
Modular Sample Replacement: Classification Method
As mentioned earlier, the individual segments of the initial drum beat are classified according to a training set of already-labeled drum samples. This is referred to as a supervised classification method. It is supervised because I, the user, have given the algorithm a set of labeled training-audio which it uses to recognize new, unlabeled audio. By classification, this means that the algorithm returns a single discrete value (here, it is a class-id). It cannot return a continuous value (it cannot say a value is in-between class-id 3 and 4, for example).
Figure 8 shows an important aspect of machine learning methods. When processing any data, the algorithm is always processing numerical data, it is never processing the actual audio signal. Before the audio is sent into the classification algorithm, it is first analyzed according a given number of audio descriptors (see figure 10b). Because instrument-type and timbre recognition are important in these two applications, the audio descriptors used are the spectral centroid, spectral difference, and covariance of a signal. These descriptors were derived from a DFT analysis made using the sox-analysis object.
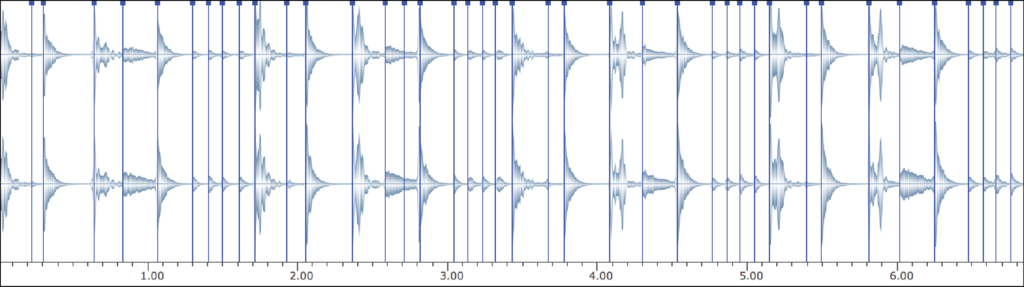
Figure 8a: The initial input audio, with markers

Figure 8b: A vector containing the filepath, the trim-data, and three audio descriptors

Figure 8c: The output of the classification algorithm, including the filename, the trim-data, and the class-id
The specific algorithm used is a k-nearest neighbors classification algorithm. To understand this algorithm, one can visualize all the training set audio on a graph. When an audio segment is compared against the training set, it is placed on this same graph, and its distance from every training-set audio on the graph is measured. The class-ids of the nearest k audio files to the input segment are reviewed, and this determine what class-id the segment belongs to. Figure 9 is an example of what an input data point would be assigned, when compared against a training set in a k=4 knn algorithm.
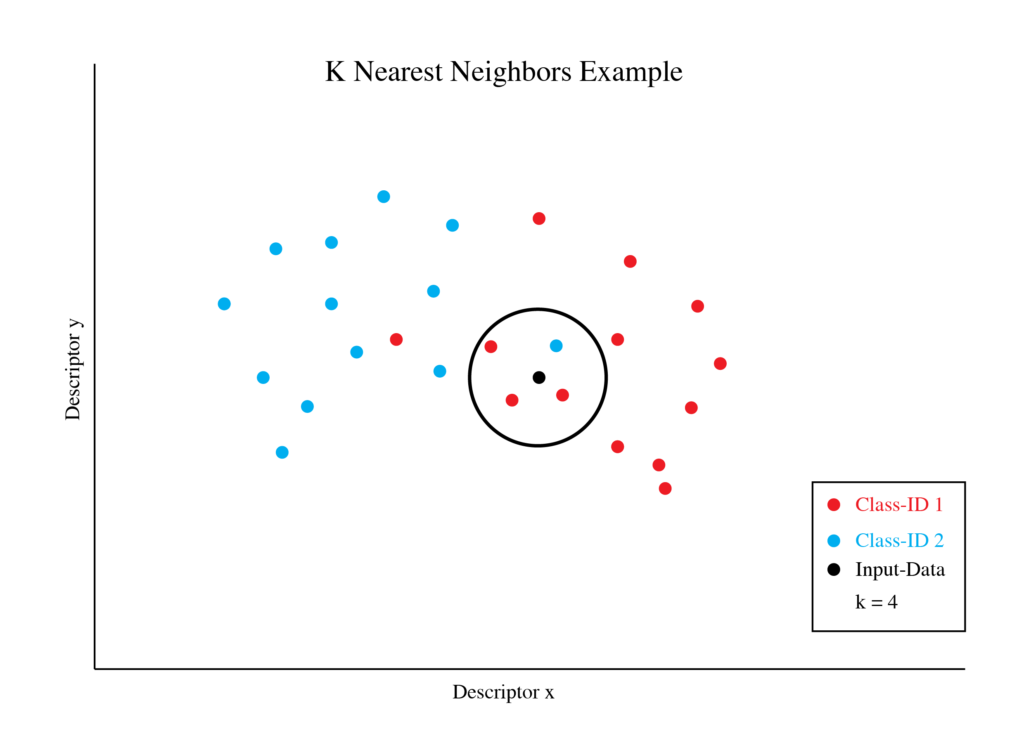
Figure 9: Among the four nearest neighbors of the input data, the majority are from class-id 1. Therefore, this algorithm would assign class-id 1 to this input data.


Über den Autor