Abstract: Dieses Abschlussprojekt entstand zum Ende des Wintersemesters 2023/24 im Rahmen der Lehrveranstaltung „Symbolische Klangverarbeitung und Analyse/Synthese“ des MA Musikinformatik. Hierbei wurde in dem Programm OpenMusic mithilfe der Library OM-SoX und des Verfahrens der Wellenfeldsynthese eine Anwendung zur Klangverräumlichung erarbeitet.
Verantwortliche: Lukas Körfer
Wellenfeldsynthese
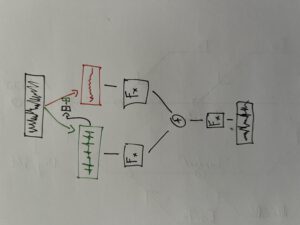
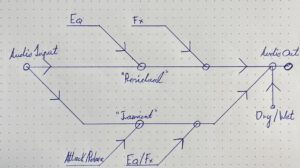
Bei der Wellenfeldsynthese (kurz: WFS) handelt es sich um das Verräumlichen von virtuellen Klangquellen mithilfe eines Loudspeaker-Arrays. Bei dieser fortschrittlichen Audiotechnologie wird also versucht, Klänge so zu reproduzieren, dass sie den Eindruck erwecken, dass sie von einer bestimmten Position im Raum kommen. Das gelingt durch die Erzeugung eines Wellenfeldes, welches aus einer Vielzahl von einzelnen Schallquellen besteht, die in einer Art synchronisiert werden, so dass eine kohärente Schallwelle entsteht, mit welcher es möglich sein soll, eine virtuelle Klangquelle im Raum lokalisieren zu können.
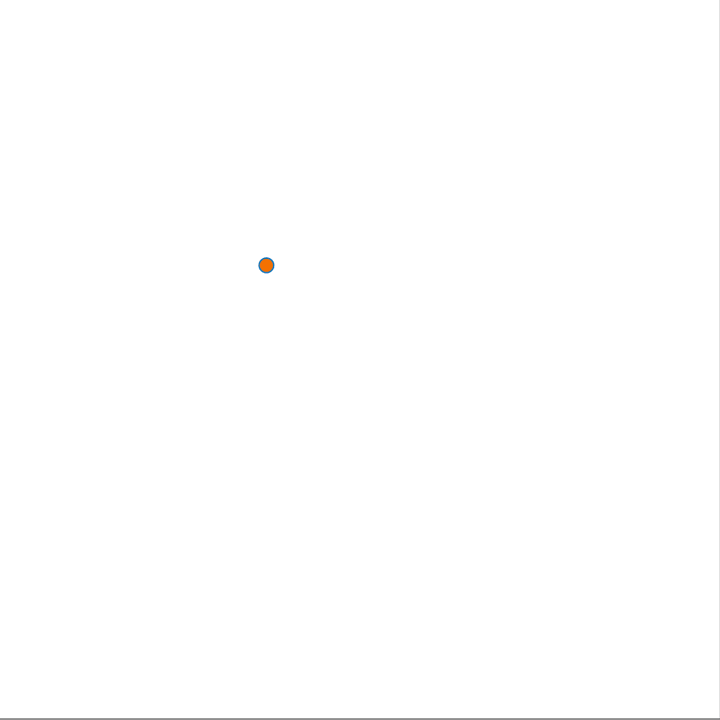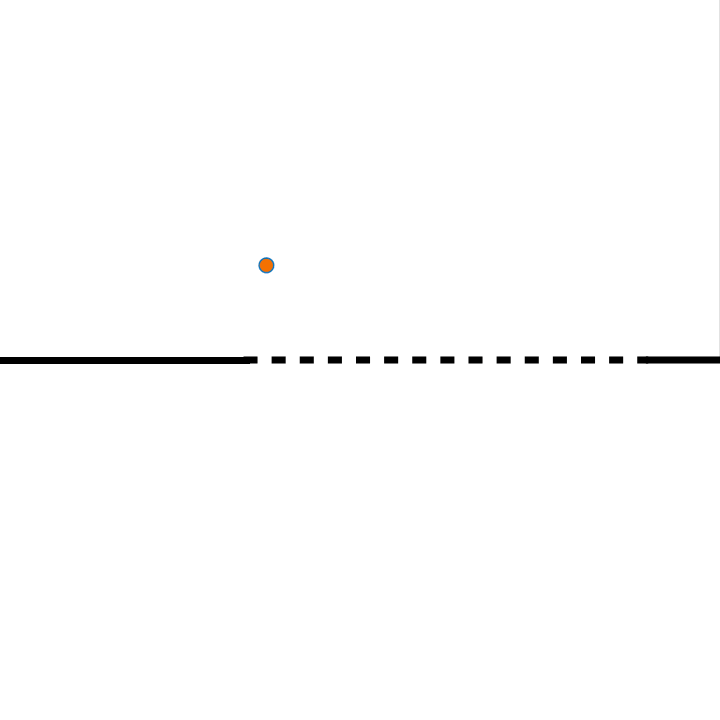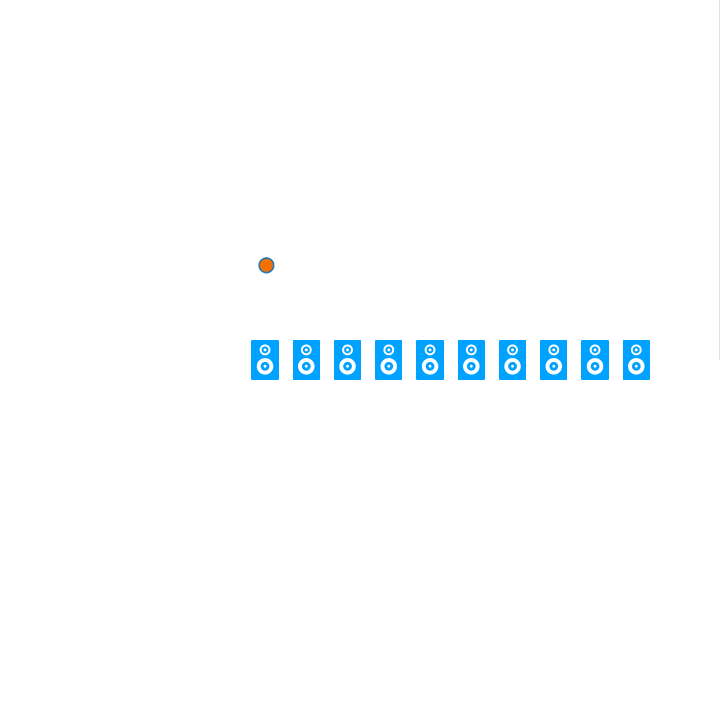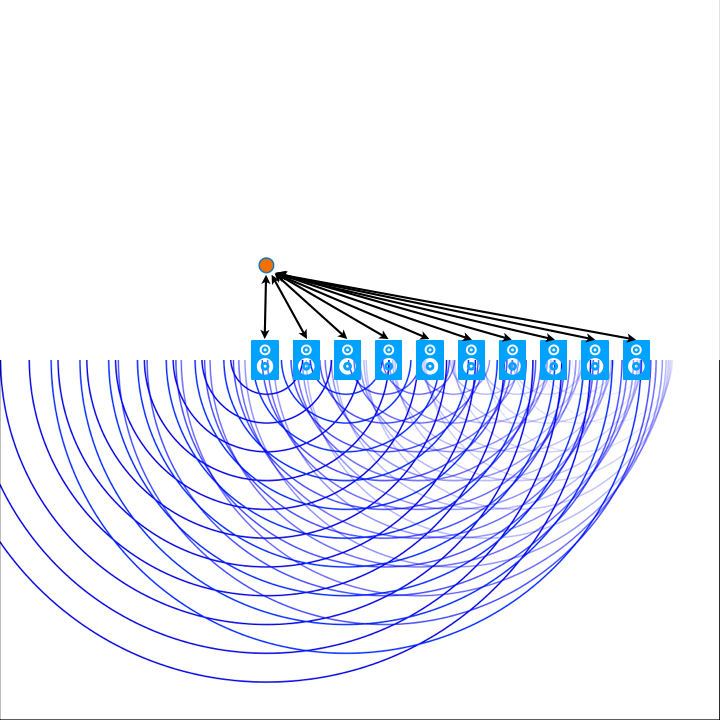
Zum besseren Verständnis der Funktionsweise von WFS kann man sich dem Thema über das physikalische Phänomen von Interferenzmusterbildung hinter einem Hindernis mit Öffnungen nähern. Wenn eine Welle auf einen oder mehrere Schlitze trifft, wird sie durch die Öffnungen hindurchgebeugt und breitet sich hinter dem Hindernis aus. Dies führt zur Bildung eines Musters von Welleninterferenz auf der anderen Seite des Hindernisses. In ähnlicher Weise nutzt die Wellenfeldsynthese ein Array von Lautsprechern, um eine kohärente Schallwelle zu erzeugen. Dafür muss eine präzise Berechnung und Steuerung der Phasen- und Amplitudenverhältnisse der Schallwellen, die von jedem einzelnen Lautsprecher ausgehen, vorgenommen werden. Diese Berechnungen sind abhängig von den Abständen jedes einzelnen Lautsprechers im Array relativ zur Position im Raum der jeweiligen virtuellen Klangquelle.
Projektbeschreibung
Für dieses Projekt sollte nun ein Programm entstehen, mit dem allgemeinen Ziel, durch gewissen Einfluss und Anpassungen eines Anwenders letztendlich eine Mehrkanal-Audiodatei zu erhalten, die zur Wellenfeldsynthese mit einem Loudspeaker-Array verwendet werden kann. Dafür musste zunächst konzipiert werden, welche Parameter vom Anwender des Programms gesetzt und beeinflusst werden sollen.
User-Input
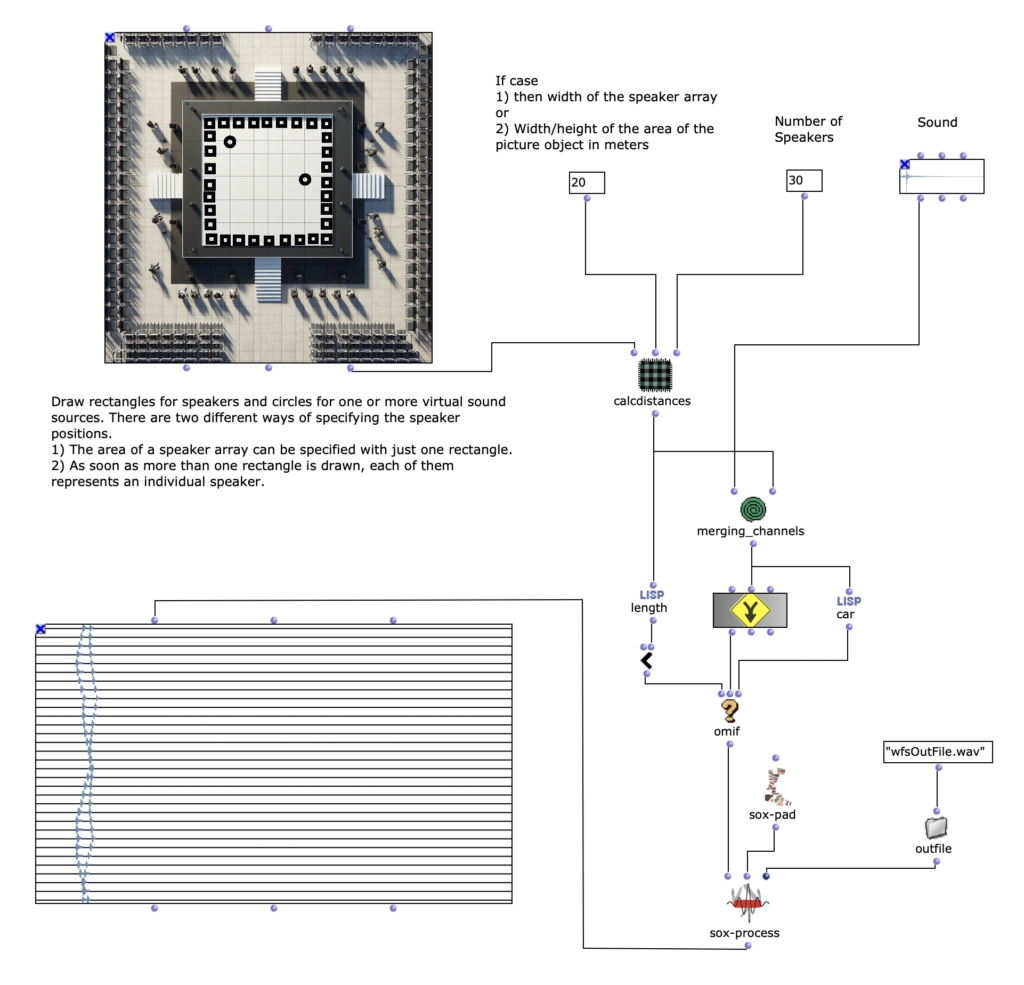
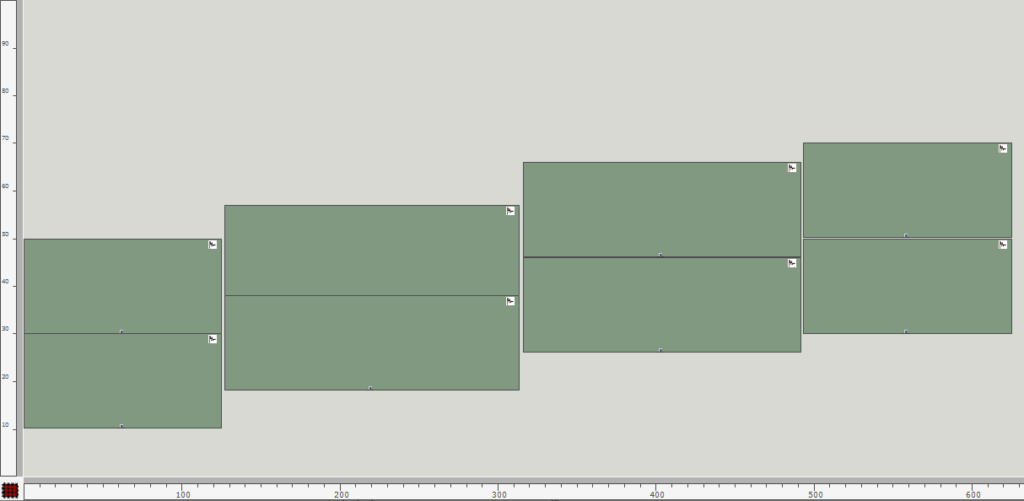
Neben der Audiofile, welche zur Verräumlichung verwendet werden sollte, muss durch den Anwender einerseits gewisse Angaben zum Loudspeaker-Array und andererseits die Position oder Positionen einer oder mehrerer virtueller Klangquellen relativ zum Loudspeaker-Array angegeben werden. Um eine möglichst einfache und intuitive Konfiguration des Programms zu ermöglichen, habe ich mich dazu entschieden, dafür hauptsächlich ein Picture-Objekt zu verwenden, in welchem der Aufbau aufgezeichnet werden kann. Durch das Zeichnen eines Rechtecks können die Positionen der Loudspeaker und mit Kreisen die der virtuellen Klangquellen angegeben werden. Es kann dabei ein oder mehrere Kreise gezeichnet werden, wobei jeder Kreis eine Klangquelle repräsentiert. Die Angabe der Loudspeaker ist durch zwei unterschiedliche Weisen möglich. Wenn nur ein einziges Rechteck im Picture-Objekt gezeichnet ist, so stellt dieses den Bereich eines Loudspeaker-Arrays dar. Um im nächsten Schritt des Programms die konkreten Positionen der einzelnen Loudspeaker ermitteln zu können, sind ihr zusätzlich noch zwei weitere Angaben nötig. Das ist zum einen die Länge des Loudspeaker-Arrays in Metern; damit wird gleichzeitig der Maßstab für den kompletten gezeichneten Aufbau beeinflusst. Und zum anderen muss die Anzahl der Loudspeaker im gezeichneten Bereich angegeben werden. Sobald mehr als ein Rechteck vom Anwender angegeben sind, steht jedes einzelne Rechteck für einen individuellen Loudspeaker. Um bei dieser Variante einen Maßstab für den gezeichneten Aufbau festlegen zu können – was vorher mit der Angabe der Länge des Loudspeaker-Arrays möglich war – kann nun die Breite / Höhe vom Bereich des kompletten Picture-Objekts angegeben werden. Mit der ersten Variante, dass das Loudspeaker-Array lediglich mit einem Rechteck gezeichnet werden kann, wird zwar die Anwendung deutlich unkomplizierter, setzt allerdings auch voraus, dass die Loudspeaker linear und mit einem gleichmäßigen Abstand zueinander aufgebaut sind.
Distanzen berechnen
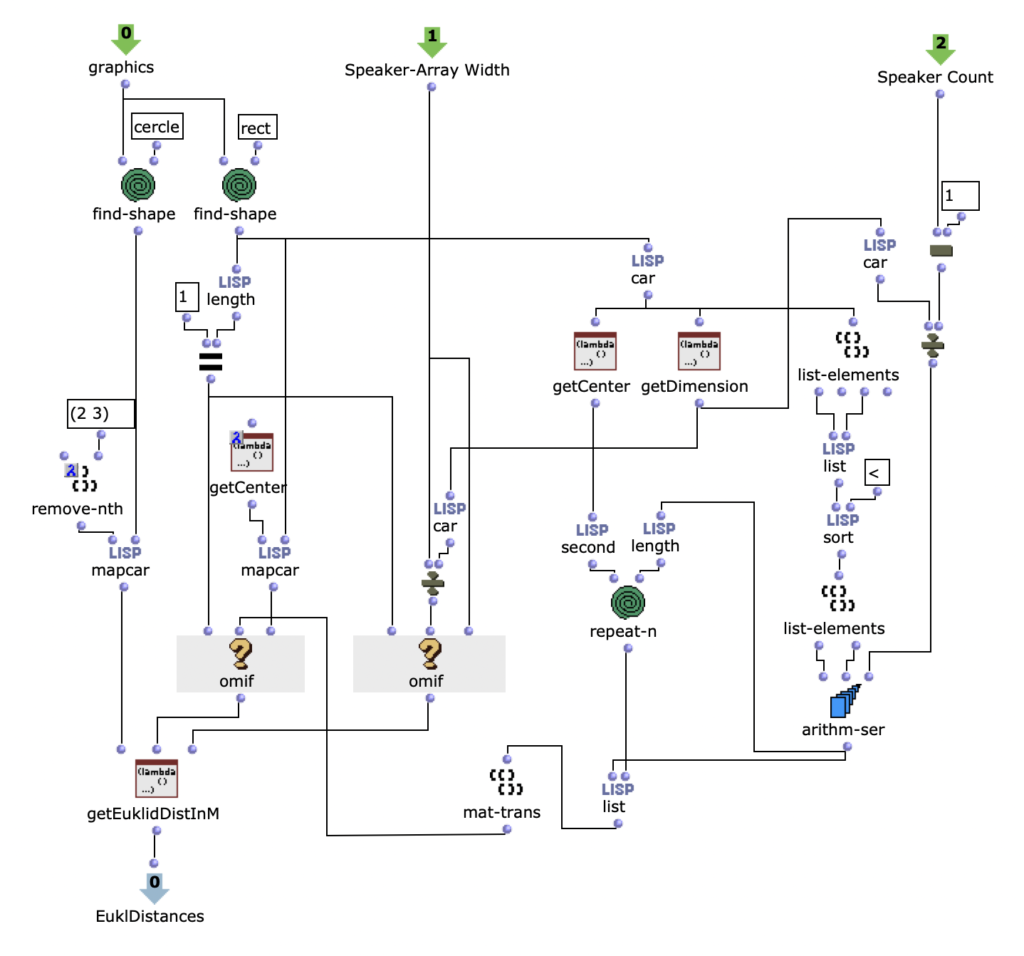
Nach dem Auslesen aller Grafiken des Picture-Objekts müssen diese für die Weiterverarbeitung in Rechteck und Kreise aufgeteilt werden. Falls nur ein Rechteck gefunden wird, kann mit der Position und Dimension des Rechtecks und der beiden Angaben zu Länge und Anzahl des Loudspeaker-Arrays, zunächst die Position jedes einzelnen Loudspeakers innerhalb des Arrays in Metern ermittelt werden. Wenn es mehrere Rechtecke sind, ist dieser Schritt nicht nötig und es werden einfach die Mittelpunkte aller angegebenen Rechtecke ermittelt. Daraufhin ist es möglich im selben Maßstab mit einer weiteren Lisp-Funktion den euklidischen Abstand von allen Quellen zu jedem einzelnen Loudspeaker zu berechnen. Hierbei ist zu beachten, dass alle Grafiken, die in dem Picture-Objekt vom Anwender gezeichnet wurden und nicht einem Rechteck oder einem Kreis entsprechen ignoriert und für die weiteren Berechnungen nicht berücksichtigt werden. Da für die Applikation beliebig viele virtuelle Klangquellen angegeben werden können, werden in diesem Schritt auch alle Kreise erfasst, die im Picture-Objekt existieren, wobei die Reihenfolge irrelevant ist.
Klangverarbeitung
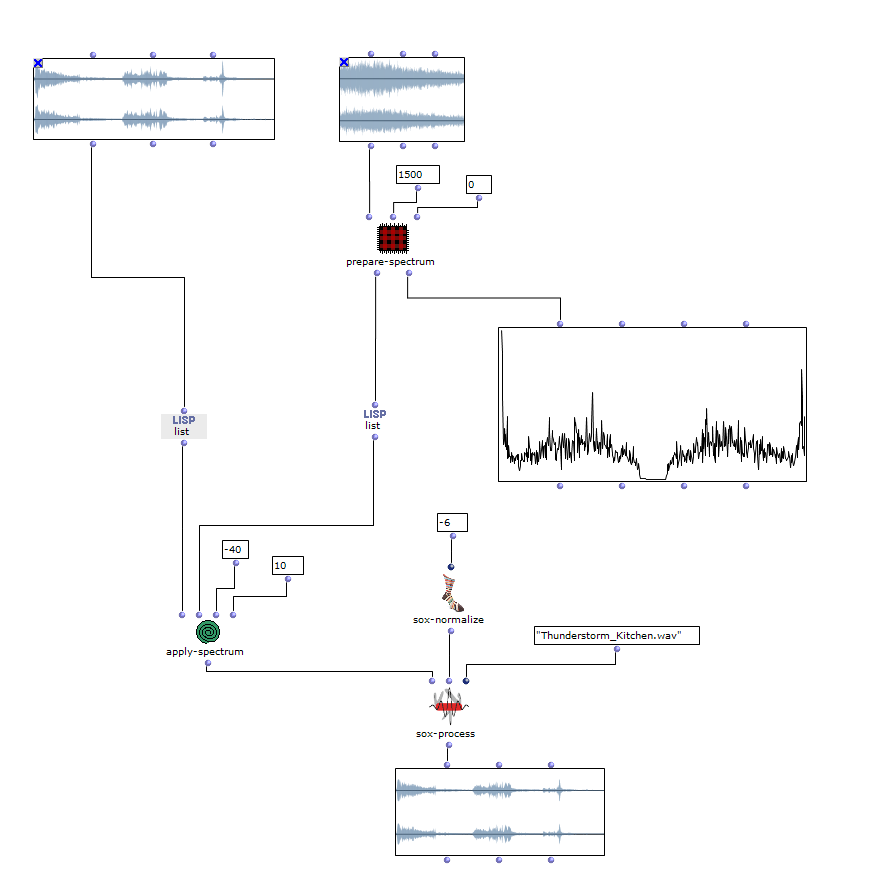
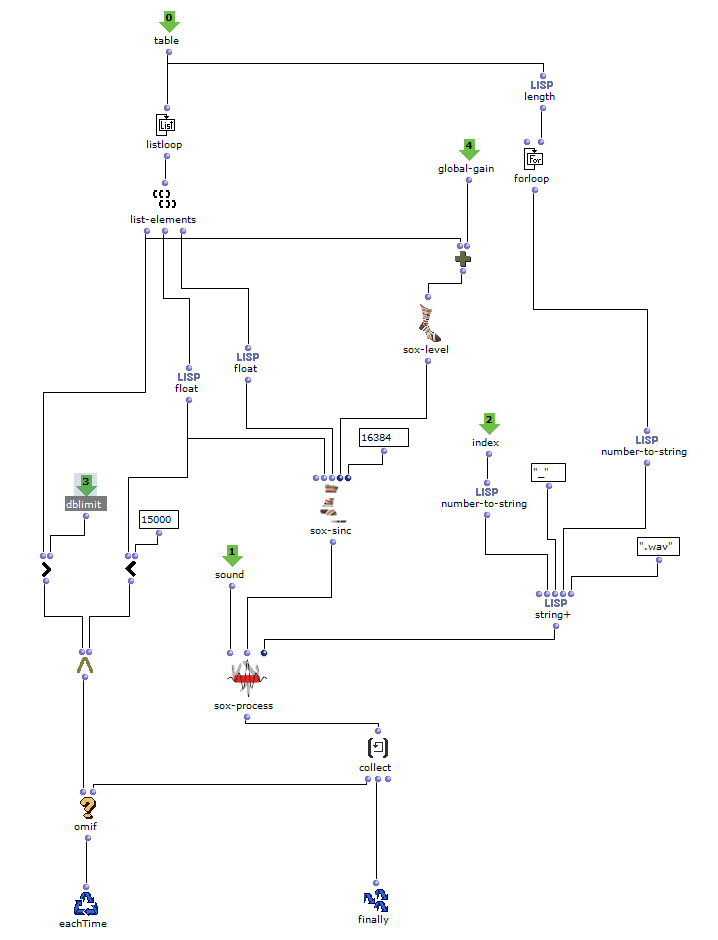
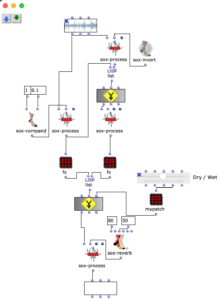
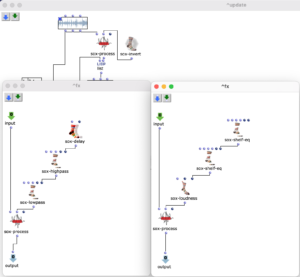
Im nächsten Abschnitt des Programms wird die Klangverarbeitung umgesetzt. Dabei wird grundlegend mit der vom Anwender angegebenen Sound-Datei zusammen mit den zuvor berechneten Distanzen eine Mehrkanaldatei erzeugt, welche für das vorgesehene Loudspeaker-Array verwendet werden kann. Dieser Prozess passiert in einem verschachtelten OM-Loop mit zwei Ebenen.
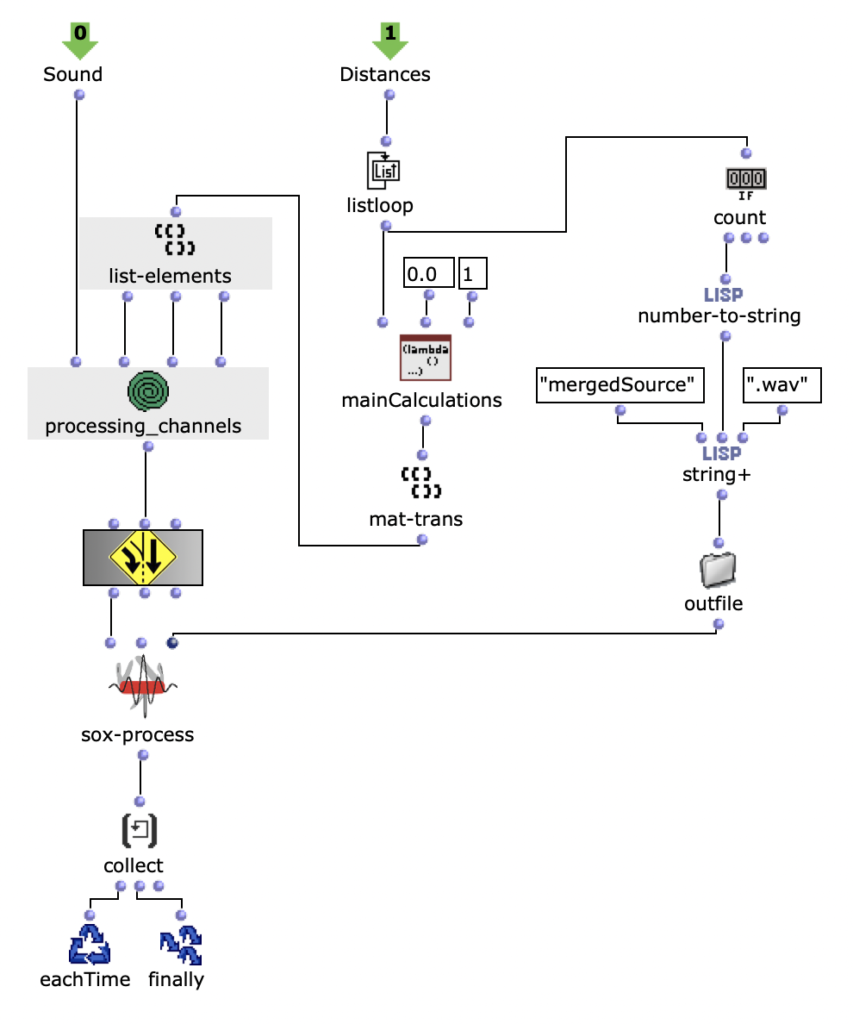
In der ersten Ebene wird zunächst über jedes Element innerhalb der Distanz-Liste iteriert. Dabei entspricht jedes dieser Elemente einer Liste, die zu einer virtuellen Klangquelle gehört, welche deren Distanzen zu jedem Loudspeaker beinhaltet. Bevor der Prozess in die zweite Ebene des Loops geht, werden in einer Lisp-Funktion weitere Berechnungen anhand der aktuellen Distanz-Liste angestellt.
In dieser Funktion wird über jede Distanz iteriert und jeweils die Zeitverzögerung, Lautstärkeabnahme und eine Cutoff-Frequenz für einen Lowpass Filter zur Berechnung der Luftabsorption hoher Frequenzen ermittelt und in einer Liste gesammelt. Mit dem Ergebnis dieser Lisp-Funktion geht es im nächsten Schritt in die zweite Ebene der Schleife.
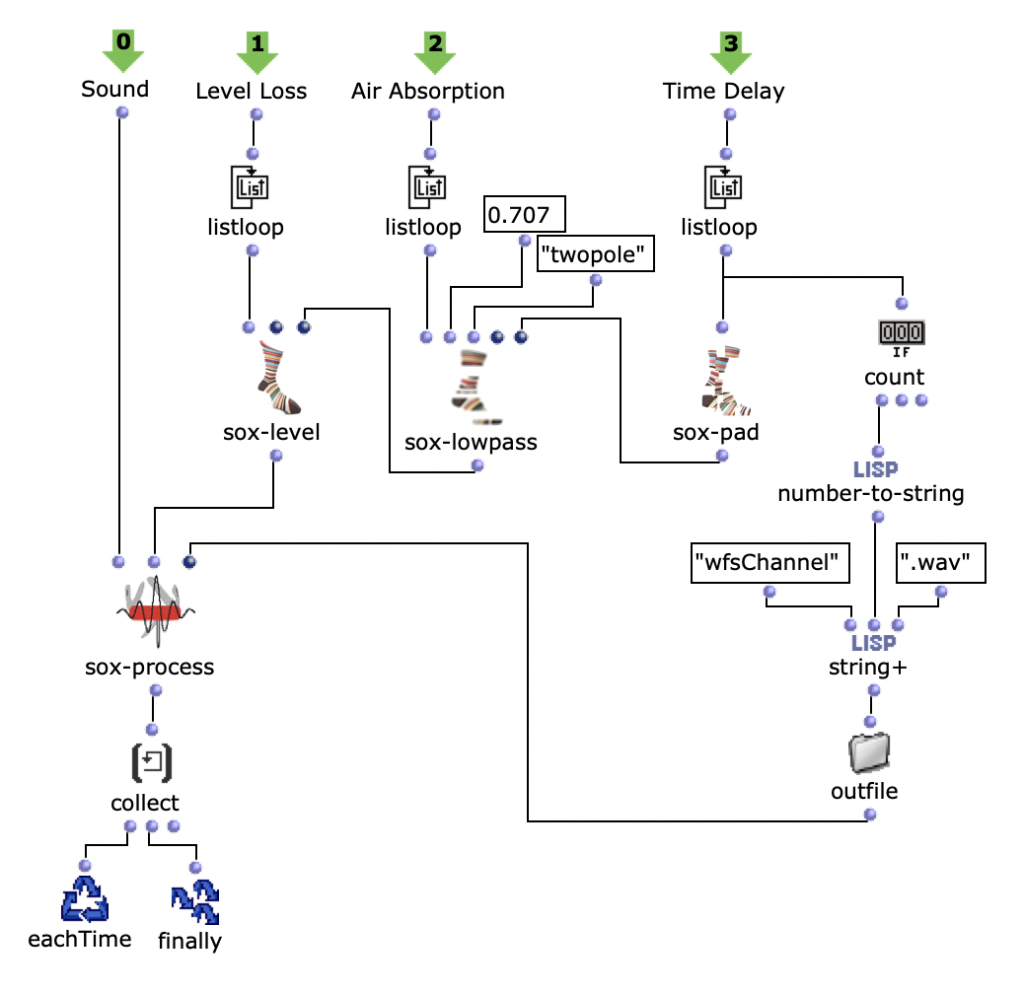
Hier wird für den jeweiligen berechneten Wert den jeweiligen SoX-Effect angewendet; SoX-Level für Lautstärkeabnahme, SoX-Lowpass für die Luftabsorption und SoX-Pad für die Zeitverzögerung. Dabei wird für jede Iteration die entstandene Audiodatei abgespeichert. Jede der drei Listen besitzt so viele Werte, wie zuvor berechnete Distanzen der aktuellen Klangquelle zu den Speakern. Also steht jede in diesem Loop gespeicherte Audiodatei für einen Kanal der späteren Mehrkanaldatei für die aktuellen Klangquelle.
Die Mehrkanaldatei kann nun im nächsten Schritt in der ersten Ebene mit SoX-Merge erstellt und am Ende des Loops zwischengespeichert werden. Dieser Prozess wiederholt sich für alle restlichen virtuellen Klangquellen (sofern vorhanden) und werden als Ausgabe dieses oberen Loops gesammelt. Alle Mehrkanaldateien der jeweiligen Klangquellen werden daraufhin mit einem SoX-Mix zusammengeführt.
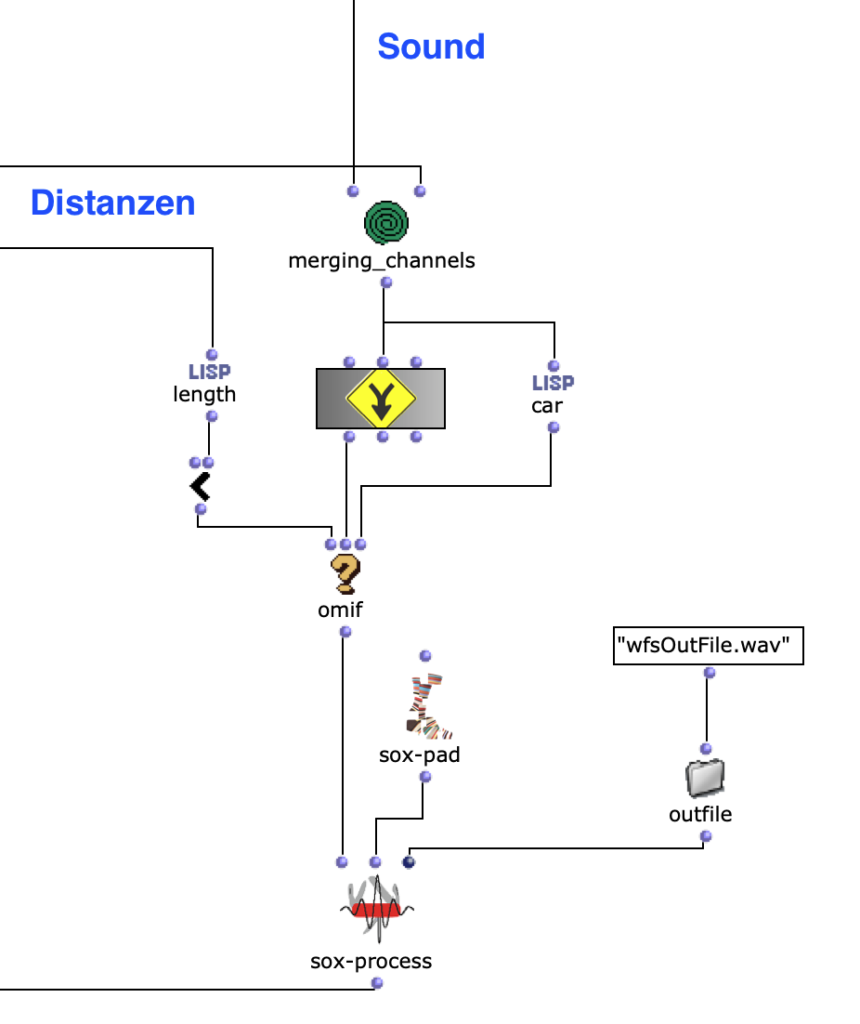
Wenn vom Anwender nur eine virtuelle Klangquelle angegeben wird, besteht die Ausgabe des äußersten Loops nur aus einer einzelnen Mehrkanaldatei für diese eine Quelle. In diesem Fall wird das SoX-Mix nicht benötigt und es würde sogar bei der Evaluation des Programms zu einem Fehler führen, wenn der Input des SoX-Mix nur aus einer Audiodatei bestünde. Mit dem OM-If wird daher die Verwendung des SoX-Mix umgangen, sobald die Ausgabe des Patchers, in welchem die Distanzen ermittelt werden, nur aus einer Liste besteht, was bedeutet, dass im Picture-Objekt nur ein Kreis für eine virtuelle Klangquelle gezeichnet wurde.
Abschließend kann mit dem SoX-Pad je nach Präferenz zusätzlich der Mehrkanaldatei Stille hinzugefügt werden, falls die gewählte Audiodatei beispielsweise besonders kurz ist. Gleichzeitig wird die finale Mehrkanaldatei in Outfile als „wfsOutFile.wav“ gespeichert.