Abstract
In diesem Projekt entstand im Rahmen der Lehrveranstaltung „Studienprojekte Musikprogrammierung“ eine audio-only Augmented Reality Klanginstallation an der Hochschule für Musik Karlsruhe. Wichtig für den nachfolgenden Text ist die terminologische Abgrenzung zur Virtual Reality (kurz: VR), bei welcher der Benutzer komplett in die virtuelle Welt eintaucht. Bei der Augmented Reality (kurz: AR) handelt es sich um die Erweiterung der Realität durch das technische Hinzufügen von Information.
Motivation
Zum einen soll diese Klanginstallation einem gewissen künstlerischen Anspruch gerecht werden, zum anderen war auch mein persönliches Ziel dabei, den Teilnehmern das AR und besonders das auditive AR näher zu bringen und für diese neu Technik zu begeistern. Unter Augmented Reality wird leider sehr oft nur die visuelle Darstellung von Informationen verstanden, wie sie zum Beispiel bei Navigationssystemen oder Smartphone-Applikationen vorkommen. Allerdings ist es meiner Meinung nach wichtig die Menschen auch immer mehr für die auditive Erweiterung der Realität zu sensibilisieren. Ich bin der Überzeugung, dass diese Technik auch ein enormes Potential hat und bei der Aufmerksamkeit in der Öffentlichkeit, im Vergleich zum visuellen Augmented Reality, ein sehr großer Nachholbedarf besteht. Es gibt mittlerweile auch schon zahlreiche Anwendungsbereiche, in welchen der Nutzen des auditiven AR präsentiert werden konnte. Diese erstrecken sich sowohl über Bereiche, in welchen sich bereits viele Anwendung des visuellen AR vorfinden, wie z.B. der Bildung, Steigerung der Produktivität oder zu reinen Vergnügungszwecken als auch in Spezialbereichen wie der Medizin. So gab es bereits vor zehn Jahren Unternehmungen, mithilfe auditiver AR eine Erweiterung des Hörsinnes für Menschen mit Sehbehinderung zu kreieren. Dabei konnte durch Sonifikation von realen Objekten eine rein auditive Orientierungshilfe geschaffen werden.
Methodik
In diesem Projekt sollen Teilnehmer*innen sich frei in einem Raum, in welchem Gegenstände positioniert sind, bewegen können und obwohl diese in der Realität keine Klänge erzeugen, sollen die Teilnehmer*innen Klänge über Kopfhörer wahrnehmen können. In diesem Sinne also eine Erweiterung der Realität („augmented reality“), da mithilfe technischer Mittel Informationen in auditiver Form der Wirklichkeit hinzugefügt werden. Im Wesentlichen erstrecken sich die Bereiche für die Umsetzung zum einen auf die Positionsbestimmung der Person (Motion-Capture) und die Binauralisierung und zum anderen im künstlerischen Sinne auf die Gestaltung der Klang-Szene durch Positionierung und Synthese der Klänge.
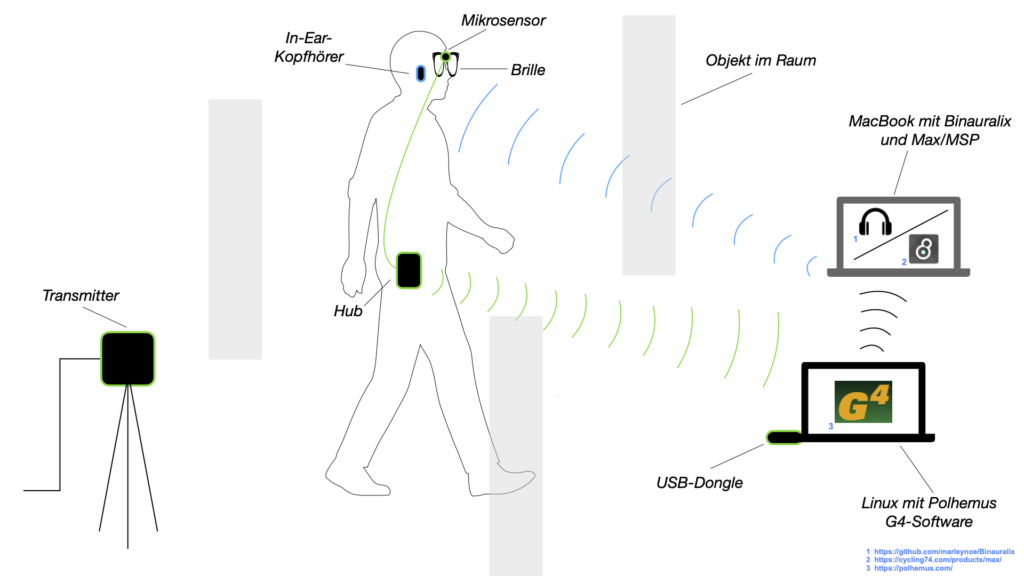
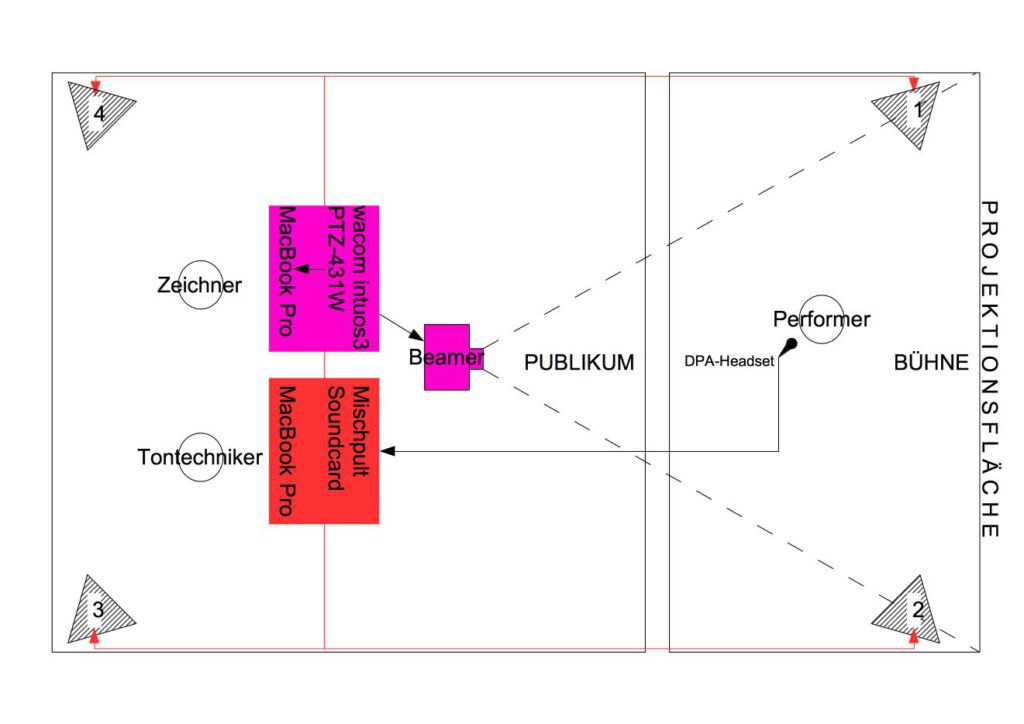
Abbildung 1
Das Motion-Capture wird in diesem Projekt mit dem Polhemus G4 System realisiert. Die Richtung- und Positionsbestimmung eines Micro-Sensors, welcher an einer vom Teilnehmer getragenen Brille befestigt wird, geschieht durch ein Magnetfeld, welches von zwei Transmittern erzeugt wird. Ein Hub, der über ein Kabel mit dem Micro-Sensor verbunden ist, sendet die Daten des Motion-Captures an einen USB-Dongle, der an einem Laptop angeschlossen ist. Diese Daten werden an einen weiteren Laptop gesendet, auf welchem zum einen die Binauralisierung geschieht und der zum anderen letztendlich mit den kabellosen Kopfhörern verbunden ist.
In Abbildung 2 kann man zwei der sechs Objekte in je einer Variante (Winkel von 45° und 90°) betrachten. In der nächsten Abbildung (Abb. 3) ist die Überbrille (Schutzbrille die auch über einer Brille getragen werden kann) zu sehen, welche in der Klanginstallation zum Einsatz kommt. Diese Brille verfügt über einen breiten Nasensteg, auf welchem der Micro-Sensor mit einem Micro-Mount von Polhemus befestigt ist.

Abbildung 2

Abbildung 3
Wie schon zuvor erläutert, müssen für den Aufbau der Klanginstallation auch diverse Entscheidung vor einem künstlerischen Aspekt getroffen werden. Dabei geht es um die Positionierung der Gegenstände / Klangquellen und die Klänge selbst.
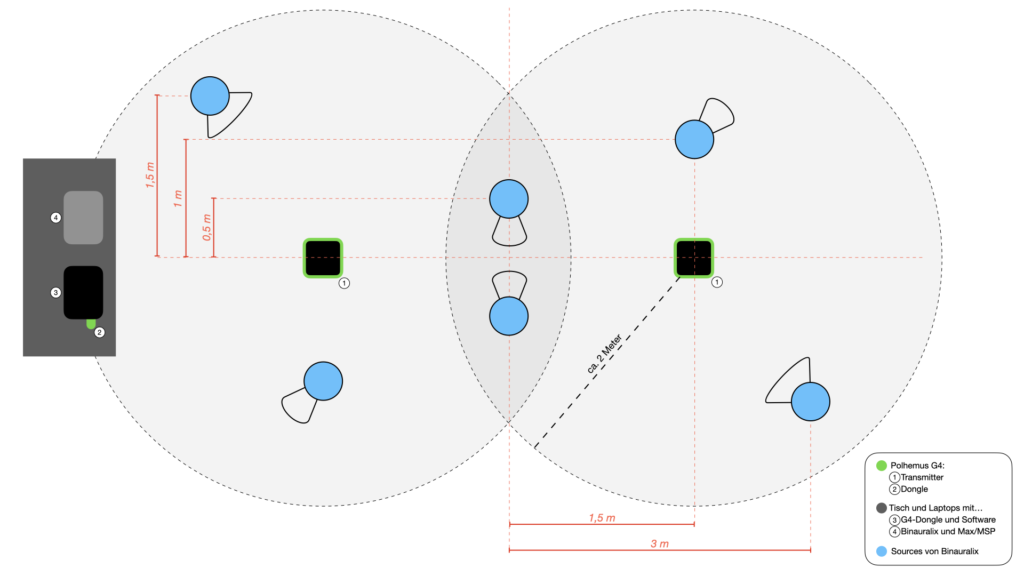
Abbildung 4
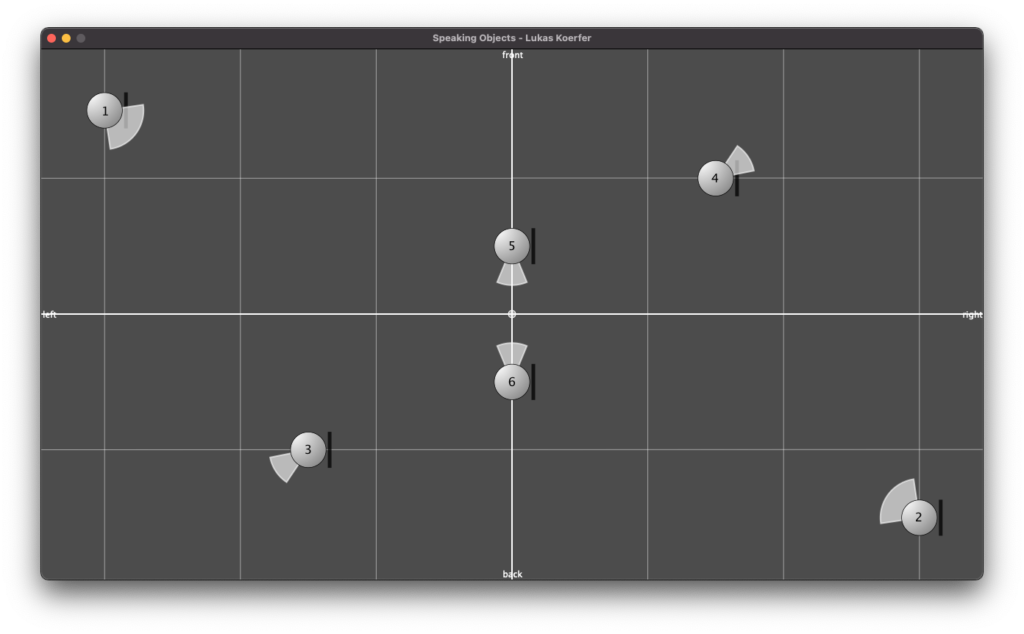
Abbildung 5
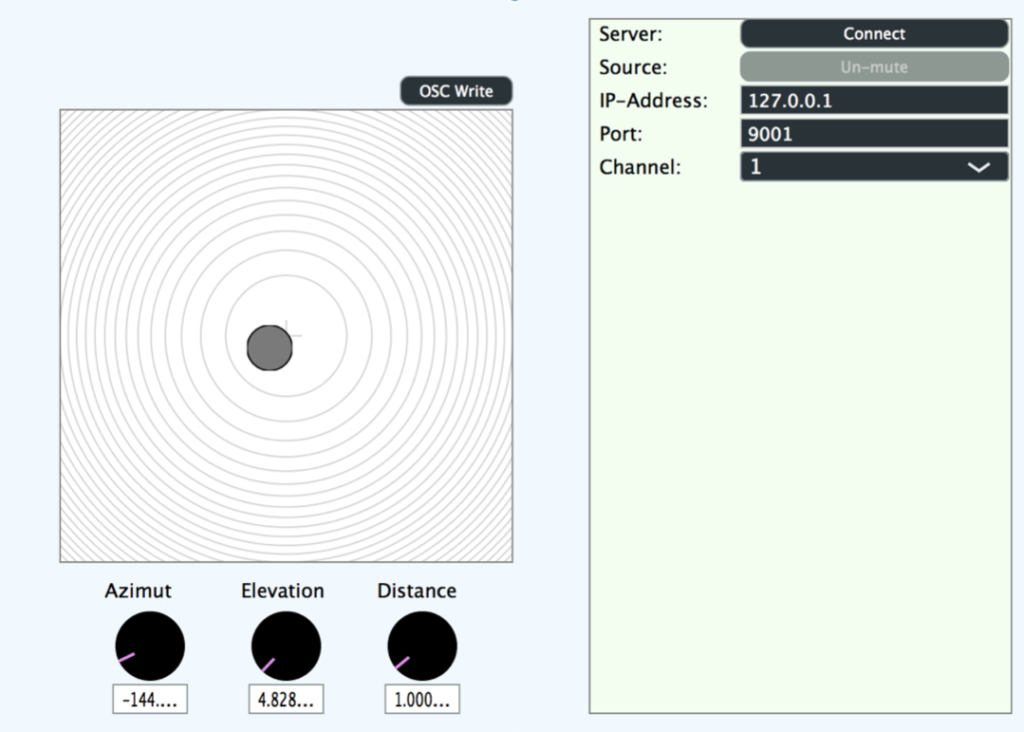
Die Abbildung 4 zeigt eine skizzierte Draufsicht des kompletten Aufbaus. Die sechs blau gefärbten Kreise markieren die Positionen der Gegenstände im Raum und natürlich gleichzeitig die der Klangquellen der Szene in Binauralix, welche in Abbildung 5 zu erkennen ist. Den farblosen Bereichen (in Abb. 4), im entweder 45° oder 90° Winkel, um die Klangquellen, können Richtung und Winkel der Quellen entnommen werden.
Die komplett kabellose Positionserfassung und Datenübertragung, ermöglicht den Teilnehmer*innen das uneingeschränkte Eintauchen in dieses Erlebnis der interaktiven realitätserweiternden Klangwelt. Die Klangsynthese wurde mithilfe der Software SuperCollider vorgenommen. Die Klänge entstanden hauptsächlich durch diverse Klopf- und Klickgeräusche, welche durch das SoundIn-Objekt aufgenommen wurden, und schließlich Veränderungen und Verfremdungen der Klänge durch Amplituden- und Frequenzmodulation und diverse Filter. Durch Audio-Routing der Klänge auf insgesamt 6 Ausgangskanäle und „s.record(numChannels:6)“ konnte ich in SuperCollider eine zweiminütige Mehrkanal Audio-Datei erstellen. Beim Abspielen der Datei in Binauralix wird automatisch der erste Kanal auf die Source eins, der zweite Kanal auf die Source 2 usw. gemappt.
Technische Umsetzung
Die technische Herausforderung für die Umsetzung des Projekts bestand zuerst grundlegen aus dem Empfangen und dem Umformatieren der Daten des Sensors, sodass diese in Binauralix verwertet werden können. Dabei bestand zunächst das Problem, dass Binauralix nur für MacOS und die Software für das Polhemus G4 System nur für Windows und Linux verfügbar sind. Da mir zu diesem Zeitpunkt neben einem MacBook auch ein Laptop mit Ubuntu Linux als Betriebssystem zur Verfügung stand, installierte ich die Polhemus Software für Linux.
Nach dem Bauen und Installieren der Polhemus G4 Software auf Linux, standen einem die fünf Anwendungen „G4DevCfg“, „CreateSrcCfg“, „g4term“, „g4display“ und „g4export“ zur Verfügung. Für mein Projekt muss zuerst mit „G4DevCfg“ alle verwendeten Devices miteinander verbunden und konfiguriert werden. Mit der Terminal-Anwendung „g4export“ kann man durch Angabe der zuvor erstellten Source-Configuration-File, der lokalen IP-Adresse des Empfänger-Gerätes und einem Port die Daten des Sensors über UDP übermitteln. Die Source-Configuration-File ist eine Datei, in welcher zum einen Position und Orientierung der Transmitter durch einen „Virtual Frame of Reference“ festgelegt werden und zum anderen Einstellungen zu Eintritts-Hemisphäre in das Magnetfeld, Floor Compansation und Source-Calibration-File vorgenommen werden können. Zum Ausführen der Anwendung müssen zu diesem Zeitpunkt die Transmitter und der Hub angeschaltet, der USB-Dongle am Laptop und der Sensor am Hub angeschlossen und der Hub mit dem USB-Dongle verbunden sein. Wenn sich nun das MacBook im selben Netzwerk wie der Linux-Laptop befindet, kann mit der Angabe des zuvor genutzten Ports die Daten empfangen werden. Dies geschieht bei meiner Klanginstallation in einem selbst erstellen MaxMSP-Patch.

Abbildung 6
In dieser Anwendung muss zuerst auf der linken Seite der passende Port gewählt werden. Sobald die Verbindung steht und die Nachrichten ankommen, kann man diese unter dem Auswahlfeld in der raw-Form betrachten. Die sechs Werte, die oben im mittleren Bereich der Anwendung zu sehen sind, sind die aus der rohen Nachricht herausgetrennten Werte für die Position und Orientierung. In dem Aktionsfeld darunter können nun finale Einstellung für die richtige Kalibrierung vorgenommen werden. Darüber hinaus gibt es auch noch die Möglichkeit die Achsen individuell zu spiegeln oder den Yaw-Wert zu verändern, falls unerwartete Probleme bei der Inbetriebnahme der Klanginstallation aufkommen sollten. Nachdem die Werte in Nachrichten formatiert wurden, die von Binauralix verwendet werden können (zu sehen rechts unten in der Anwendung), werden diese an Binauralix gesendet.
Das folgenden Videos bieten einen Blick auf die Szene in Binauralix und einen Höreindruck, während sich der Listener — gesteuert von den Sensor-Daten — durch die Szene bewegt.
Vergangene Vorstellungen der Klanginstallation