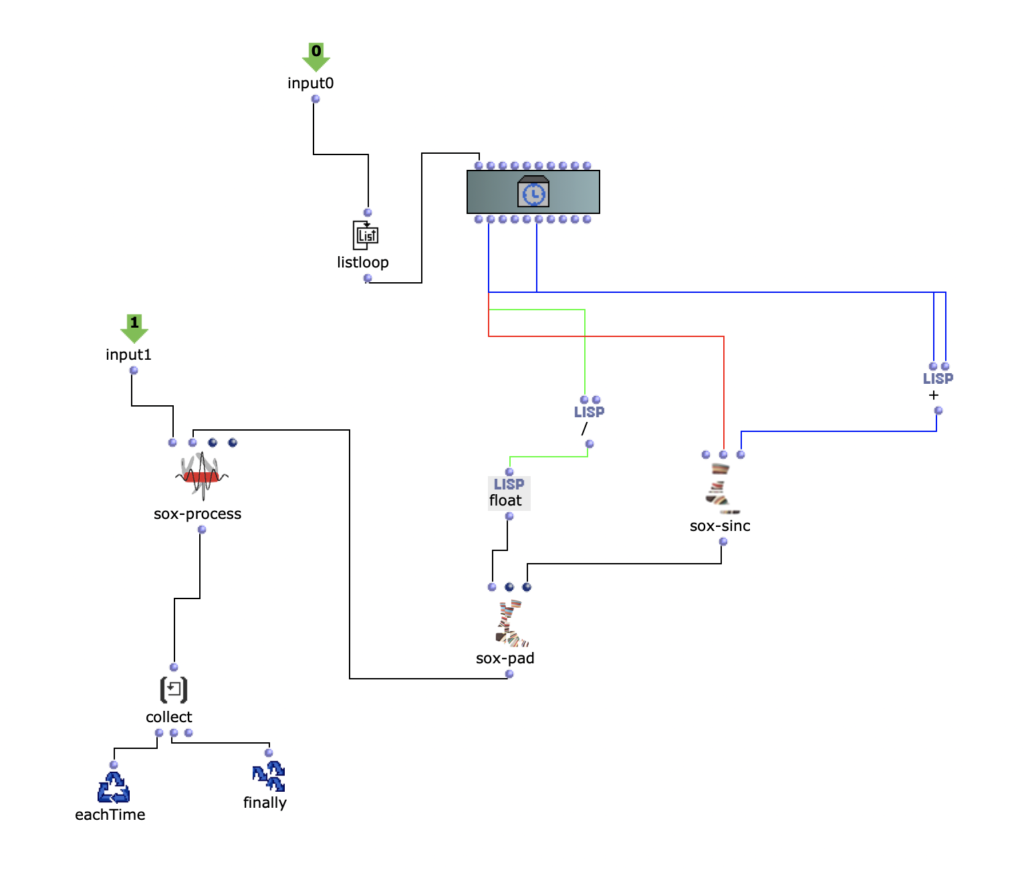
Then the first group (lowest notes) is mapped to 5 different kick samples, the second to 6 snares, the third to percussive sounds such as agogo, conga, clap and cowbell and the fourth group to cymbals and hats, using about 20 samples in total. A similar filter and effect chain is used here for stereo enhancement, with the difference that each channel is finely tuned. The 4 resulting audio files are then assigned to the 4 left audio channels, with the lower frequency channels sorted to the center and the higher frequency channels sorted to the sides. The same audio files are used for the other 4 channels, but additional delays are applied to add movement to the multi-channel experience.
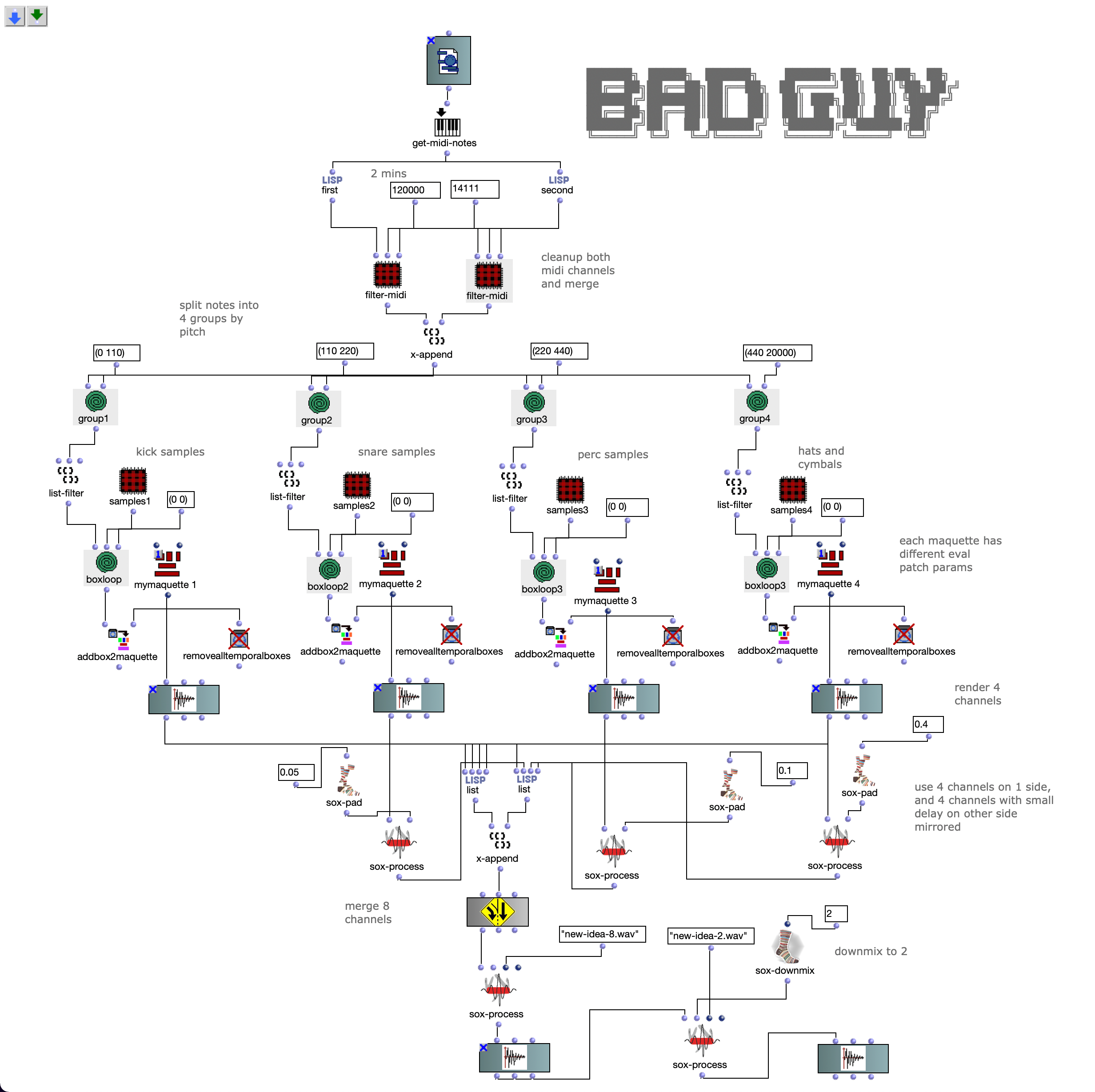
Acousmatic study version 3
The 8-channel file was downmixed to 2 channels in 2 versions, one with the OM-SoX downmix function and the other with a Binauralix setup with 8 speakers.
Acousmatic study version 3 – Binauralix render
Extension of the acousmatic study – 3D 5th-order Ambisonics
The idea with this extension was to create a 36-channel creative experience of the same piece, so the starting point was version 3, which only has 8 channels.
Starting point version 3
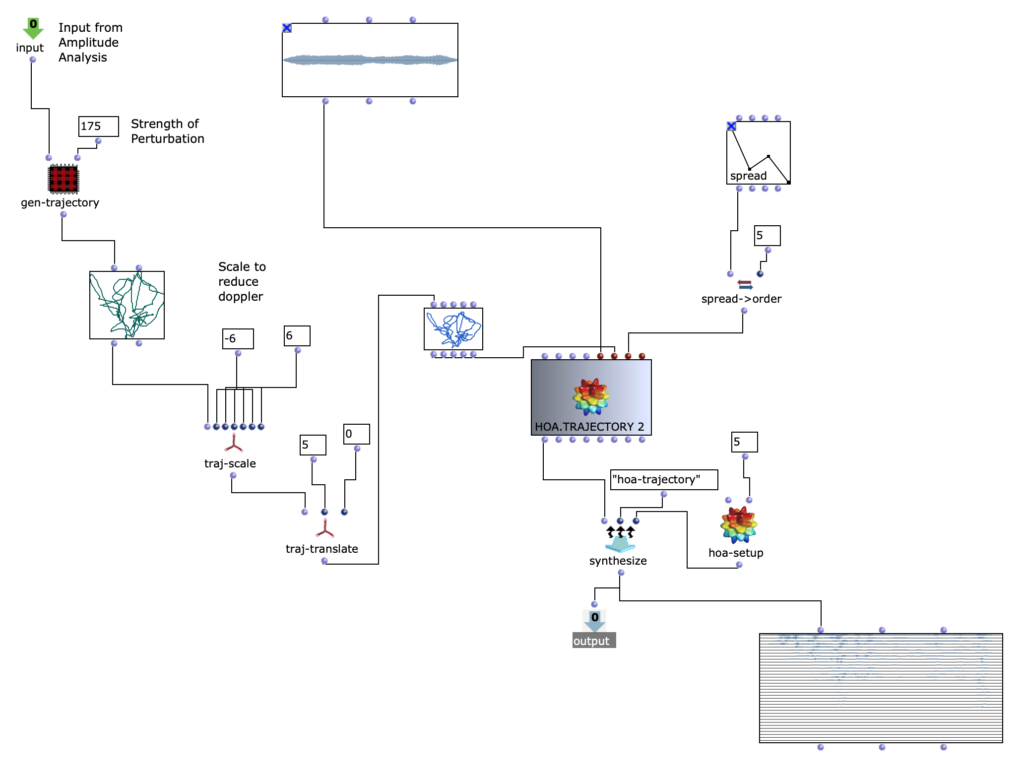
I wanted to do something simple, but also use the 3D speaker configuration in a creative way to further emphasize the energy and movement that the piece itself had already gained. Of course, the idea of using a signal as a source for modulating 3D movement or energy came to mind. But I had no idea how…
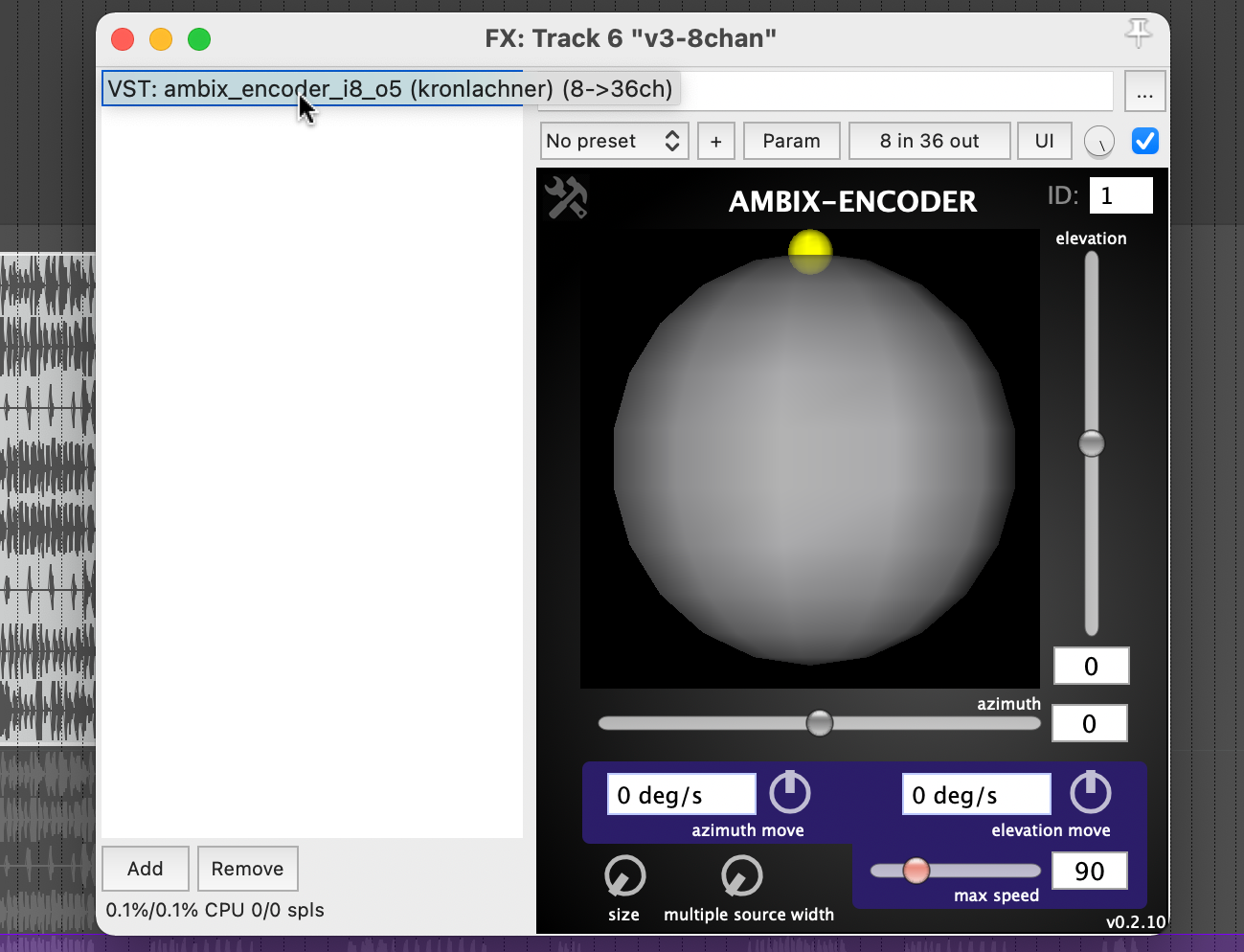
Plugin “ambix_encoder_i8_o5 (8 -> 36 chan)”
While researching the Ambix Ambisonic Plugin (VST) Suite, I came across the plugin “ambix_encoder_i8_o5 (8 -> 36 chan)”. This seemed to fit perfectly due to the matching number of input and output channels. In Ambisonics, space/motion is translated from 2 parameters: Azimuth and Elevation. Energy, on the other hand, can be translated into many parameters, but I found that it is best expressed with the Source Width parameter because it uses the 3D speaker configuration to actually “just” increase or decrease the energy.
Knowing which parameters to modulate, I started experimenting with using different tracks as the source. To be honest, I was very happy that the plugin not only provided very interesting sound results, but also visual feedback in real time. When using both, I focused on having good visual feedback on what was going on in the audio piece as a whole.
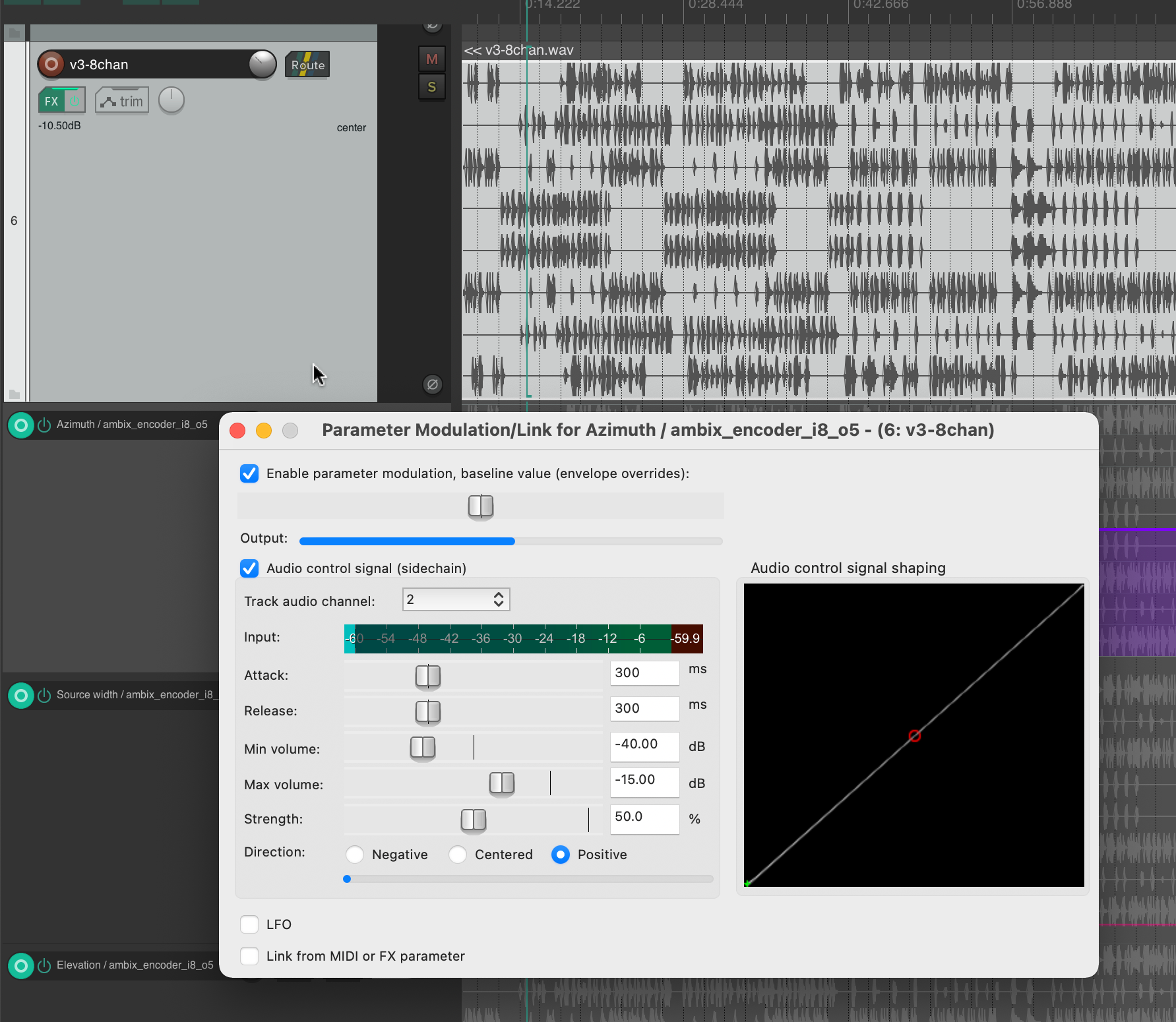
Channel 2 as modulation source for azimuth
This helped me to select channel 2 for Azimuth, channel 3 for Source Width and channel 4 for Elevation. If we trace these channels back to the original input midi file, we can see that channel 2 is assigned notes in the range of 110 to 220 Hz, channel 3 notes in the range of 220 to 440 Hz and channel 4 notes in the range of 440 to 20000 Hz. In my opinion, this type of separation worked very well, also because the sub-bass frequencies (e.g. kick) were not modulated and were not needed for this. This meant that the main rhythm of the piece could remain as a separate element without affecting the space or the energy modulations, and I think that somehow held the piece together.
Acousmatic study version 4 – 36 channels, 3D 5th-order Ambisonics – file was too big to upload
Acoustic study version 4 – Binaural render