In diesem umfassenden Artikel werde ich die 3 Iterationen meiner Komposition beschreiben, um den Schaffensprozess zu präsentieren. Die Komposition habe ich im Rahmen des Seminars „Symbolische Klangverarbeitung und Analyse/Synthese“ bei Prof. Dr. Marlon Schumacher an der HFM Karlsruhe produziert.
Betreuer: Prof. Dr. Marlon Schumacher
Eine Studie von: Mila Grishkova
Wintersemester 2021/22
Hochschule für Musik, Karlsruhe
✅ Die erste Phase des Prozesses besteht aus der Schaffung eine Musikstücks. Die Komposition muss als 1-3 min. akusmatische Studie in der Tradition der musique concréte komponiert werden. Um Die Klänge, die man benutzen und transformieren kann, sollen nur Konkrete und keine Klangsynthesealgorithmen (granular, additiv, etc.) sein.
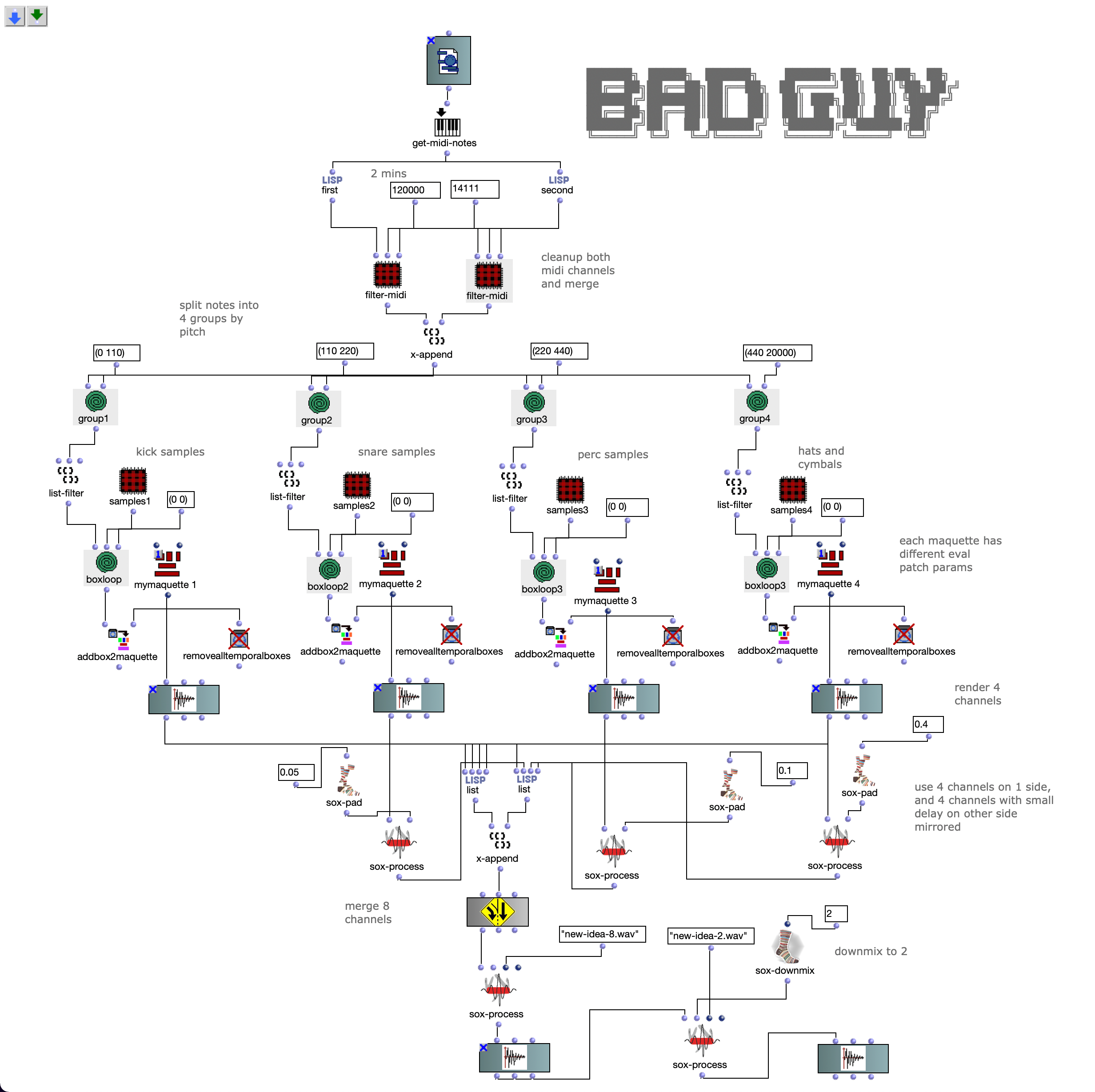
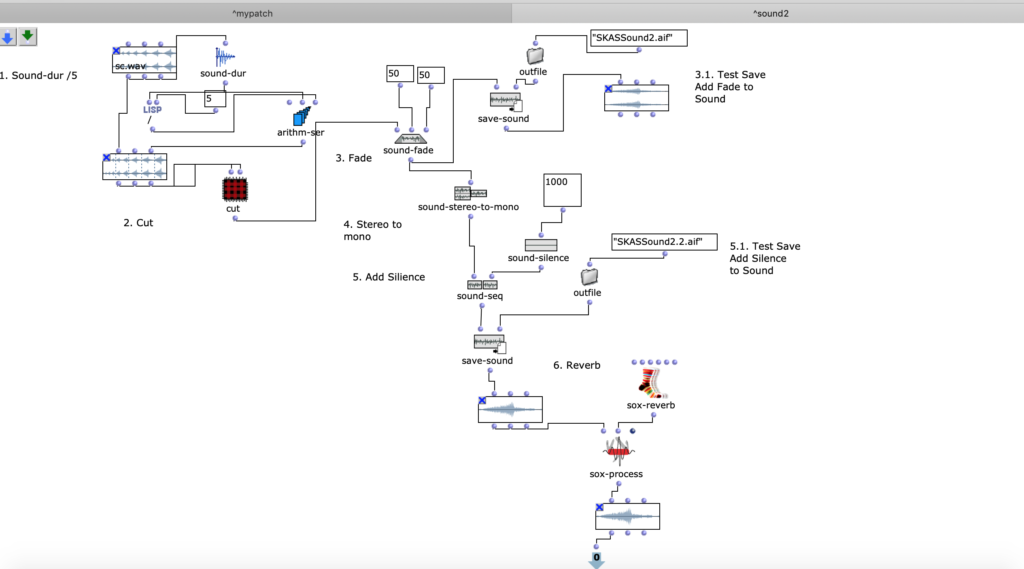
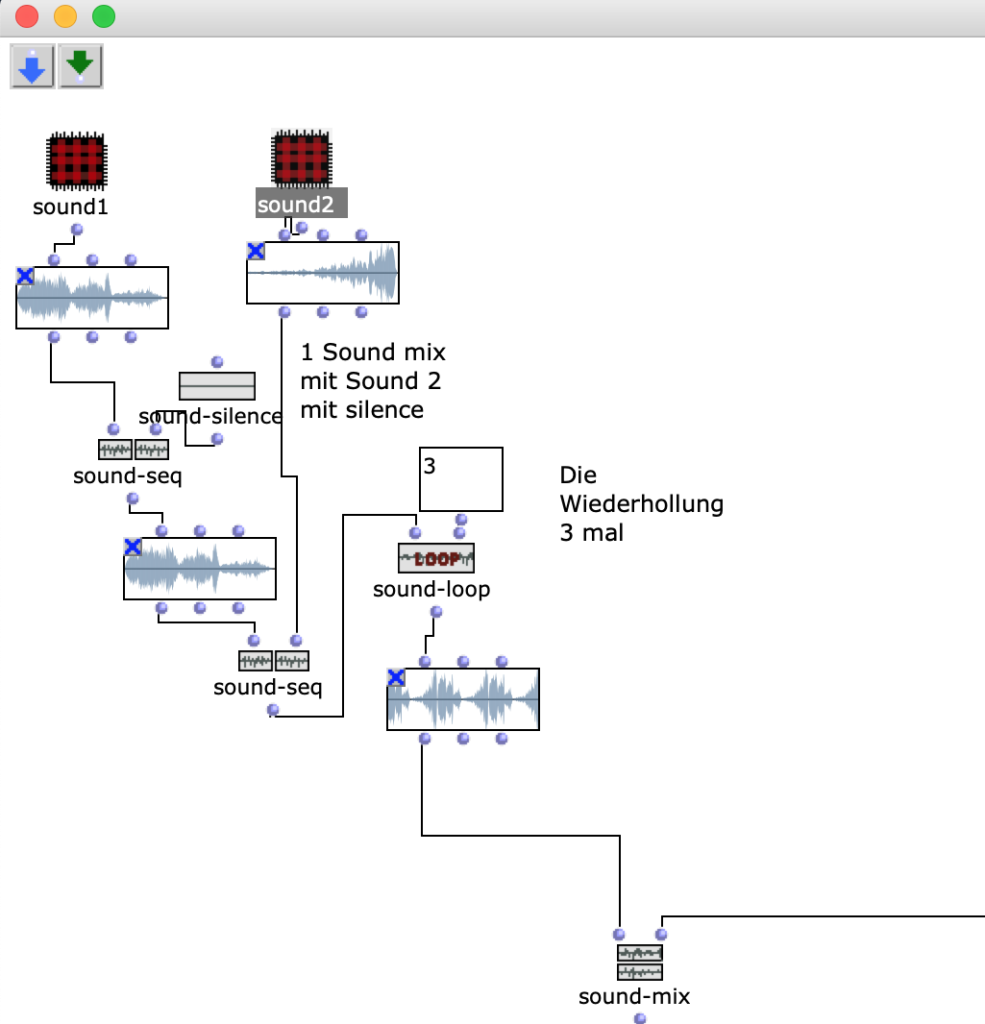
Um eine Musikkomposition zu komponieren, habe ich eine Musikstruktur überlegt: die Musik muss lang genug (laut Aufgabe) sein, und ach Pause zu haben. Um diese Struktur zu realisieren, benutze ich in dieser Übung Techniken wie zum Beispiel: Schnitt (s. F. 1, s. F. 2 Patch Cut), add Silence (s. F. 1 OM sound-seq, OM sound-silence).
Fig1. zeigt OpenMusic Patch 1. In diesem Patch kann man der erste Schritt der Bearbeitungstehnick sehen. Man kann Sound duration messen und dann den Sound durch eine bestimmte Zahl teilen. Mit der Hilfe eine Schnittmethode, bekommt man einen Soundabschnitt, den man als ein Teil der Kompositionen benutzen kann. Nach dem Schnitt habe ich fade-in/-out gemacht (OM sound-fade). Und als latzte in diesem Patch war Schweigenhinzufügung zum diesen Soundelement, damit dieser Element nicht nur aus dem Sound sondern auch aus dem Schweigen bestehen kann – in der Kompositionen weiter es bringt interesante Effekte.
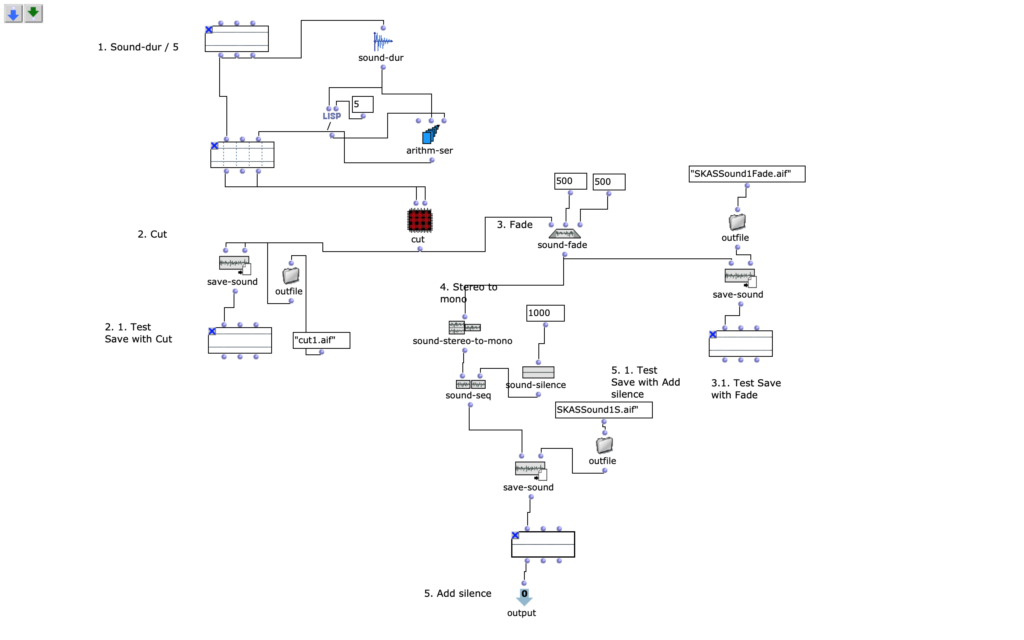
Fg. 1 zeigt OpenMusic Patch Sound1: Dieser Patch zeigt Transformationen erstes Sounds (sound-cut, sound-fade, sound-silence)
An der Figure 1 kann man noch einen OpenMusik Patch sehen. In dem patch „Cut“ befindet sich die Methode Sound zu schneiden. Als Input kommt in diesen Patch Sound-dur, als Output kommt ein geschnittenen Teil des Sounds.
Das Ziel meiner Komposition ist eine Geschichte zu erzählen. Die Musik muss sich in der Zeit entwickeln, deswegen verwende ich sound-silence, um die Geschichte (wie in der Sprache) zu strukturieren. Aber die Geschichte muss auch frei sein, zu diesem Zweck habe ich in der Komposition sogenannte Random Methode integriert.
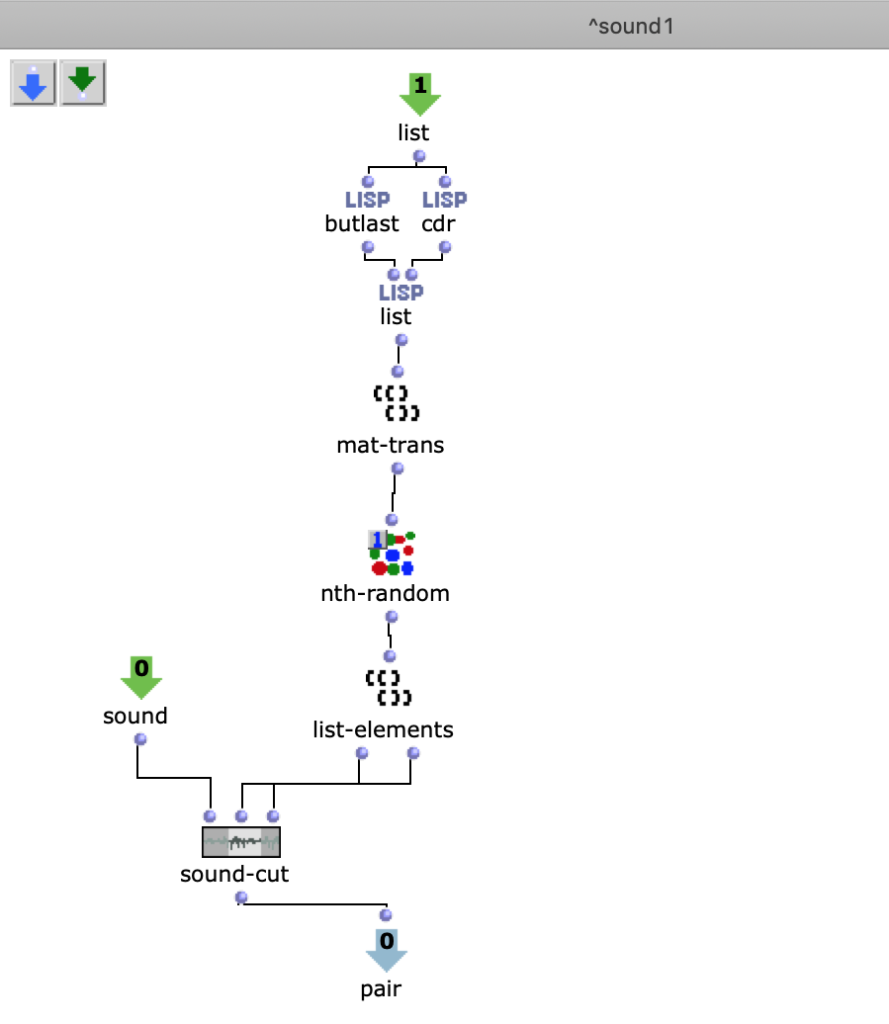
Fg. 2 zeigt OpenMusic Patch „Cut“: Dieser Patch zeigt Sound-Cut
In der erste Phase benutze ich auch Filtrierung, Transposition, Modulationseffekte um neuen Charakter des Klanges zu bekommen.
Nach dem Sound ist geschnitten worden, benutze ich OM sox-lowpass, OM sox-compand (um Dynamikbereich zu angewendet), ich mache bekommt fade-in/-out (OM sound-fade) und speichere den Sound (als Ergebnis des ersten Schritts).
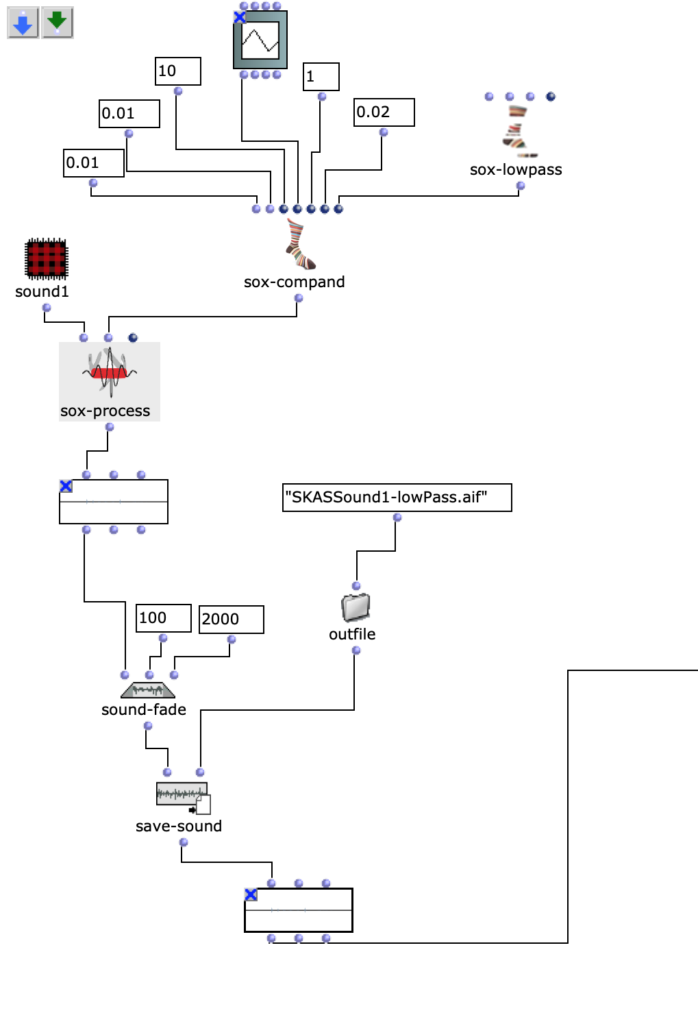
Fg. 3 zeigt OpenMusic Patch 3: Dieser Patch zeigt Sound1, Low-pass, Sound-fade
Mit den anderen Sounds (s. Fg. 4, Fg. 5, Fg. 7) habe ich das gleiche Prozedere gemacht. In der 4.Figure kann man Manipulationen mit dem Sound sehen. In diesem Patch befindet sich auch einen Patch mit „Cut“ Methode (ist gleiche wie bei. Fig 2).
Fg. 4 zeigt OpenMusic Patch Sound2: Dieser Patch zeigt Transformationen zweites Sounds
Mit schneiden, mixing, mit der Hinzufügung der Schweigen baue ich die Kompositionsstruktur.
Audio I ist das Ergebnis der erste Iteration.
Audio I: die erste Iteration
✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴
✅ Die zweite Phase des Prozesses ist eine klangliche Bearbeitung des akusmatischen Stücks, unter Einbezug der folgenden Techniken: EQ, Overdrive, Compression. Ich benutze Verzerrung um letztlich harmonische Obertöne zu erzeugen. Um beim Mixing störende Rückkoppelungen zu vermeiden, habe ich in den Signalweg Equalizer benutzt und damit die betroffenen Frequenzen abgesenkt.
Mit dem zweiten Sound habe ich das gleiche Prozedere, wie mit dem Sound 1, gemacht. In der 2.Figure kann man Manipulationen mit dem Sound sehen. In diesem Patch befindet sich auch einen Patch mit „Cut“ Methode (vergleiche. Fig 2 mit).
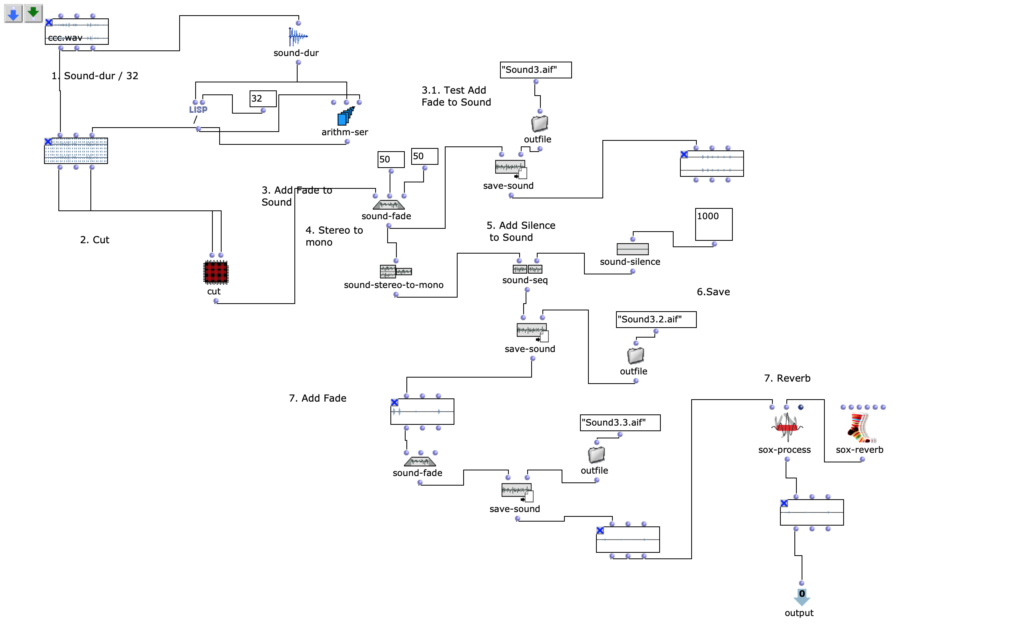
Fg. 5 zeigt OpenMusic Patch Sound3: Dieser Patch zeigt Transformationen drittes Sounds
Eine interessante Möglichkeit den Sound zu bearbeiten findet sich in der sog. „Brauerizing“ Methode, für welche man für bestimmte Instrumentsgruppe (ABCD busses) ihr eigene EQ, Overdrive, Distressor und Compression benutzt.
In meiner Kompositionen benutze ich Klänge im Sinne den Instrumenten (den Klan vom Tür wie Bass, Vogelklänge wie Stimme usw.).
Vogelklänge. Weiterhin benutzte ich den Compressor um die Vogelklänge zu bearbeiten. Den Klang eines Vogels lässt sich hinsichtlich spektralem Inhalt mit der menschlichen Stimme vergleichen.
Parallele Kompression verwendet (typ. wurde hier der Teletronix LA2A Röhrenkompressor eingesetzt). Deswegen lautet meine Idee: Parallel Compression im Code zu bauen und Parametern aus LA2A im Compressor zu benutzen. Ich greife auf Parallel Kompression zurück, um den Klang des Vogels zu bearbeiten, weil die Vogelstimme im Frequenzbereich der menschlichen Stimme liegt.
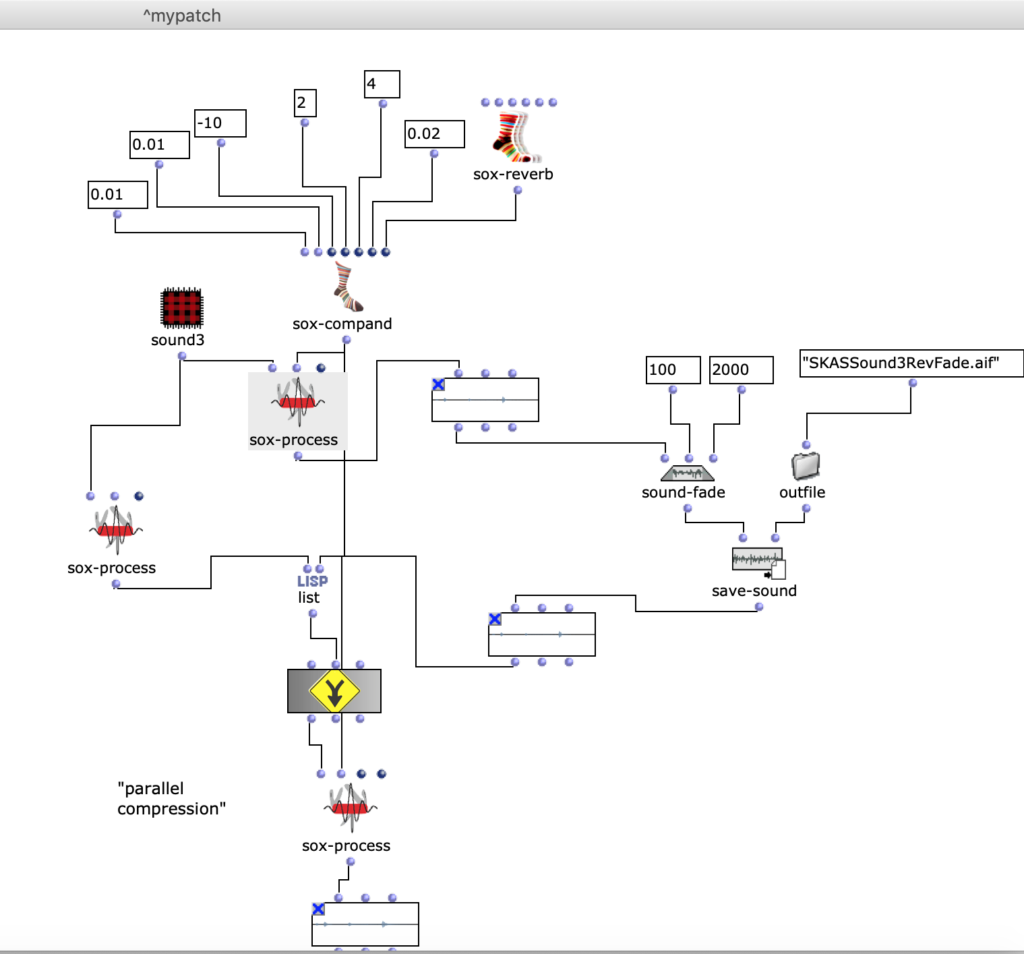
Fg. 6 zeigt OpenMusic Patch 6: Dieser Patch zeigt Sound3 und Parallel Compression.
Audio II ist das Ergebnis der zweite Iteration.
Audio II: die zweite Iteration
✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴
✅ Die dritte Phase des Prozesses basiert auf dem Prinzip einer Mix-Methode, diese heißt “Brauerizing”. Mischingenieur Michael Brauer ist ein Grammy-preisgekrönter Mixing-Ingenieur, der Audio in Kompressoren und Equalizer einspeist, um dem Eingangssignal harmonische Inhalte zu verleihen. Ein großes Problem, das die “Brauerizing” Mix-Methode löst, ist, dass der Kompressor basierend auf dem breiten Spektrum des empfangenen Eingangsmaterials reagiert. Falls ein Mixing-Ingenieur den Kompressor benutzt, um den gesamten Mix zu komprimieren, um Ton und Attitüde hinzuzufügen oder den Mix zu einem zusammenhängenderen Produkt zusammenzufügen, kann es sein, dass bestimmte Frequenzen stärker als andere komprimiert werden und dieser Mix beeinträchtigt wird. In meiner Komposition habe ich 4 Audio Materialien, die ich bearbeitet habe. Ich fasse mehrere Instrumente in Subgruppen zusammen und schicke sie in einen Kompressor, der zu der jeweiligen Gruppe gehört. Jedes Audio habe ich mit seinem eigenem Kompressorstyp bearbeitet. Erstes Audio ist Wind Geräusch. Ich benutzte diesen Klang, als Synth-Pads. Synth-Pads sind die verwaschenen Texturen, die dabei helfen, die Atmosphäre eines Tracks aufzubauen, die liefern oft den klanglichen Hintergrund, der eine Komposition zusammenhält. In “Brauerizing” Mix-Methode muss man Synth nach A Gruppe schicken, weil A Gruppe sammelt Instrumenten mit denen bekommt Mix keine schnelle Transienten. Diese Klänge kann man mit Neve 33609 Compressor und EQ benutzen.
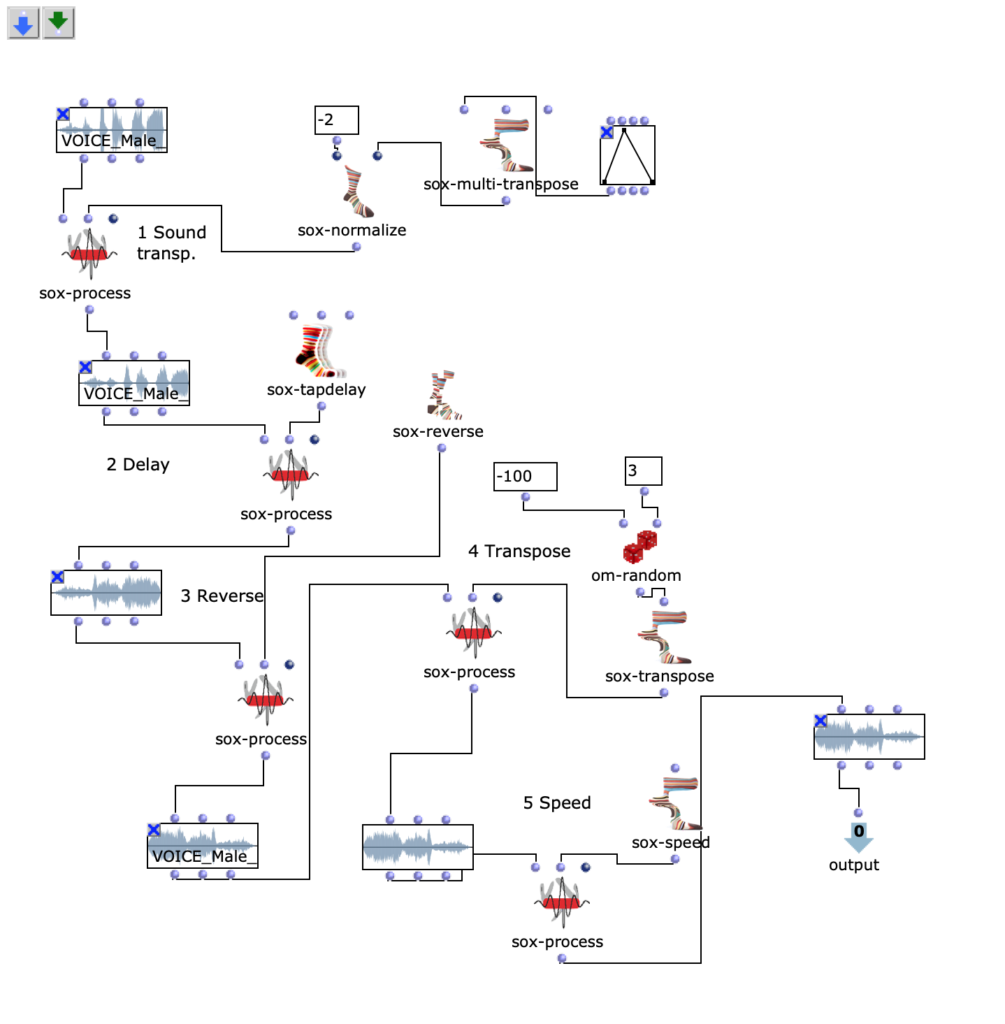
Zum Beispiel es gibt ein Lowpass Filter (s. Fg. 7): ich benutze es um die Höhen zu beschnitten. Klänge entsprechen Instrumenten (Sopran, Alt, etc. oder Melodie, Backing, etc.). Zweites Audio ist Vogel Stimme, das ich korrigieren muss.
Drittes Audio ist das Quietschgeräusch beim Öffnen einer Türe, ähnlich einer Bassstimme oder Tieferen Klängen/Energie in der Komposition. In “Brauerizing” Mix-Methode muss man Bass nach B Group schicken, dann Distressor (sox-contrast) und EQ benutzen. Für meine Ziele kann ich Distressor mit der Parameter den Kompressoren (z.b UREI LN1176) imitieren. Dafür kann man 4 Varianten der Kompression benutzen: 3:1, 4:1, 6:1, 20:1, das wird mit der Parametern LN1176 vergleichen (Werte: 4, 8, 12, 20). Attack muss in den Bereich zwischen 0.3 – 5 sein, Release 0 – 10. Dies ist in OM-SoX umgesetzt durch die Funktionen, wie in Fig. 8 beschriebt.
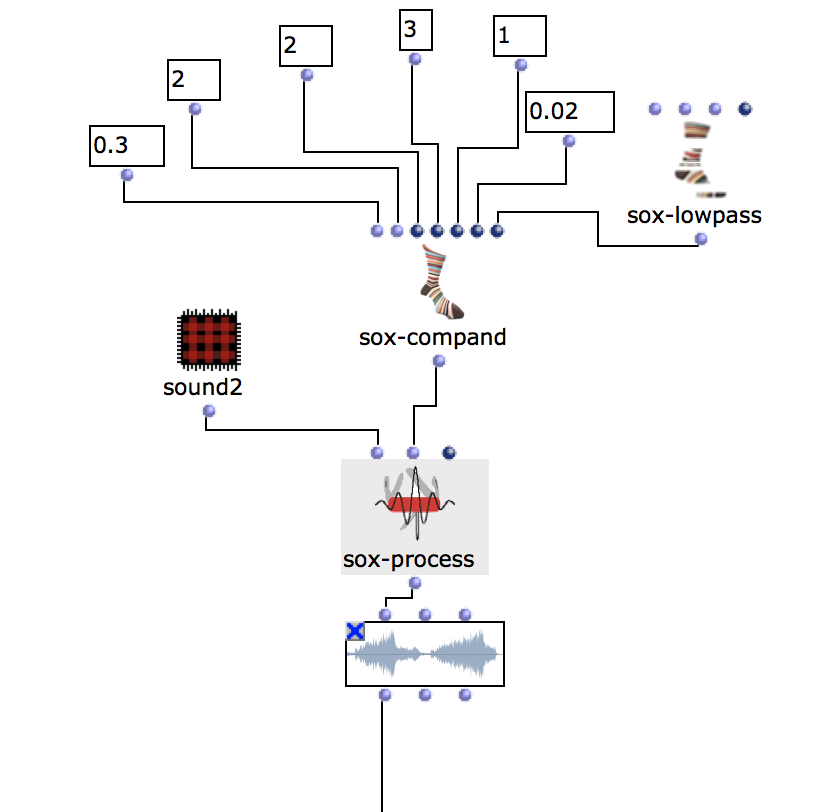
Fg. 7 zeigt OpenMusic Patch 5 Dieser Patch zeigt Implementierung / Simulation des Distressors.
Drittes Audio ist Vögelklang, das mit dem Parallel Compressor gearbeitet werden. Das schicke ich in Kompressor C. Viertes Audio ist Frosch- und Maus Klick- Klänge. Diese Klänge haben Transiten, deswegen benutze ich gleiche Kompressorparametern aus dem Gruppe B.
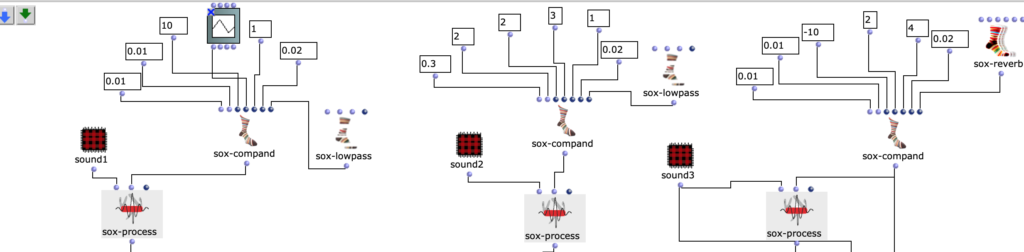
Fg. 8 zeigt OpenMusic Patch 5 Dieser Patch zeigt Sound1, Sound2, Sound3 sox-compand
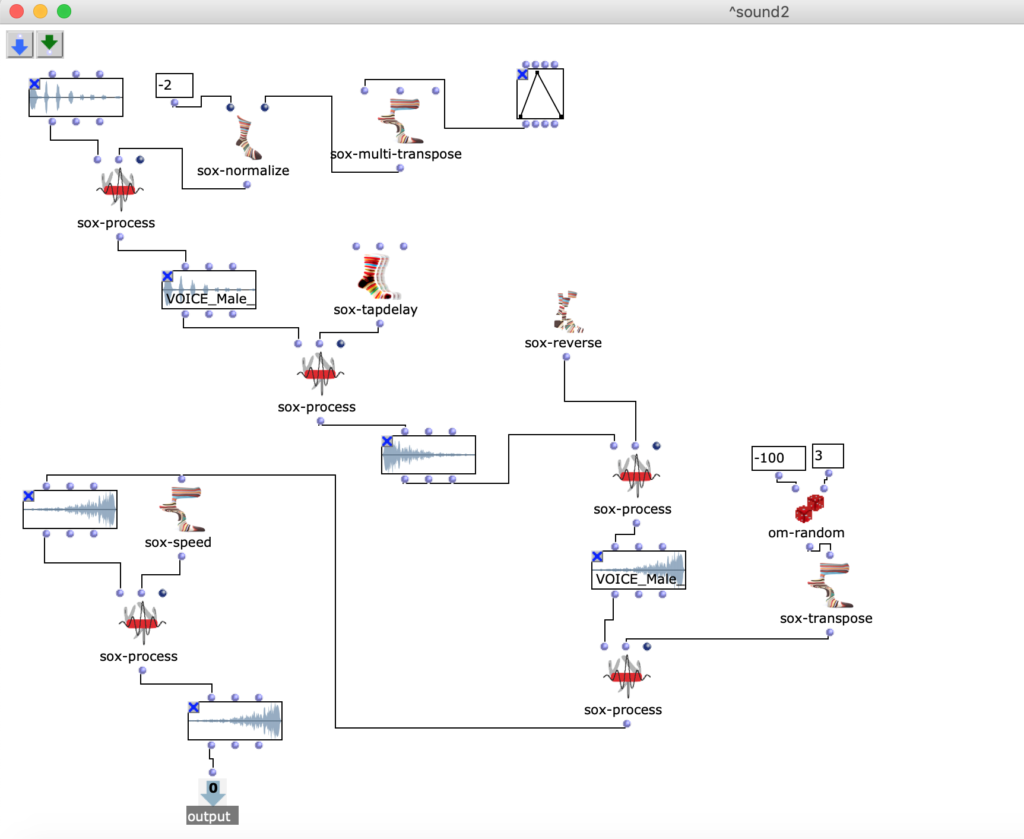
Beim vierten Audio benutze ich OM sox-speed mit om-random. Ich habe es so geplant, dass die Komposition (obwohl die im Voraus strukturiert ist), muss flexibel sein und paar zufällige Elemente haben.
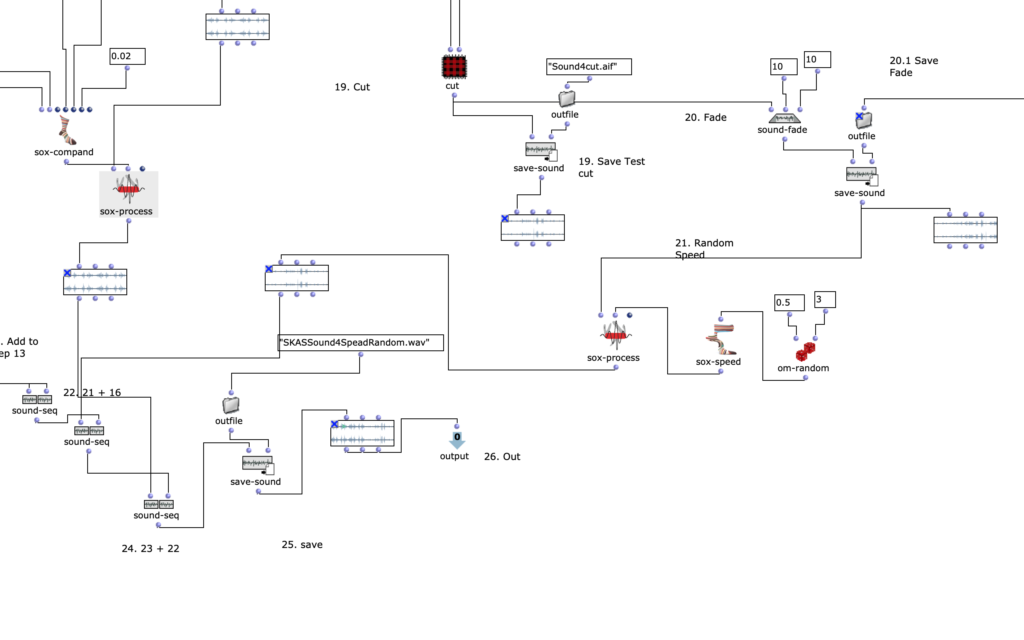
Fg. 9 zeigt OpenMusic Patch 6: Dieser Patch zeigt Transformationen des viertes Sound (Speed-random)
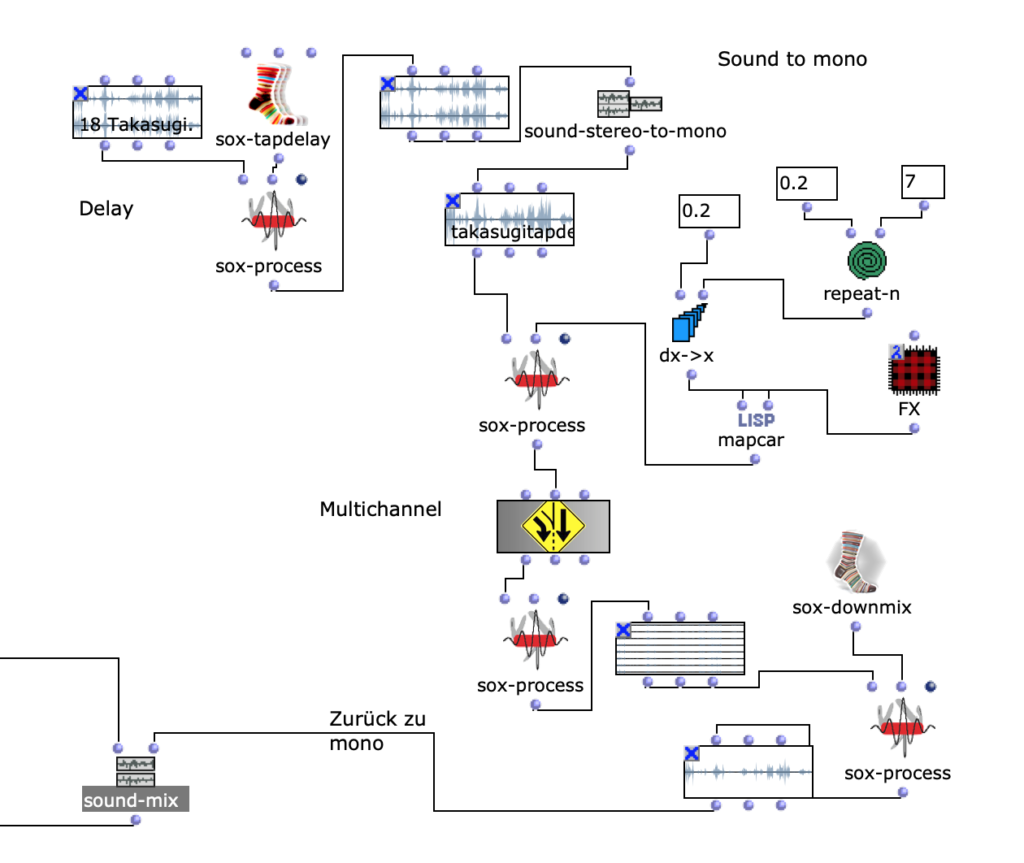
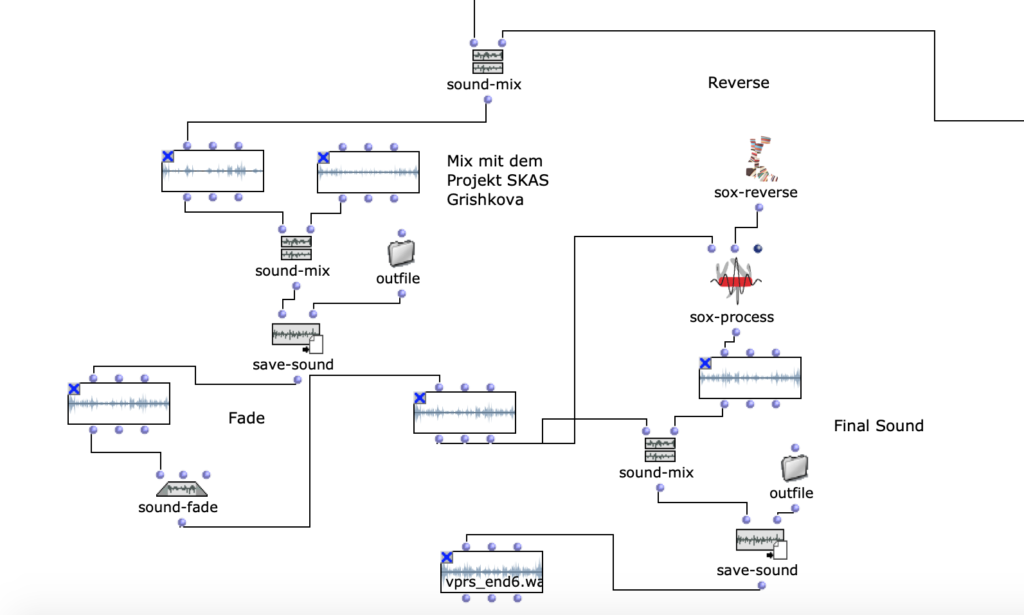
Dann mit der Technik OM sound-mix, OM sound-seq, OM sound-silence baue ich die Struktur und die Länge der Komposition. Zum Schluss benutze ich FX, Drive, Reverb, Compressor um finale Farben der Kompositionen zu bekommen.
Am Ende der Mastering Kette benutze ich ein Overdrive, EQ, eine Reverberation und einen „Glue“ Kompressor. Drei Verzerrertypen (Overdrive, Distortion und Fuzz) spielen unterschiedliche Rollen. Ich benutze Overdrive, weil der Overdrive von allen dreien den geringsten Zerrgrad hat. Um beim Mixing störende Rückkoppelungen zu vermeiden, habe ich in den Signalweg Equalizer benutzt und damit die betroffenen Frequenzen abgesenkt. Eine Reverberation bringt eine Persistenz von Ton, nachdem ein Ton erzeugt wurde, und entsteht, wenn ein Schall oder Signal reflektiert wird, wodurch sich zahlreiche Reflexionen aufbauen und dann wieder abklingen. Die Reverberation verleiht dem aufgezeichneten Ton Natürlichkeit. Ein „Glue“ Kompressor, ist ein Kleber zwischen den einzelnen Elementen, ein Summen-Kompressor, der auf alle Elemente in dem Mix reagiert und verdichtet ihn. Er senkt laute Signalanteile ab und hebt leise im Verhältnis dazu an. Attack – 0.3; Release – 0.7; Ratio 2/1, Dann mache ich die Komposition in 8 Kanäle.
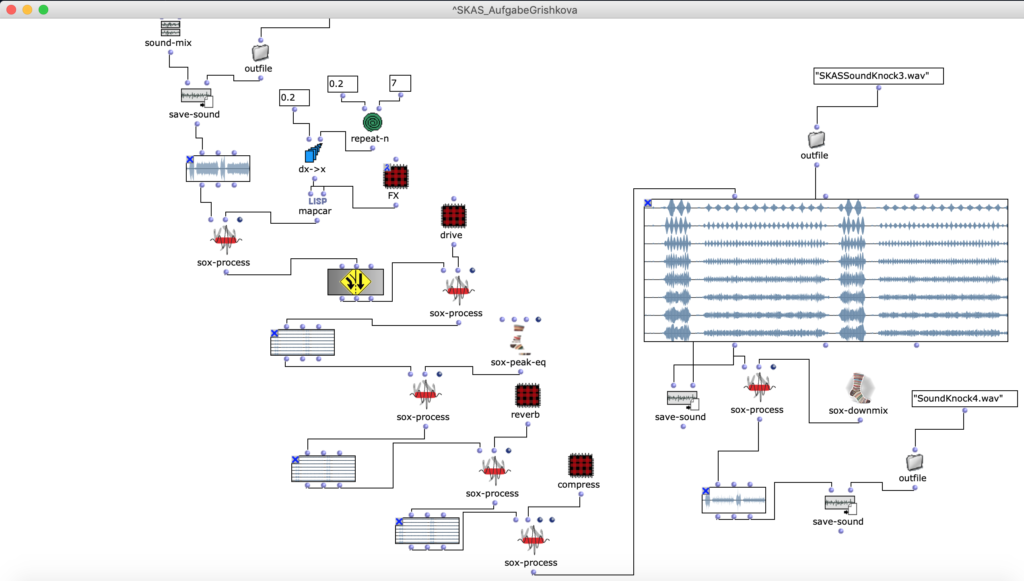
Fg. 10 zeigt OpenMusic Patch 5 Dieser Patch zeigt finale Transformationen
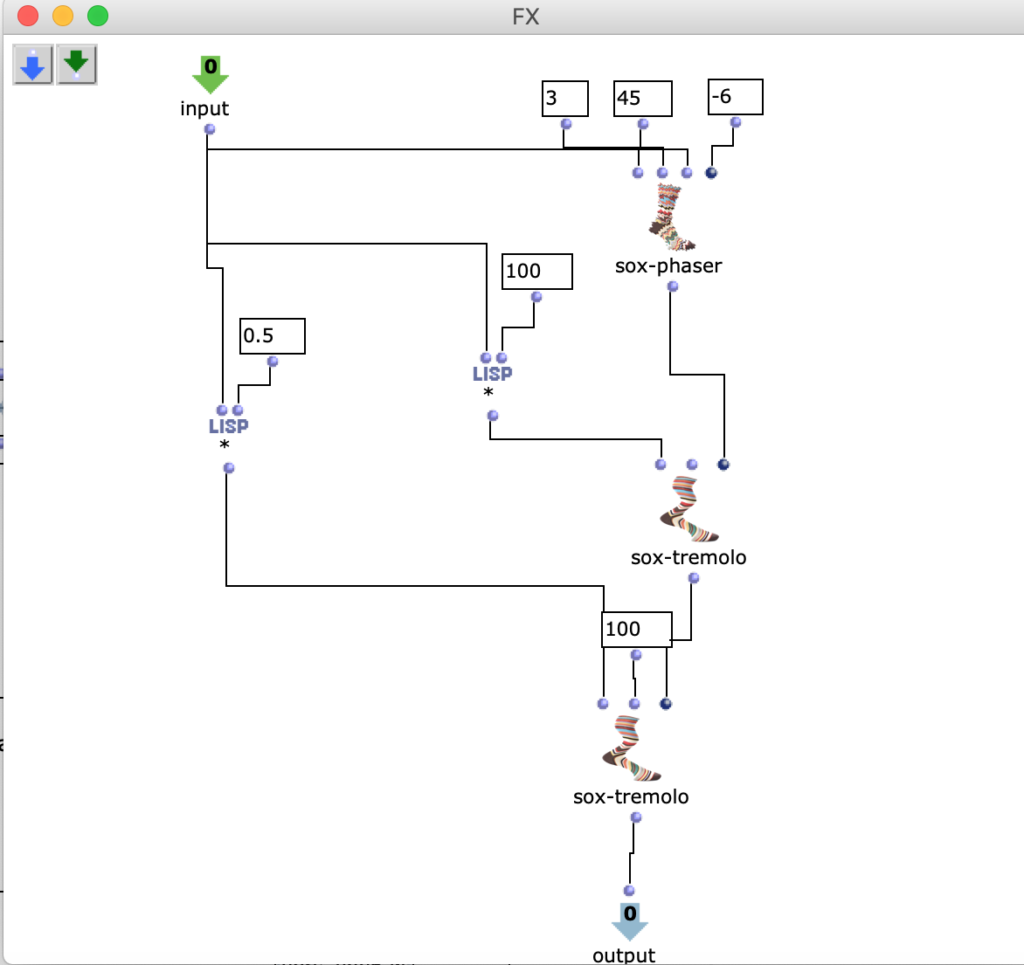
Die Drive, Reverb, Compressor sind Objekten, die ich nur damit man es leichter in dem Bild sehen kann, in Patch gepackt habe. Und Patch „FX“ sieht man in der Figur 10 .
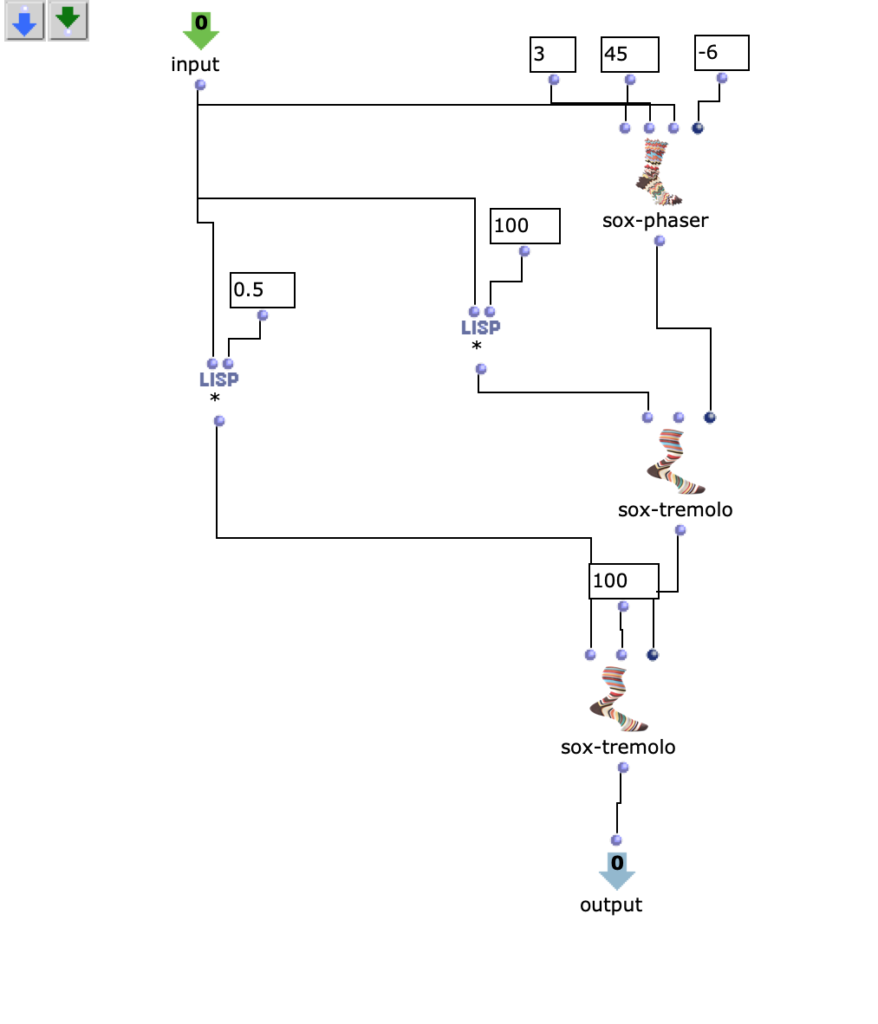
Fg. 11 zeigt OpenMusic Patch 5 Dieser Patch zeigt „FX“ Patch (s. Fg. 9)
Ich habe 3 Iterationen meinen Komposition gemacht. Mit diesen Iterationen ging ich auf die Themen Musik komponieren, Technik und Mixing tiefer ein. Die finale Version ist auch im 2 Kanal Format verfügbar:
Audio III: die dritte Iteration
Die 8-Kanal Version ist ? HIER verfügbar.
✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴✴




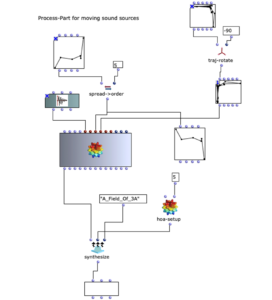

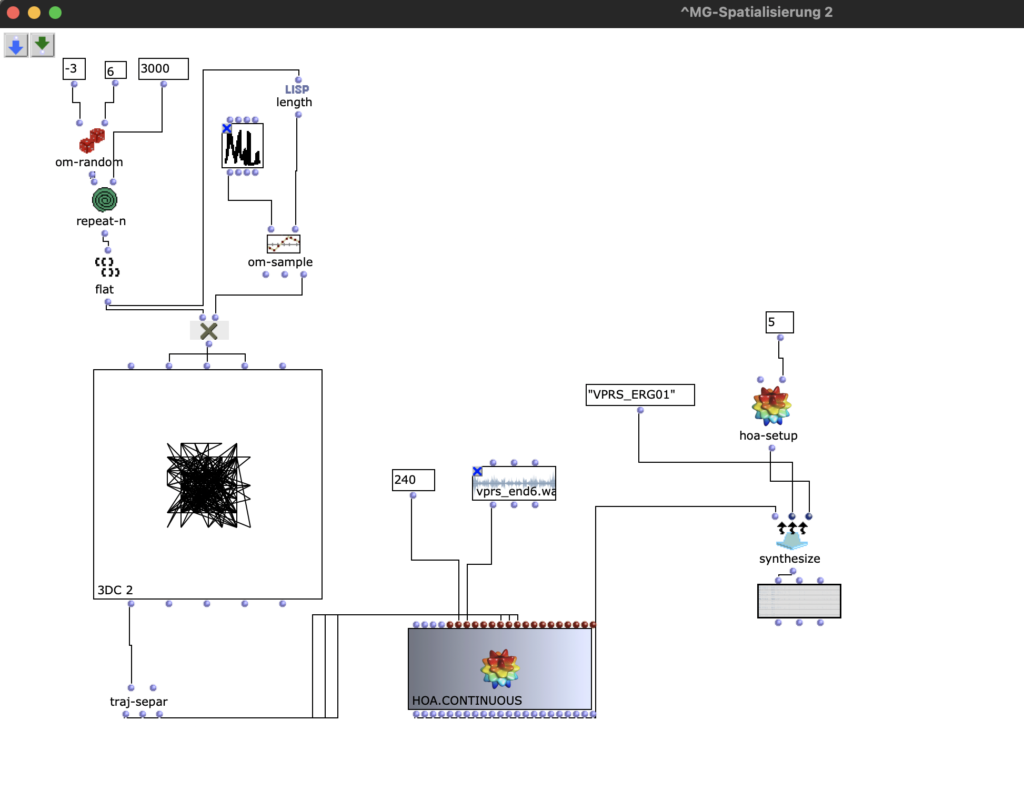
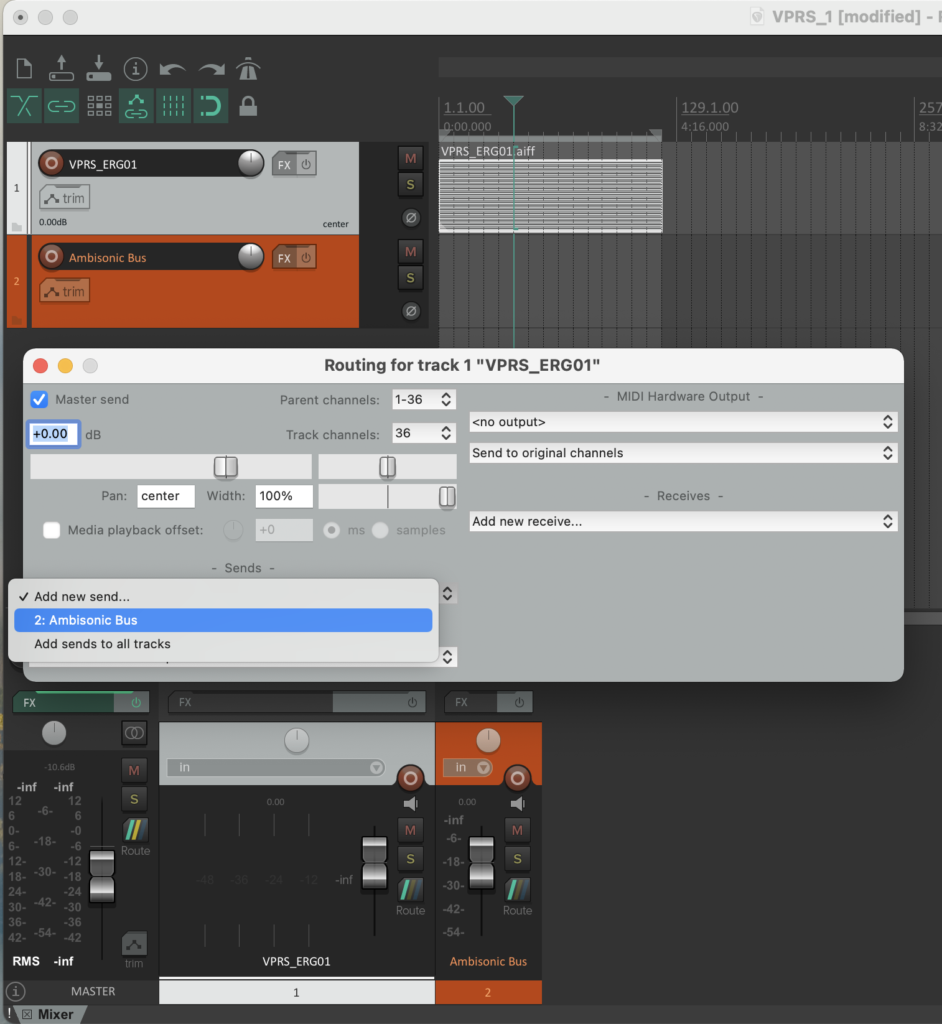
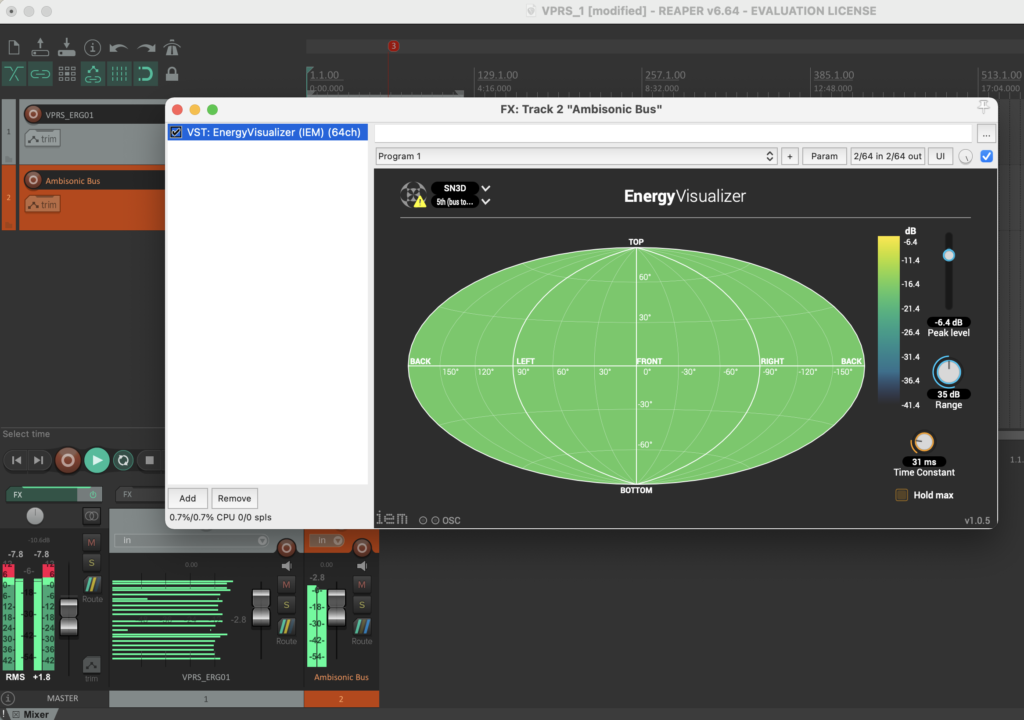
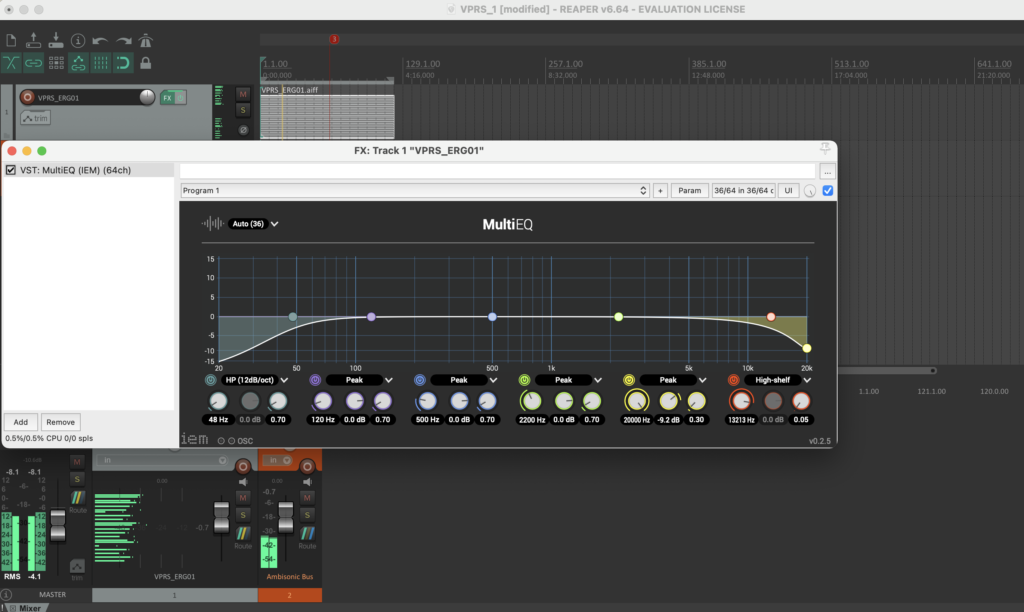
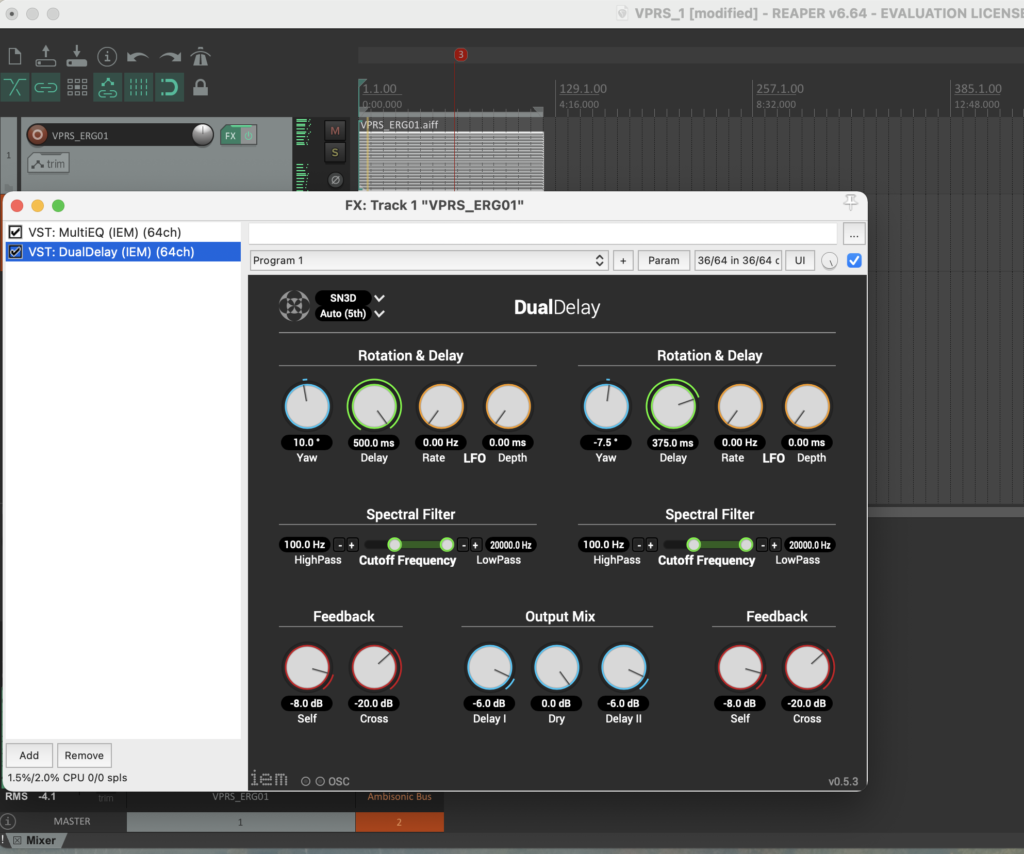
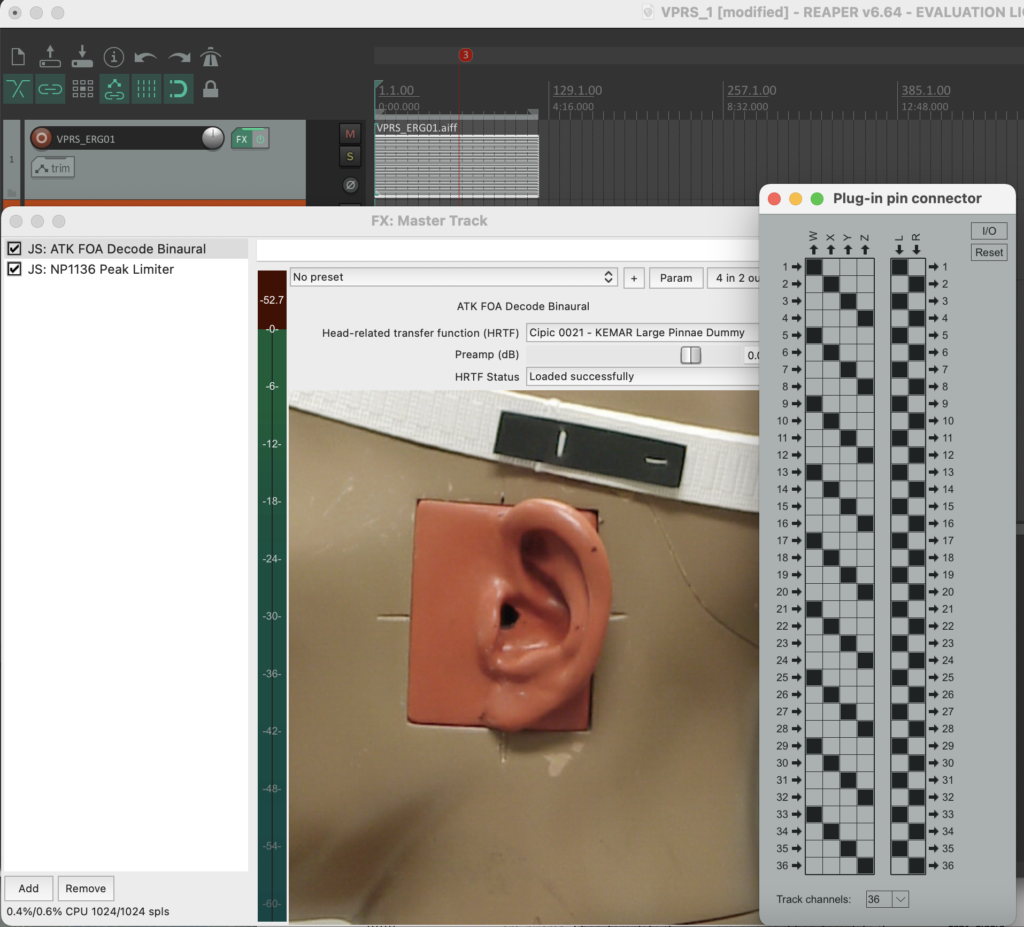
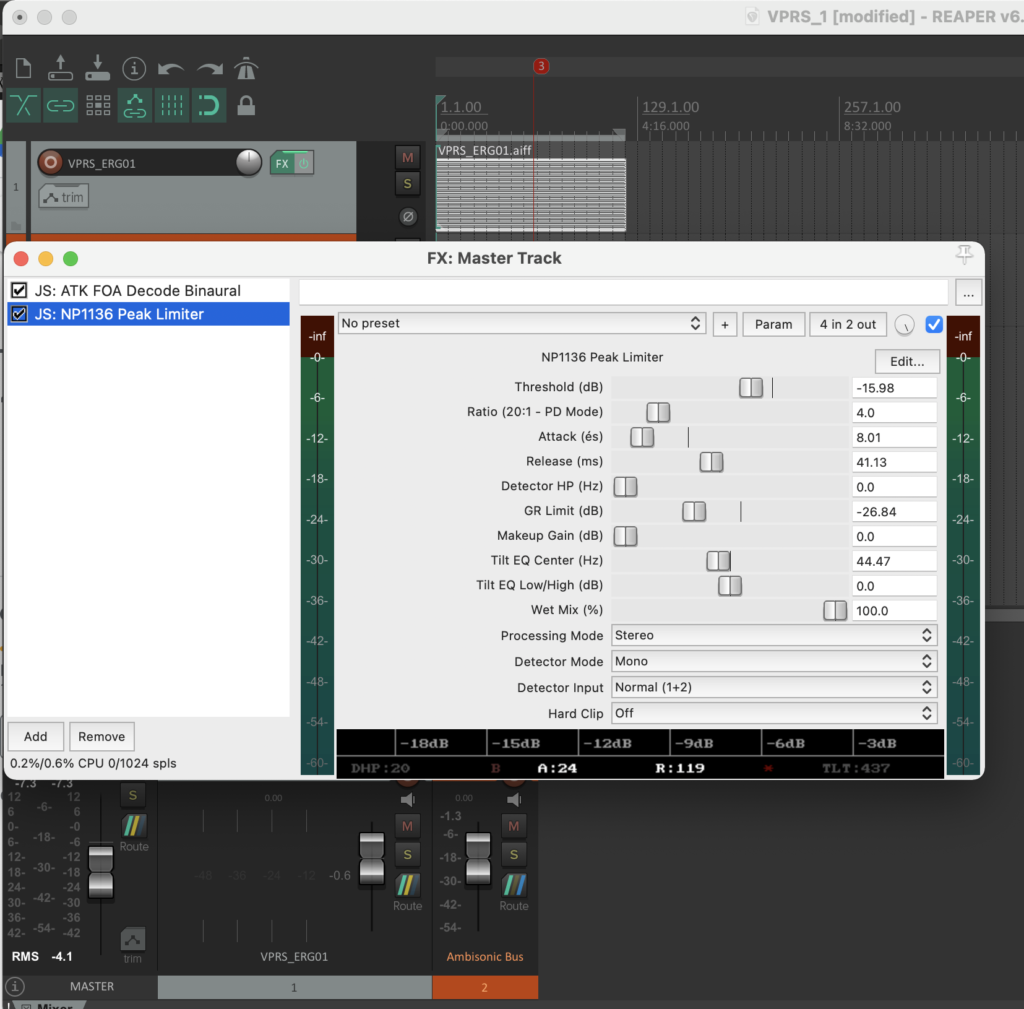
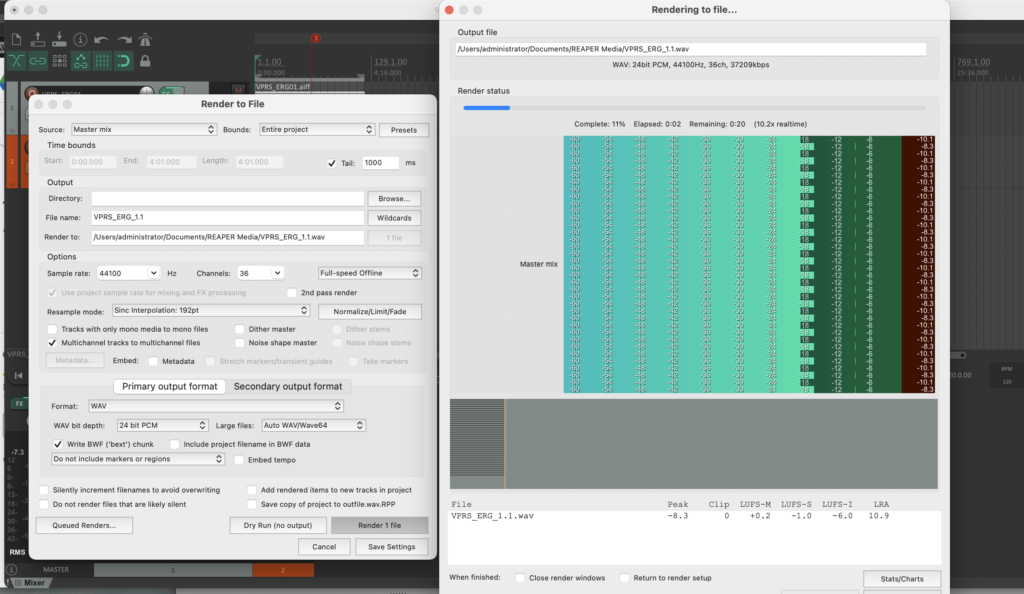

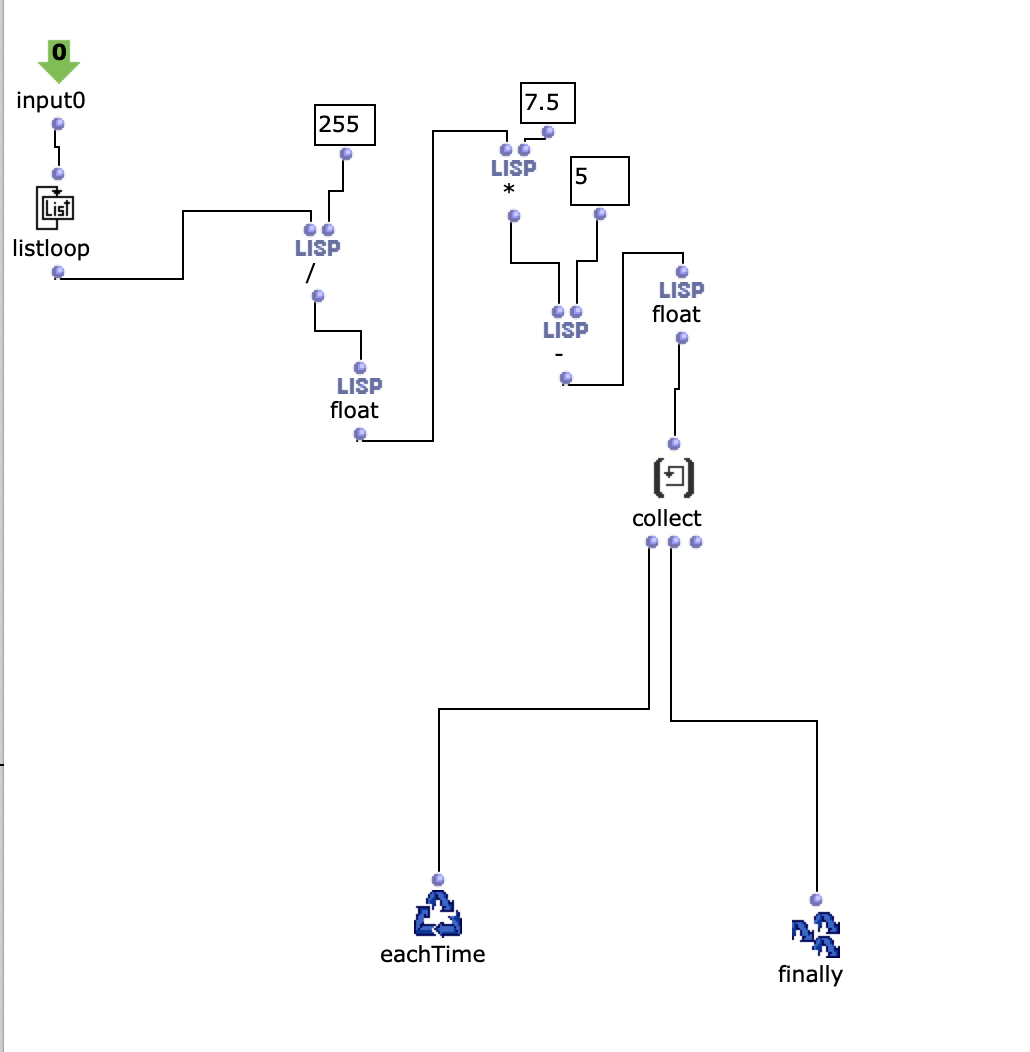
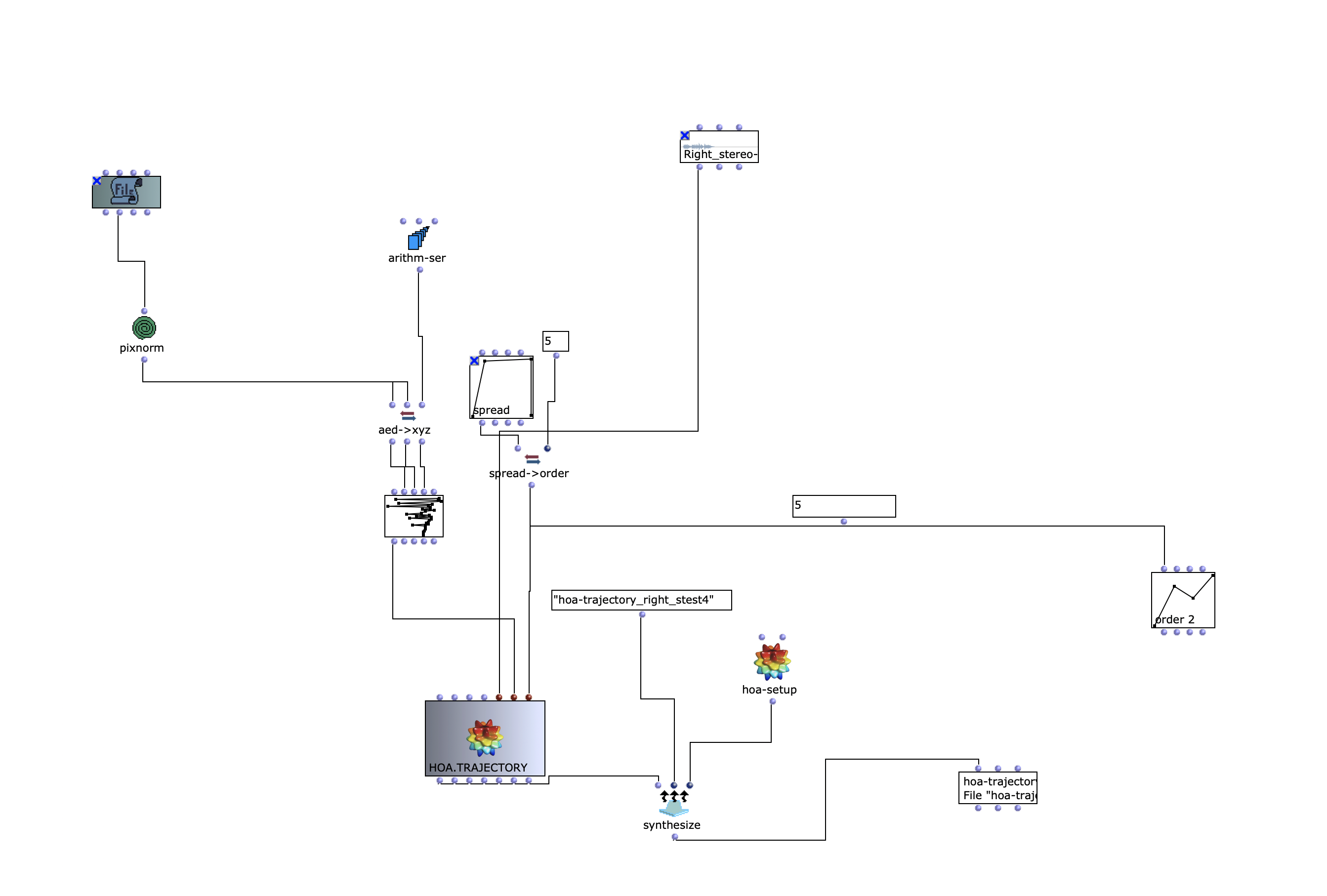
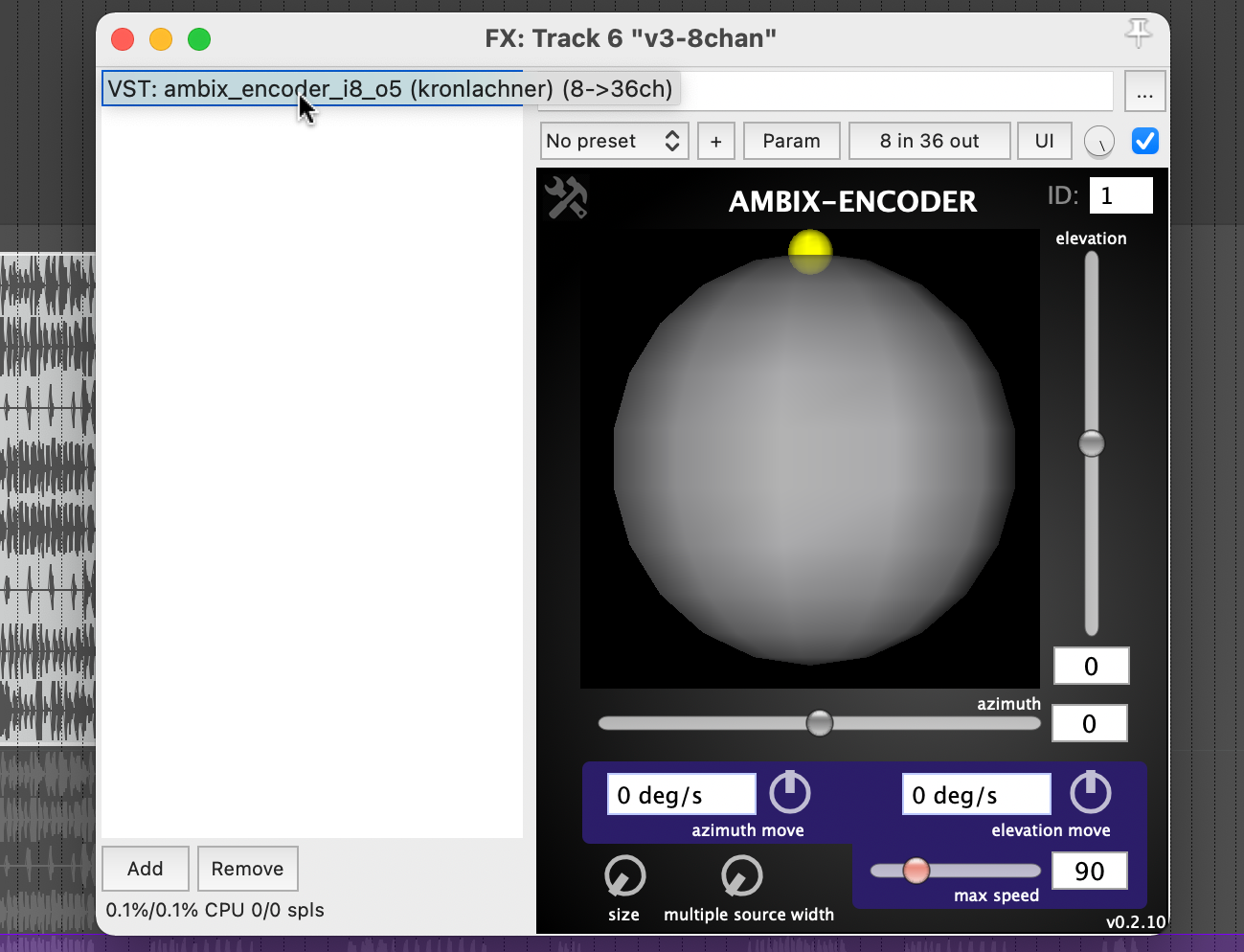
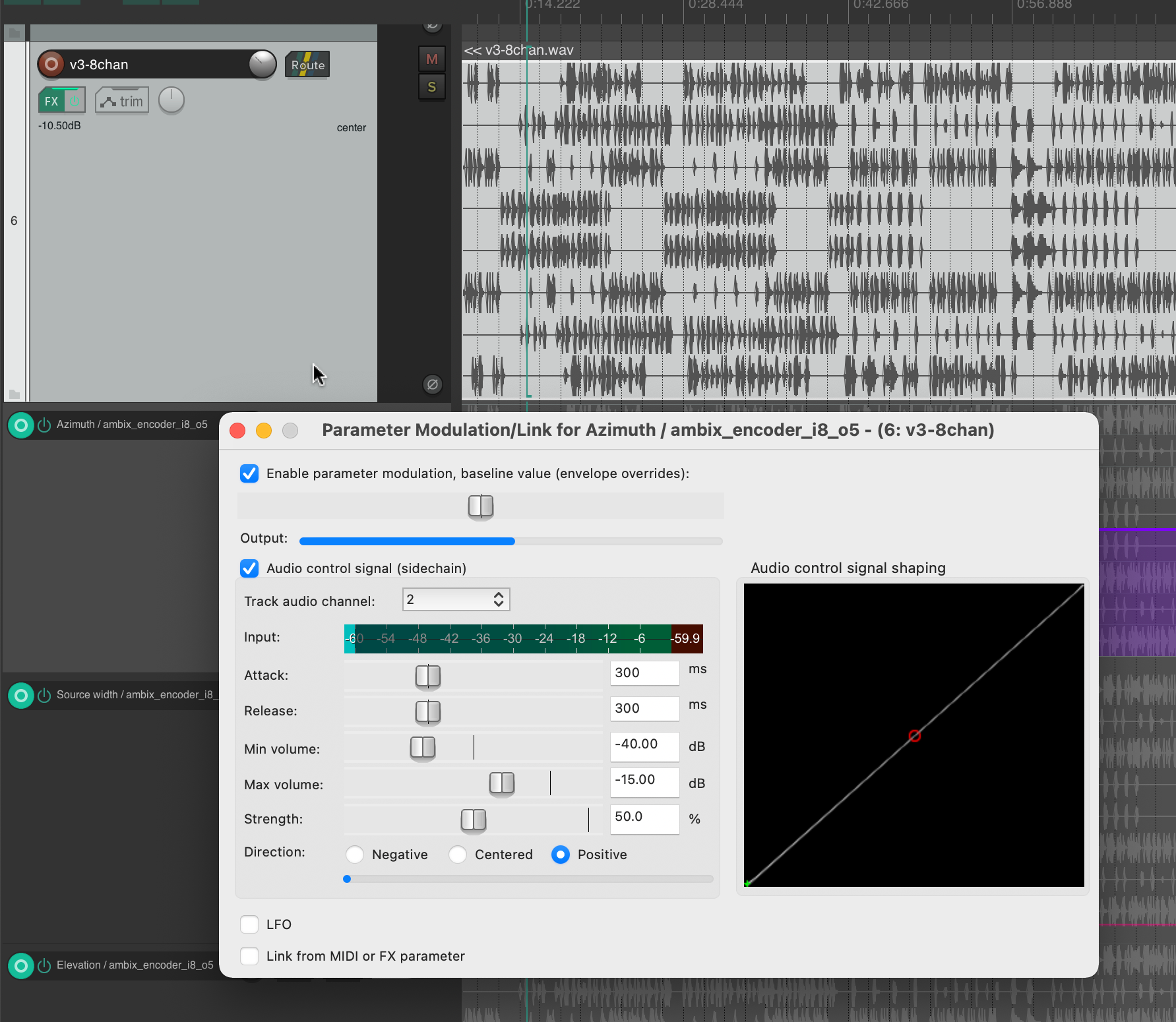
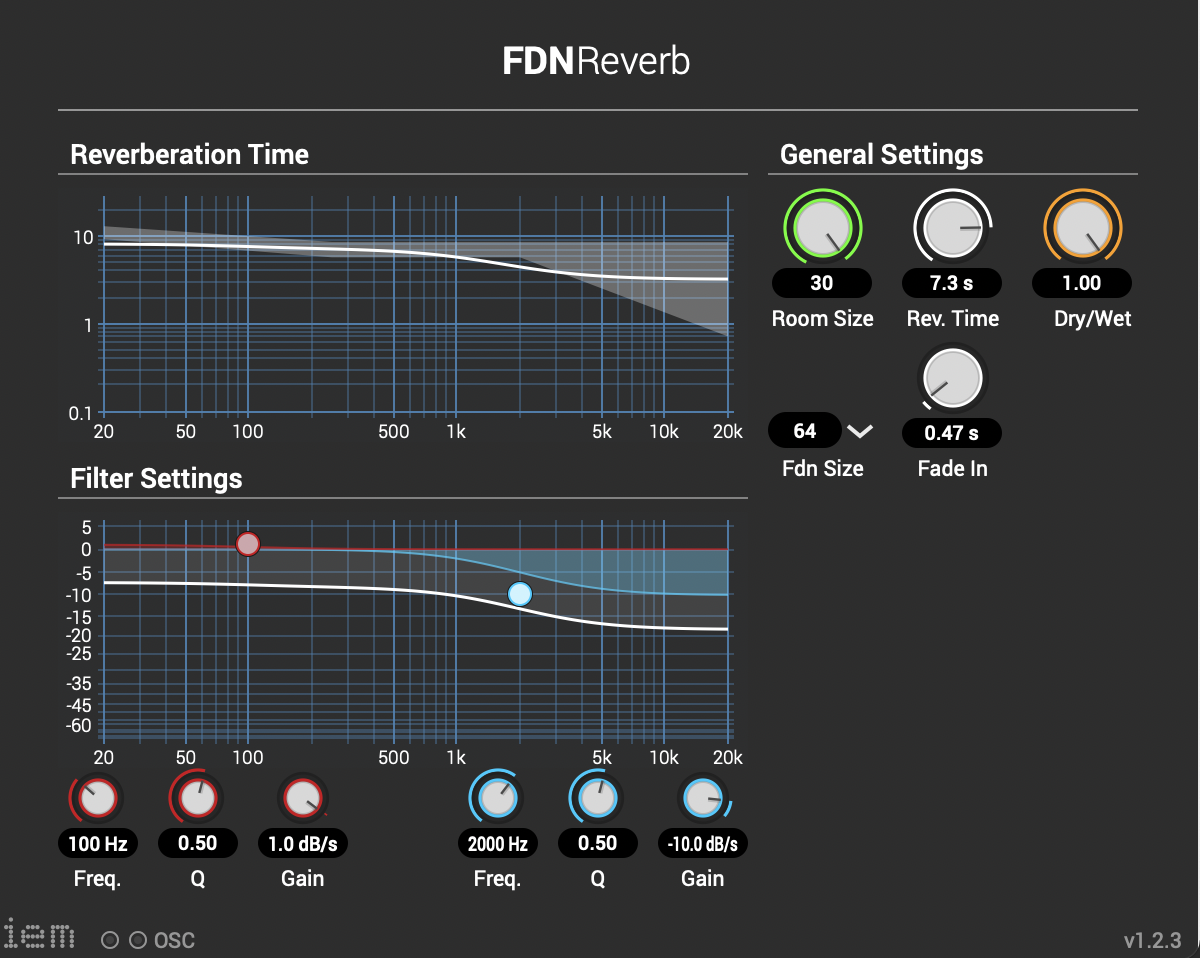 Die Stereo und Monofiles wurden zuerst in 5th Order Ambisonics Codiert (36 Kanäle) und schließlich mit dem binauralen Encoder in zwei Kanäle umgewandelt.
Die Stereo und Monofiles wurden zuerst in 5th Order Ambisonics Codiert (36 Kanäle) und schließlich mit dem binauralen Encoder in zwei Kanäle umgewandelt. 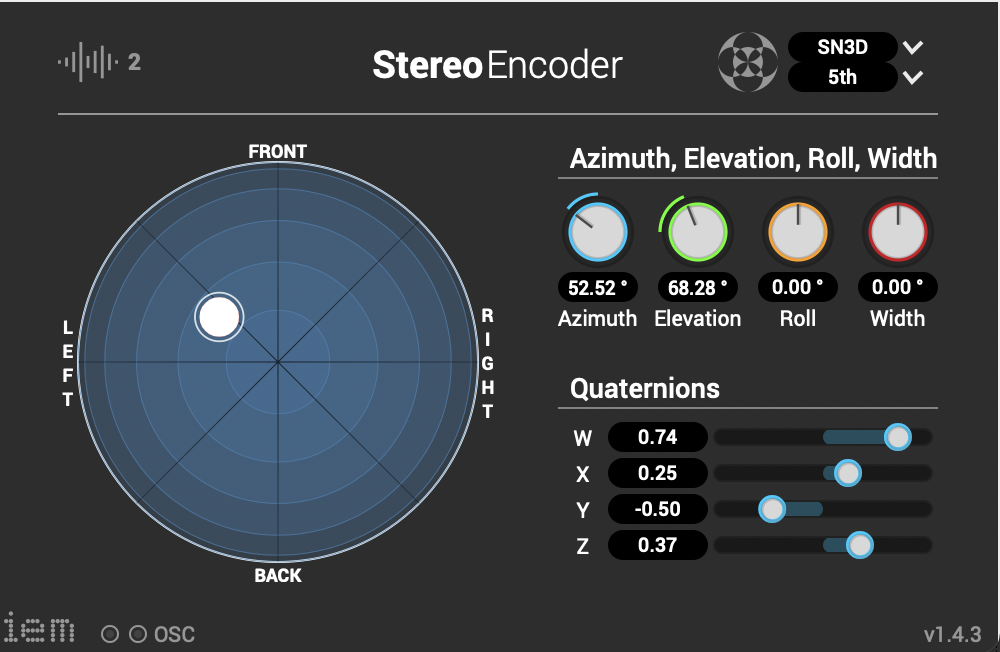
 Andere Effekte zur Nachbearbeitung(Detune, Reverb) wurden von mir selbst programmiert und sind auf Github verfügbar. Der Reverb basiert auf einen Paper von James A. Moorer About this Reverberation Business von 1979 und wurde in C++ geschrieben. Der Algorythmus vom Detuner wurde von der HTML Version vom Handbuch „The Theory and Technique of Electronic Music“ von Miller Puckette in C++ geschrieben. Das Ergebnis der letzen Iteration ist hier zu hören.
Andere Effekte zur Nachbearbeitung(Detune, Reverb) wurden von mir selbst programmiert und sind auf Github verfügbar. Der Reverb basiert auf einen Paper von James A. Moorer About this Reverberation Business von 1979 und wurde in C++ geschrieben. Der Algorythmus vom Detuner wurde von der HTML Version vom Handbuch „The Theory and Technique of Electronic Music“ von Miller Puckette in C++ geschrieben. Das Ergebnis der letzen Iteration ist hier zu hören.