
A link to download the applications can be found at the end of this blogpost. This project was also presented as a paper at the 2022 International Conference on Technologies for Music Notation and Representation (TENOR 2022).
Modularity in Sound Synthesis Tools
This blogpost walks through the structure and usage of two applications of machine learning (ML) methods for sound notation and synthesis. The first application is a modular sample replacement engine that uses a supervised classification algorithm to segment and transcribe a drum beat, and then reconstruct that same drum beat with different samples. The second application is a texture synthesis engine that uses an unsupervised clustering algorithm to analyze and sort large numbers of audio files.
The applications were developed in OpenMusic using the OM-SoX modular synthesis/analysis framework. This was so that the applications could be as modular as possible. Modular, meaning that they could be customized, extended, and integrated into a user’s own OpenMusic workflow. We believe this modularity offers something new to the community of ML and sound synthesis/analysis tools currently available. The approach to sound synthesis and analysis used here involves reading and querying many separate audio files. Such an approach can be encompassed by the larger term of „corpus-based concatenative synthesis/analysis,“ for which there are already several effective tools: the Caterpillar System, Audioguide, and OM-Pursuit. Additionally, OM-AI, ml.*, and zsa.descriptors are existing toolkits that integrate ML methods into Computer-Aided Composition (CAC) environments. While these tools are very precise, the internal workings of them are not immediately clear. By seeking for our applications to be modular, we mean that they can be edited, extended and integrated into existing CAC programs. It also means that they can be opened and up, examined, and reverse-engineered for a user’s own education.
One example of this is in figure 1, our audio analysis engine. Audio descriptors are implemented as subpatches in lambda mode, and can be selected as needed for the input audio.
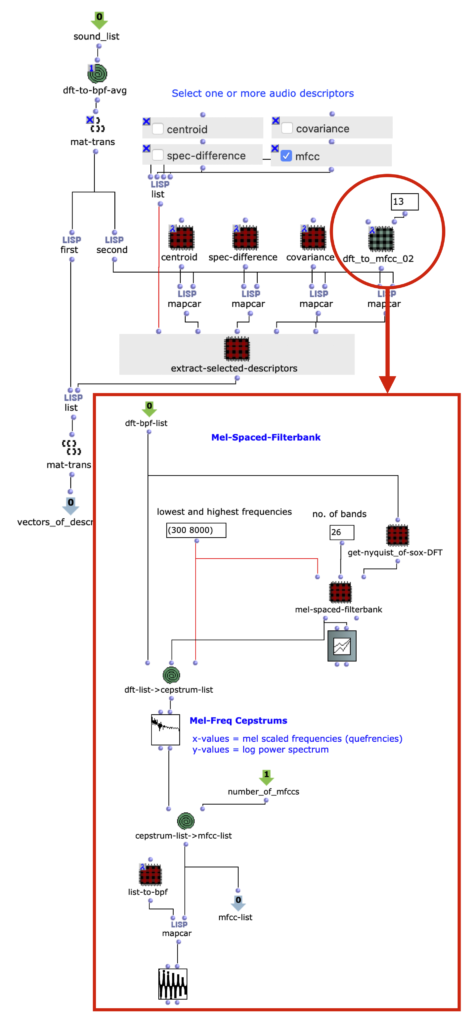
Figure 1: Interchangeable audio descriptors are set as patches in lambda mode. Here, a patch extracting 13 MFCCs is being used.
Another example is in figure 2, a customizable distance function in our texture synthesis application. This is the ML clustering algorithm that drives the application. Being a patch built from smaller OpenMusic objects, it is not only a tool for visualizing the algorithm at work, it also allows a user to edit it. For example, the n-dimension euclidean distance function could be substituted with another distance function, if needed.
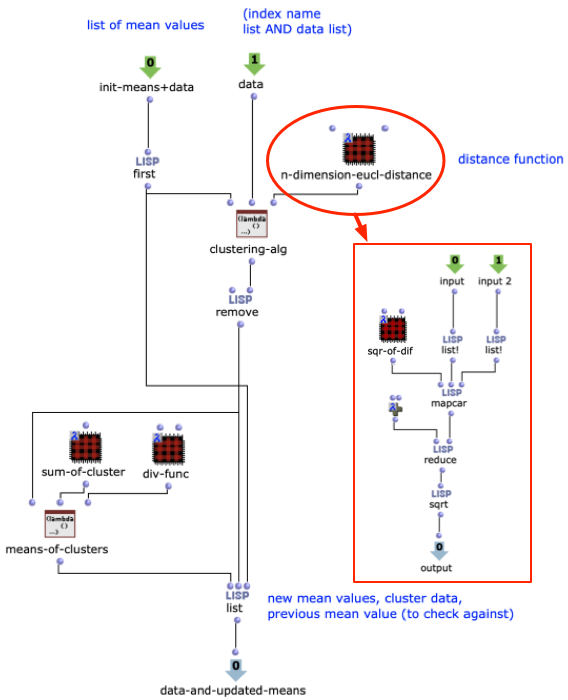
Figure 2: A simple k-means clustering algorithm, built within an OpenMusic abstraction. The distance function takes the form of a subpatcher in lambda mode.
With the modularity of the project introduced, we will on the next page move on to the two specific applications.



Über den Autor