
Click here for an English version of this text.
Bis letzten August, waren meine Vorstellung zu Anwendungen maschinellen Lernens meist funktional, getrennt von einer ästhetischen Referenz zu meiner künstlerischen Praxis: PKWs, die Verkehrsampeln erkennen, oder Radiolog*innen die bösartige Regionen in menschlichem Gewebe entdecken – das sind die ersten Dinge, die mir einfallen. Es gibt bestimmt eine Kunst hinter der Programmierung dieser Anwendungen. Jedoch war mir noch nicht klar, wie sich maschinelles Lernen auf meine Welt der zeitgenössischen Musik beziehen könnte. Deswegen war meine Hauptinteresse, als ich an Artemi-Maria Giotis Machine Learning Workshop bei der 2021 impuls Akademie teilgenommen habe, persönliche künstlerische Verbindungen zu diesem Forschungsbereich herzustellen und zu sehen, auf welche Weise ich meine zugrundeliegenden ästhetischen Annahmen über künstlerischen Anwendungen von maschinellen Lernen hinterfragen kann. Das Ziel dieses Textes ist es, mit euch die Verbindungen zu teilen, die ich hergestellt habe. Ich werde den Kompositionsprozess meines Stücks für Stimme und Live-Elektronik Shepherd durchgehen und es als Rahmen verwenden, um grundlegende Theorien und Methoden von maschinellen Lernen vorzustellen und zu skizzieren, wie ich ästhetisch auf sie reagiert habe. Ich werde nicht tief in technische Details gehen. Jedoch möchte ich anmerken, dass der technische Inhalt dieses Blogposts stark von Artemi-Maria Gioti inspiriert ist, die diesen Workshop geleitet hat und deren Forschung sich mit den kreativen Anwendungen von maschinellen Lernen in einer viel tieferen Weise beschäftigt. Ein tieferes Eintauchen in die vielfältigen Beziehungen zwischen maschinellen Lernen und Musik kann auf ihrer Website begonnen werden.
Die grundlegende Idee von maschinellen Lernen lautet „Verbesserung durch Erfahrung“. Der Informatiker Tom M. Mitchell beschreibt es so: „Der Bereich maschinellen Lernen befasst sich mit der Frage, wie man Computerprogramme konstruiert, die sich durch Erfahrung automatisch verbessern.“ (Mitchell, T. (1998). Machine Learning. McGraw-Hill.). Diese Prämisse der „Verbesserung“ hat mich bereits mit nicht-trivialen Fragen konfrontiert. Wenn zum Beispiel maschinelles Lernen eingesetzt wird, um einen improvisierenden Duopartner zu schaffen, was genau versteht der Computer dann als „gute“ oder „schlechte“ Improvisation, wenn er an Erfahrung gewinnt? Das Beantwort dieser ersten Frage ist nötig, bevor man überhaupt mit der Entwicklung eines robusten Algorithmus für maschinelles Lernen beginnen kann. In meinem Stück Shepherd wurde die Elektronik darauf trainiert, meine Stimme zu erkennen, insbesondere ob ich flüstere, rede, schreie oder schweige. Mein Ziel war es jedoch nicht, einen perfekt genauen Erkennungsalgorithmus zu schaffen. Vielmehr wollte ich, dass die Effektivität und die Ineffektivität des Algorithmus bei der Konzeption des Stücks gleiche Wichtigkeit haben. Shepherd ist ein Performance-Stück nach einer Metapher von Jesus aus der christlichen Bibel: Schafe erkennen einen Hirten am Klang seiner Stimme (Johannes 10). Die Elektronik reagiert auf meine Stimme in einer Weise, die gleichzeitig sicher und unsicher ist. Diese Performance ist eine Reflexion über die Nuancen des spirituellen Glaubens, über die Art und Weise, wie Ungewissheit ein notwendige Teil an der Bildung von Überzeugung und Glauben ist. Hier war die Elektronik kein funktionales Instrument (etwas, das von meiner Stimme gesteuert werden sollte), sondern fungierte eher als zweiter Spieler (ein Duopartner, der auf meine Stimme mit einer eingeschränkte Unvorhersehbarkeit reagierte).
Konkret gibt die Elektronik für jeden Input zwei verschiedene Antworten (siehe Abbildung 1). Sie nimmt eine eindeutige Klassifikation vor (etwas: „das ist ‚Schweige'“, „das ist ‚Flüstern'“, „das ist ‚Reden'“ usw.), und sie gibt eine „unentschiedene”, erratische Antwort durch Regression (etwa: „Stille: 0,833; Flüstern: 0,126; Reden: 0,201; Schreien: 0,044″). Wichtig für dieses Konzept, Glauben durch Zweifel zu begreifen, ist, dass das Ergebnis der Klassifikation aus dem der Regression abgeleitet wird. Die entscheidende Antwort (Klassifikation) war im Allgemeinen stabil in ihren Veränderungen über die Zeit, während die unentschiedene Antwort (Regression) sich schneller und unregelmäßiger bewegte. Insgesamt lieferte dies ein nützliches Material für die dynamische Kontrolle der von der Elektronik erzeugten digitalen Klänge. Bevor ich jedoch auf die Klangerzeugung eingehe, möchte ich erläutern, wie genau diese maschinelles-Lernen-Algorithmen funktionieren, wie die Elektronik lernt und den Klang meiner Stimme auswertet.
Abbildung 1: Max MSP und Wekinator (off-screen) analysieren die MFCCs eines Audios, um zwei Ausgaben aus die Input-Stimme zu liefern. Die erste Ausgabe stammt von einem Regressionsalgorithmus, die zweite von einem Klassifizierungsalgorithmus.
Damit die Elektronik meine Input-Stimme auswerten kann, benötigt sie zunächst einen Trainingssatz, eine Sammlung von Daten, die aus dem Klang meiner Stimme extrahiert wurden und mit deren Hilfe sie meine Stimme „zu kategorisieren lernen“ kann. Ein wichtiger technischer Punkt ist, dass der Algorithmus niemals Audiodaten direkt auswertet. Bei den Trainings- und Testdaten wertet der Algorithmus immer numerische Daten (hier „Deskriptoren“ genannt) aus, die aus den Audiodaten extrahiert wurden. Dies ist ein Grund dafür, dass Algorithmen für maschinelles Lernen in Echtzeit arbeiten können, auch mit Audiodaten. Wie ich bereits erläutert habe, basiert mein Stimmerkennungsprogramm auf zwei Konzepten von maschinellen Lernen: Klassifikation und Regression. Ein Klassifikationsalgorithmus gibt aus den Eingabedaten einen diskreten Wert zurück. In meinem Fall sind das die Werte „Schweige“, „Flüstern“, „Reden“ und „Schreien“. Um einen Trainingssatz zu erstellen, habe ich Audioaufnahmen von jeder dieser Klassen (insgesamt vier Audiodateien) gemacht und daraus MFCCs (Mel-Frequency Cepstrum Coefficients) extrahiert. MFCCs sind eine Darstellung der spektralen Energie eines Klangs, die auf den Bereich der typischen menschlichen Hörwahrnehmung kalibriert ist, und werden bereits häufig in Stimmerkennungsprogrammen, Anwendungen zur Suche nach Musikinformationen und anderen Anwendungen zur Klangfarbeerkennung verwendet.
Ich habe die Max MSP-Library „Zsa.descriptors” benutzt, um meine MFCCs zu berechnen. Ich habe auch mit anderen Deskriptoren experimentiert, z. B. „spectral centroid, „spectral Flatness“, „amplitude peaks“ sowie mit einer unterschiedlichen Anzahl von MFCCs. Schließlich habe ich herausgefunden, dass mein Algorithmus mit 13 MFCCs als einzige Deskriptoren am genauesten ist, und dass die Deskriptor-Daten nur etwa fünf Mal pro Sekunde ermittelt werden müssen. Ich habe festgestellt, dass meine vier Klassen auf einer Mikroebene eine große Ähnlichkeit aufwiesen. Zum Beispiel hat das Wort „Synthesizer“ viele „s“-Laute, die beim Flüstern praktisch dieselben sind wie beim Reden. Aus diesem Grund kann der Algorithmus bei einer niedrigeren Analyse-Frequenz ein allgemeineres Bild von jeder meiner Stimmklassen erhalten, so dass diese Mikro-Momente der Ähnlichkeit weniger ins Gewicht fallen.
Der für mein Stimmerkennungsprogramm verwendete Standardalgorithmus war die Klassifikation. Mein Klassifikationsalgorithmus wurde jedoch mittels eines zweiten gängigen Algorithmus aus dem Bereich maschinellen Lernen entwickelt: Regression. Wie ich bereits erwähnt habe, wollte ich in meine Elektronik ein gewisses Maß an „Unentschiedenheit“ einbauen, etwas Unstabiles, das im Gegensatz zum stabilen Charakter eines Standardklassifikationsalgorithmus stehen würde. Ein Regressionsalgorithmus liefert keine diskreten Werte, sondern einen neuen „prädiktiven“ Wert, der auf einer aus den Trainingsdaten abgeleiteten Funktion basiert. Der Regressionsalgorithmus liefert also keine spezifische Stimmklasse. Vielmehr gibt er pro Stimmklasse einen Prozentwert zurück, der angibt, wie nah die Input-Stimme an der jeweiligen Stimmklasse liegt. Wenn ich flüstere sagt der Algorithmus also nicht, ob ich flüstere oder nicht, sondern wie weit ich von den „flüsternden“ Daten entfernt bin, auf die er trainiert wurde.
Ich habe einen Regressionsalgorithmus in Wekinator, einem einfachen und leistungsstarken Tool für maschinelles Lernen verwendet, um mein Regressionsmodell zu erstellen (siehe Abbildung 2). Die eingegebenen Audiodaten wurden in Max MSP analysiert, und die Deskriptordaten wurden über OSC an Wekinator gesendet. Wekinator erstellte aus diesen Daten ein prädiktives Regressionsmodell und sendete die Ausgabe zurück an Max MSP, um sie für die DSP-Steuerung zu verwenden. In Max MSP habe ich auf der Grundlage dieser Regressionsdaten einen Klassifikationsalgorithmus erstellt.
Abbildung 2: Wekinator wertet MFCC-Daten von Max MSP aus und liefert 4 Werte von 0,0-1,0, die die Ähnlichkeit der Input-Stimme mit den vier Stimmklassen (Stille, Flüstern, Reden, Schreien) angeben. Die Auswertung ist ein Regressionsmodell, das auf 752 Datenproben trainiert wurde.
Nach diesen technischen Einblicken komme ich wieder auf meine ursprüngliche Frage zurück: Wie kann ich eine ästhetische Verbindung zu diesen Konzepten herstellen? Wie ich bereits erwähnt habe, ist das Stück Shepherd für meine Solostimme und Live-Elektronik geschrieben. In dem Stück stehe ich allein auf einer Bühne und wechsle zwischen verschiedenen fiktiven Persönlichkeiten (ein Redner auf einem Landwirtschaftskongress, ein verärgerter Restaurantchef, ein Kompilationsvideo, in dem Danny Wolfers das Wort „Synthesizer“ sagt, und ein Prediger). Die Elektronik reagiert auf diese verschiedenen Charaktere, indem sie ihre eigenen Persönlichkeiten wechselt (Schafe; ein flüsternder, wimmernder Souschef; ein eigentliche Synthesizer; und eine Kompilation christlicher Musik). Die Elektronik und ich ändern unsere Persönlichkeiten in Reaktion aufeinander. Ich übe eine gewisse Kontrolle über die Elektronik aus, aber nicht die totale. Die Aufführung des Stücks ist wie gesagt eine Reflexion über die Verflechtung von Überzeugung und Zweifel, Entscheidung und „Unentschiedenheit“ im spirituellen Glauben. Innerhalb dieses Konzepts ist die Idee einer Maschine, die sich in Richtung „Perfektion“ „verbessert“, nicht länger ein relevanter Rahmen. In dem Konzept und folglich auch in der Musik, die ich zu machen versucht habe, tragen stabiler Glaube (Klassifikation) und instabile Unentschiedenheit (Regression) gleichermaßen zur musikalischen Beziehung zwischen mir und der Elektronik bei.
Je nachdem, wie meine Stimme klassifiziert wurde, steuerte die Elektronik eines von vier DSP-Modulen. Die einzelnen Parameter eines bestimmten Moduls wurden durch die erratischen Ausgangsdaten des Regressionsalgorithmus gesteuert (siehe Abbildung 3). Wenn meine Stimme beispielsweise als „Schweigen“ eingestuft wurde, erzeugte ein Granularsynthesizer schafähnliche Geräusche. Innerhalb dieses Synthesizers manipuliert der prozentuale Anteil des Flüsterns und Sprechens, der innerhalb der Schweige „erkannt“ wurde, die Tonhöhenverschiebung im Synthesizer (siehe Abbildung 4). Auf diese Weise besteht die Musik nicht nur aus vier verschiedenen Klangmodulen. Der Regressionsalgorithmus ermöglichte es jedem Modul, sich in bestimmte Richtungen zu biegen und zu verformen, da meine Stimme subtil Andeutungen einer Stimmklasse innerhalb einer anderen erkennen ließ. In einem Abschnitt wechselte ich zum Beispiel schnell zwischen der Rolle eines Redners, der auf einem Bauernkongress spricht, und einem Koch, der frustriert seinen Souschef anflüstert. Die Elektronik wechselte konsequent zwischen meinen flüsternden und sprechenden DSP-Modulen. Aber je frustrierter und verzweifelter mein Flüstern wurde, desto mehr „Reden“ erkannte die Elektronik in ihrem Regressionsalgorithmus. Auf diese Weise wird die innere Dramaturgie dieser fiktiven Persönlichkeiten von der Elektronik aufgenommen.
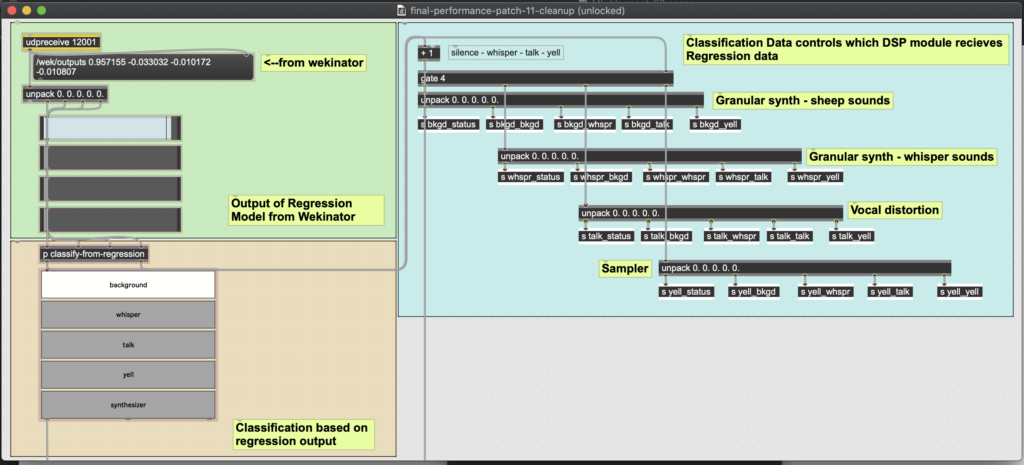
Abbildung 3: Die Klassifizierungsdaten würden eines von vier DSP-Modulen auslösen. Ein bestimmtes DSP-Modul würde die Regressionswerte für alle vier Klassen erhalten. Diese vier Werte würden die Parameter des DSP-Moduls steuern.
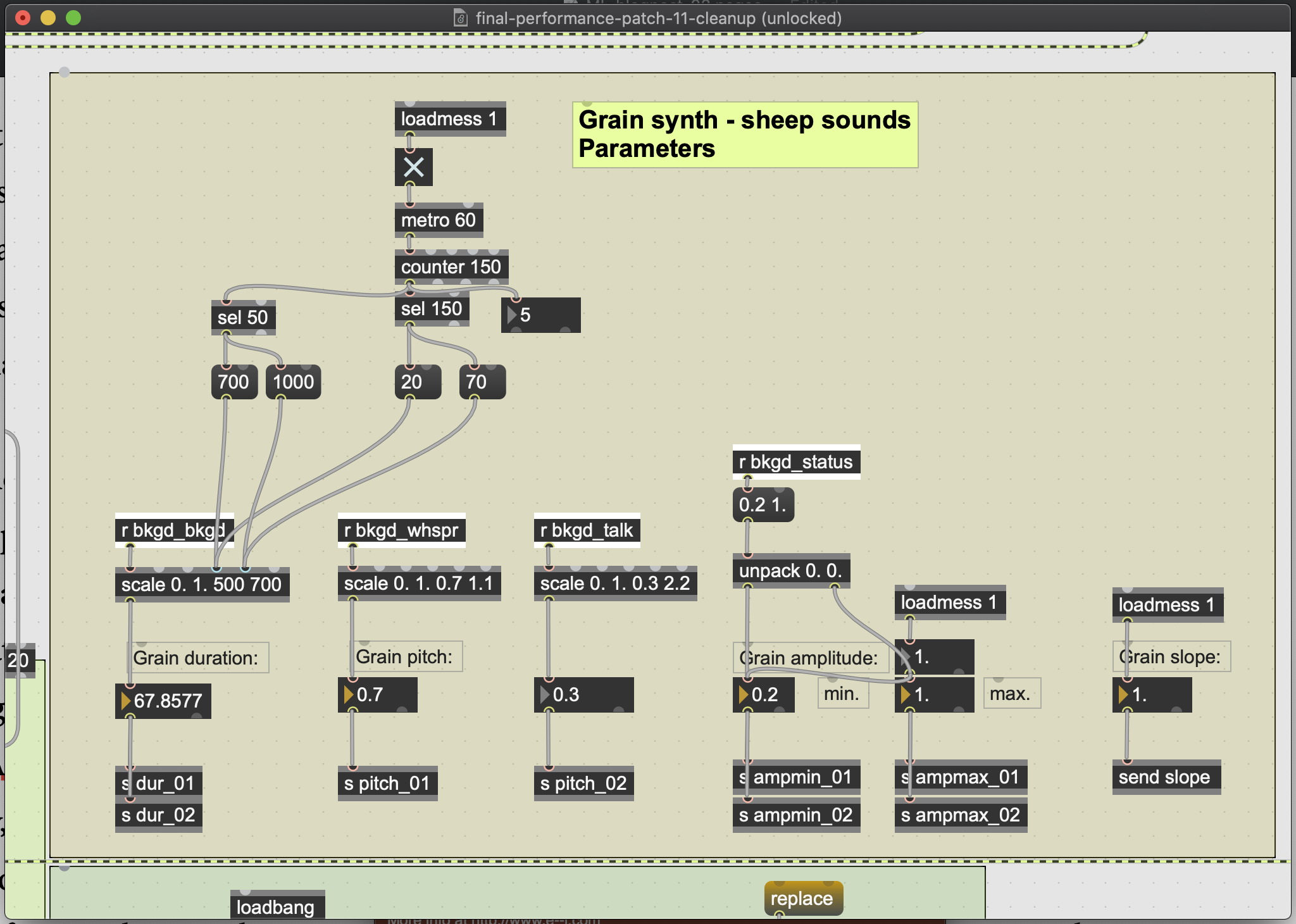
Abbildung 4: Parameterfenster für den Granularsynthesizer, der ausgelöst wird, wenn die Elektronik meine Stimme als „Schweige“ einstuft. Der Anteil des „Flüsterns“ und „Redens“, der in der „Schweige“ erkannt wird, steuert die Tonhöhe des Grains. Der Anteil der Schweige, der in der Schweige erkannt wird, steuert die Dauer des Grains. Da dieser Wert während der tatsächlichen Schweige meiner Stimme relativ statisch ist, wurde eine künstliche Manipulation der Dauer (oben im Fenster zu sehen) programmiert.
Ich möchte auf die These von Tom Mitchell zurückkommen, dass maschinelles Lernen bedeutet, dass sich Computer durch Erfahrung automatisch verbessern. Wenn Shepherd ein Werkzeug zur Stimme-Erkennung ist, dann ist es ineffizient bei der Verbesserung. Shepherd wurde jedoch nicht als Werkzeug entwickelt. Vielmehr ging es bei der Entwicklung von Shepherd darum, eine Beziehung zwischen meiner Stimme und der Elektronik zu kultivieren. Die Elektronik war eher ein Duopartner und weniger ein Instrument. Um es konkreter auszudrücken: Ich war nie auf der Suche nach „genauen“ Ergebnissen der Maschine. Als ich programmierte, suchte ich nach Ergebnissen, die Shepherds künstlerisches Konzept illustrierten. Auf diese Weise bedeutete die „Verbesserung“ des Stücks nicht die Verbesserung der Genauigkeit des Algorithmus, sondern der Beziehung zwischen mir und der Elektronik. Ein positiver Aspekt dieses Zustandes ist, dass der kompositorische Prozess nie von der Programmierung der Elektronik getrennt war. Beide entwickelten sich parallel. Das Komponieren dieses Stücks brachte mich zu der Einsicht, dass kreative Anwendungen von maschinellen Lernen auf jeder Ebene des technischen Verständnisses angewendet werden können. Wenn ihr Interesse an einer Aufnahme dieser Aufführung habt, findet ihr hier eine Bootleg-Aufnahme der Premiere.
Referenzen:
- Artemi-Maria Gioti – Komponistin und künstlerischer Forscherin im Bereich der künstlichen Intelligenz.
- Wekinator – Kostenlose Open-Source-Software von Rebecca Fiebrink, die maschinelles Lernen verwendet, um Musikinstrumente, Spielschnittstellen, Computervision und andere Tools für Sound und Animation zu erstellen.
- Zsa.descriptors – Bibliothek für die Echtzeitanalyse von Sounddeskriptoren für Max MSP, entwickelt von Mikhail Malt und Emmanuel Jourdan.
- NYU Music and Audio Research Laboratory – Kostenlose Online-Ressourcen und Datensätze.
- AIMC – Tagung über künstliche Intelligenz und musikalische Kreativität.
- ml.star – Bibliothek für maschinelles Lernen für Max MSP.
- OM-Pursuit – Korpusbasierte Klangmodellierung für die computergestützte Komposition in Open Music.



Über den Autor