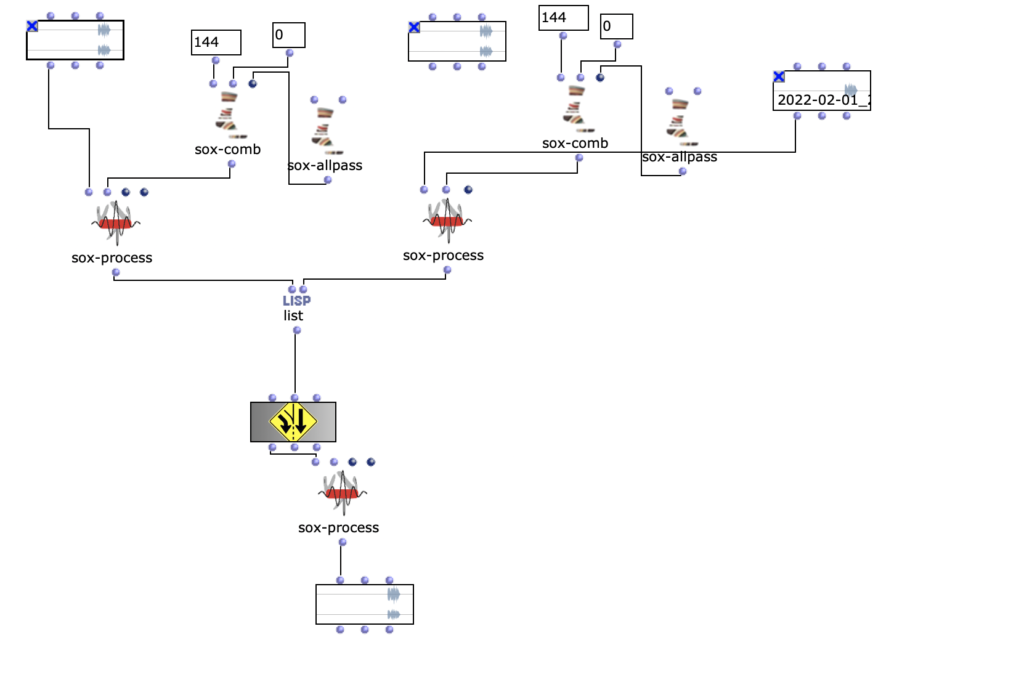
Dieser Beitrag handelt über die vierte Iteration einer akousmatischen Studie von Zeno Lösch, welche im Rahmen des Seminars „Visuelle Programmierung der Raum/Klangsynthese“ bei Prof. Dr. Marlon Schumacher an der HFM Karlsruhe durchgeführt wurden. Es wird über die grundlegende Konzeption, Ideen, aufbauende Iterationen sowie die technische Umsetzung mit OpenMusic behandelt.
Um Parameter zum Modulieren zu erhalten, wurde ein Python-Script verwendet.
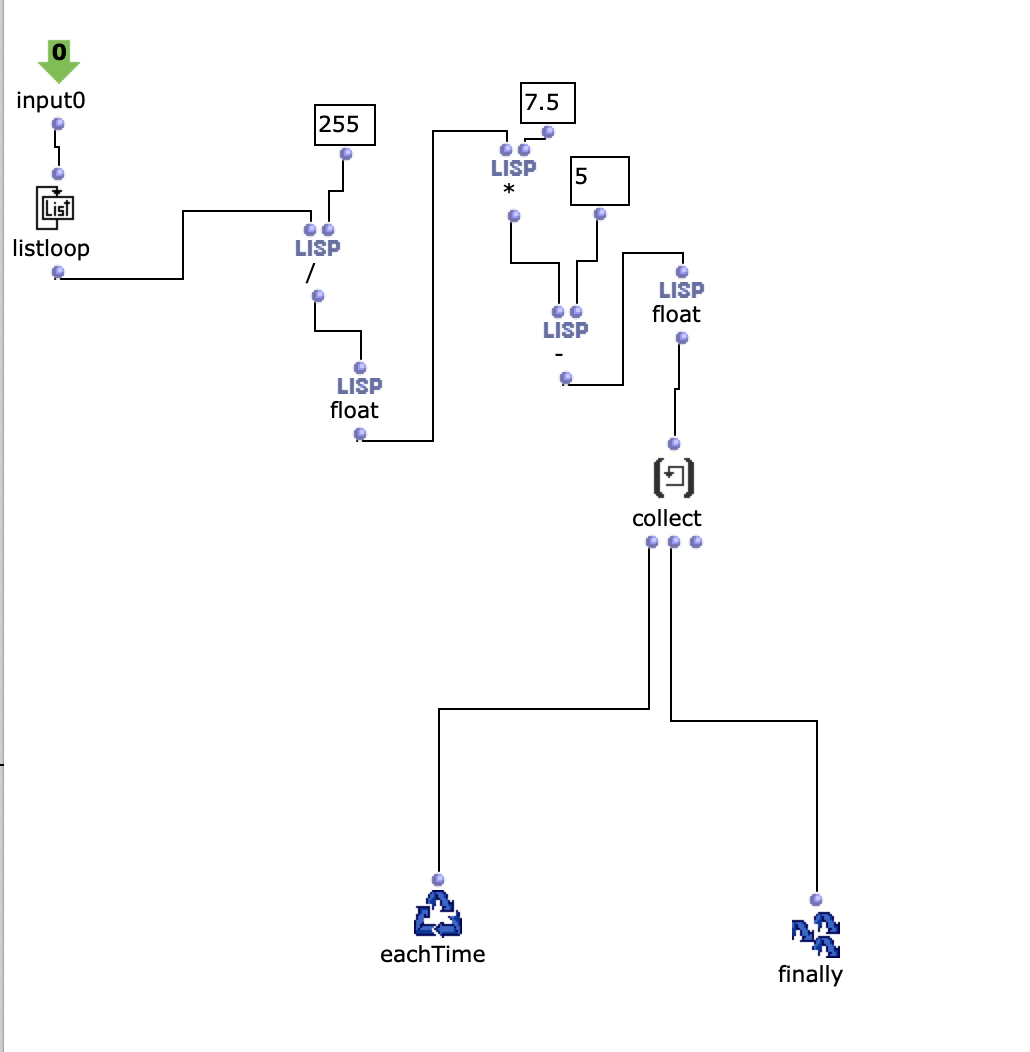
Dieses Script ermöglicht es ein beliebiges Bild auf 10 x 10 Pixel zu skalieren und die jeweiligen Pixel Werte in eine Text Datei zu speichern. „99 153 187 166 189 195 189 190 186 88 203 186 198 203 210 107 204 143 192 108 164 177 206 167 189 189 74 183 191 110 211 204 110 203 186 206 32 201 193 78 189 152 209 194 47 107 199 203 195 162 194 202 192 71 71 104 60 192 87 128 205 210 147 73 90 67 81 130 188 143 206 43 124 143 137 79 112 182 26 172 208 39 71 94 72 196 188 29 186 191 209 85 122 205 198 195 199 194 195 204 “ Die Werte in der Textdatei sind zwischen 0 und 255. Die Textdatei wird in Open Music importiert und die Werte werden skaliert.
Diese skalierten Werte werden als pos-env Parameter verwendet.
Reaper und IEM-Plugin Suite
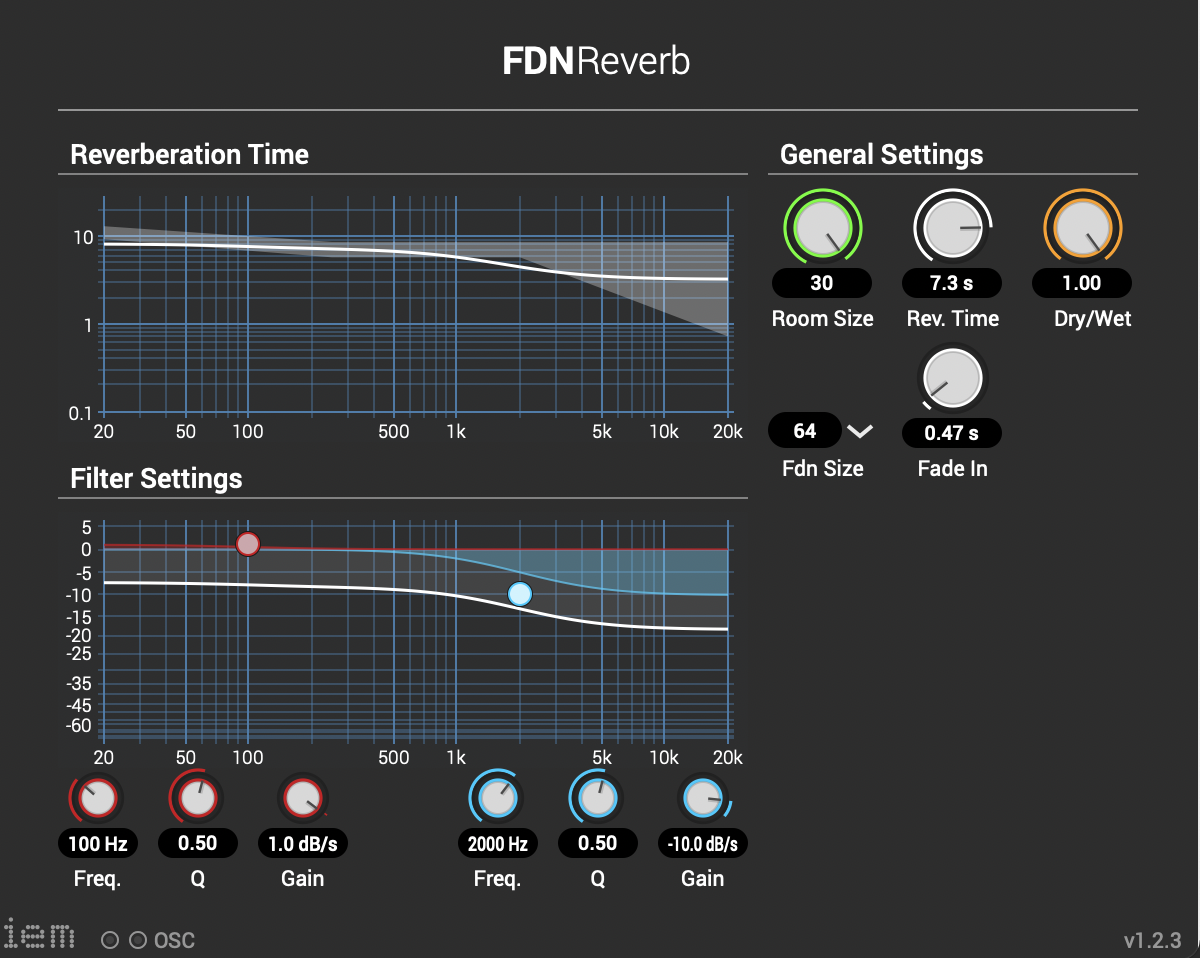
Mit verschiedenen Bildern und verschiedenen Skalierungen erhält man verschiedene Ergebnisse die für man als Parameter für Modulation verwenden kann. In Reaper wurden bei der Postproduktion die IEM-Plugin-Suite verwendet. Diese Tools verwendet man für Ambisonics von verschiedenen Ordnungen. In diesem Fall wurde Ambisonics 5 Ordnung angewendet. Ein Effekt der oft verwendet wurde ist der FDNReverb. Dieses Hallgerät bietet die Möglichkeit einen Ambisonics Reverb auf ein Mulikanal-File anzuwenden. Die Stereo und Monofiles wurden zuerst in 5th Order Ambisonics Codiert (36 Kanäle) und schließlich mit dem binauralen Encoder in zwei Kanäle umgewandelt. Andere Effekte zur Nachbearbeitung(Detune, Reverb) wurden von mir selbst programmiert und sind auf Github verfügbar. Der Reverb basiert auf einen Paper von James A. Moorer About this Reverberation Business von 1979 und wurde in C++ geschrieben. Der Algorythmus vom Detuner wurde von der HTML Version vom Handbuch „The Theory and Technique of Electronic Music“ von Miller Puckette in C++ geschrieben. Das Ergebnis der letzen Iteration ist hier zu hören. Alex Player - Best audio player
Momentan umfasst die Library zwei Funktionen, die sowohl mit CommonLisp, als auch mit schon bestehenden Funktionen aus dem OM-Package geschrieben sind.
Zudem ist die Komposition im Umfang der zu kontollierenden Parametern, momentan auf die Harmonik und die Stimmführung begrenzt.
Für die Zukunft möchte ich ebenfalls eine Funktion schreiben, welche mit den Parametern Metrik und Einsatzabstände, die Komposition auch auf zeitlicher Ebene erlaubt.
Entwicklung: Lorenz Lehmann
Betreuung und Beratung: Prof. Dr. Marlon Schumacher
Mein herzlicher Dank für die freundliche Unterstützung gilt Joseph Branciforte und
I present in this article residual – i, a three-minute solo piece for prepared piano commissioned as a companion work to John Cage’s Sonatas and Interludes for prepared piano. In analyzing Cage’s work and subsequently composing a companion to it, I employed a self-designed texture synthesis tool driven by machine learning clustering. The technical overview of that tool can be read at this other blogpost, or in the proceedings of the 2022 International Conference on Technologies for Music Notation and Representation (TENOR 2022). The blogpost you are reading now will briefly explain how that tool (and generally, music informatics) was applied in composing this short piano piece.
Background
John Cage’s Sonatas and Interludes (1946-48) is a 60-minute work for solo prepared piano that involves placing various objects (metal screws, bolts, nuts, pieces of plastic, rubber and eraser) in the strings of the piano. These objects ‚prepare‘ the piano, altering its sound and bringing out a variety of different, heterogenous timbres. Some keys produce chords, others buzz, or even have the pitch completely removed. The sound profile of the Sonatas and Interludes are arguably the work’s most iconic aspect.
However, the form of the Sonatas and Interludes is also noteworthy. The work consists of sixteen sonatas and four interludes, with most movements lasting somewhere between 1 and 4 minutes each. As part of an ongoing commissioning project, pianist and composer Amy Williams premieres new ‚interludes‘ which are placed amidst the existing sonatas and interludes by Cage. In early 2022 I received the opportunity to compose a short piece that would use a piano with Cage’s „preparations“, and would be inserted as an interlude amidst the sonatas and interludes of Cage’s work.
Approach
I was interested in composing a piece that acknowledged both the sound- and time-identity of the Sonatas and Interludes. While arguably the most iconic aspect of Cage’s Sonatas and Interludes is its sounds, I feel that the work’s form, it’s time-based content, is equally impactful. Many of the its movements are cast in AABB form, reflecting classical period sonatas. Additionally, the distribution of the individual sonatas and interludes take a symmetrical form: four groups of four sonatas each, partitioned by the four interludes:
As a pre-compositional constraint, I decided that all sonorities in my piece would be taken/excerpted directly from the score of the Cage. To use the metaphor of a painter, the score of the Cage was my palette of colors, and not the prepared piano itself. This meant that not only every chord or single note in my piece would be excerpted from the Cage, it also meant that the chord or note’s particular duration would also be used in my piece. The sound and duration were joined as a single item. In a way, my piece was a form of granular synthesis, taking single-attack grains of the Sonatas and Interludes, and recontextualizing them in a new order.
Preprocessing
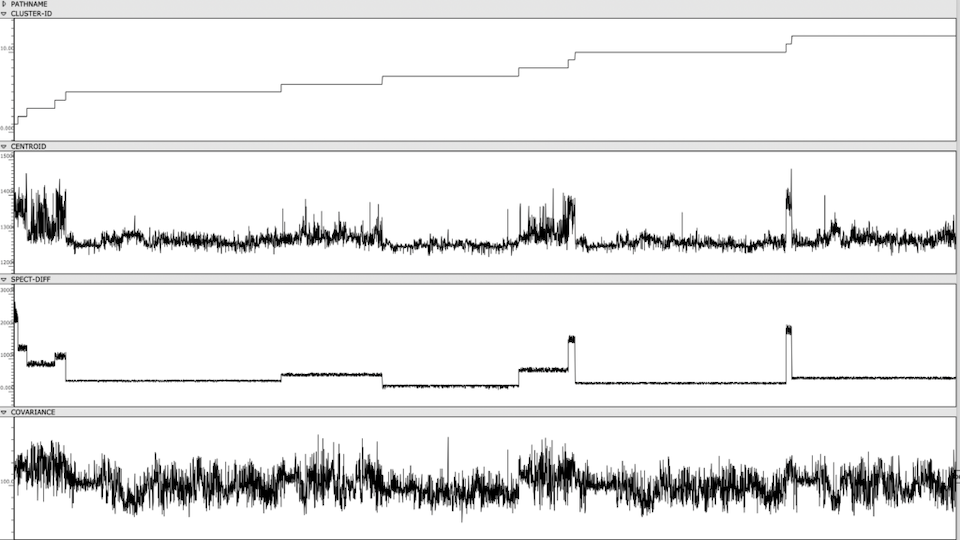
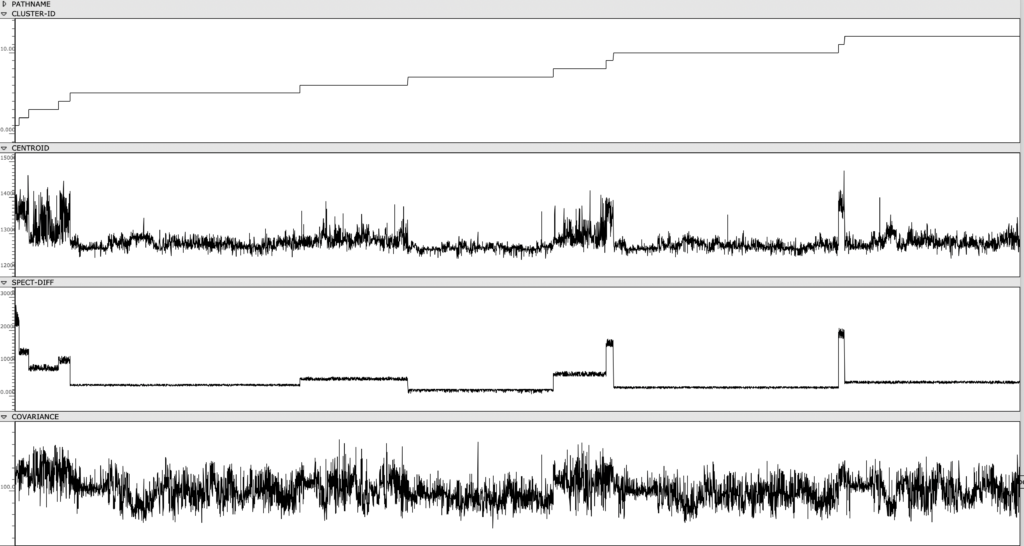
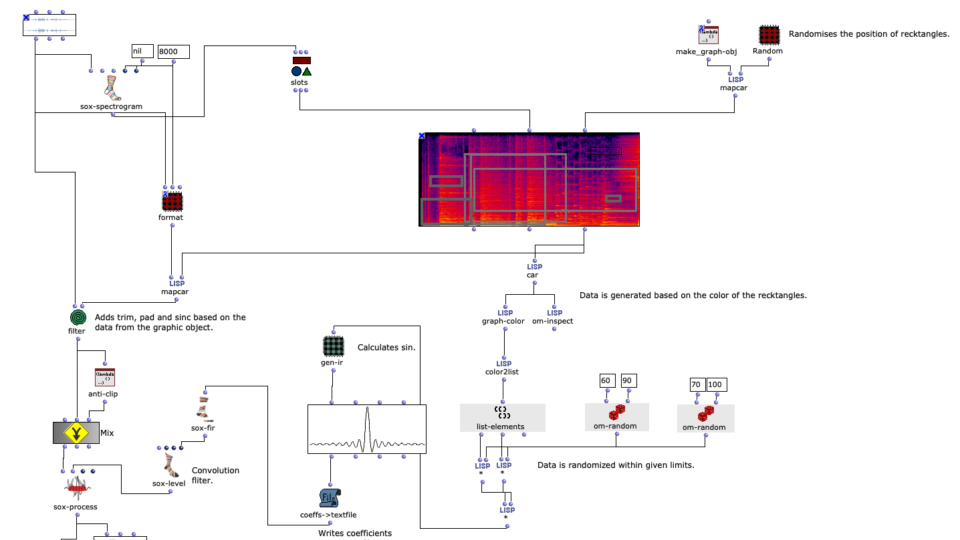
In order to observe and meaningfully comprehend all the individual sonorities in the 60-minute-long Cage, I used a simple machine learning clustering method to categorize all ~7k sonorities into 12 groups. Using my texture synthesis tool, I was not only able to organize audio features of these ~7k sonorities in a a visual editor, I was also able to export and listen to each individual sonority as a single, short audio file.
Figure 1: Clusters and audio features are visually represented and sorted, providing an out-of-time view of the Cage’s spectral content.
Once the sonorities have been extracted as individual transients, I used a k-means clustering method to sort these sonorities into 12 clusters. To briefly explain this machine learning method, the clustering algorithm receives a vector of several audio features as an input representing a sonority from the Cage (the audio features used were spectral centroid, spectral difference, and spectral covariance*). The algorithm then sorts these audio vectors into 12 groups, placing sounds with similar vector-values in the same group. This process in unsupervised, meaning it is not seeking to emulate a trained result that I predetermined. Rather, because these three audio features, as a trio, don’t represent any particularly given parameter in music, the algorithm returns clusters of sound that are correlated along multifaceted sound profiles that are aurally cohesive but not as simple as being sorted by a single parameter like pitch, duration, brightness, or noisiness.
Composition
My piece residual – i uses sonorities exclusively from clusters 2, 4, 9, 11. Referring back to the class-array figure, there is a clear line of differentiation between these clusters and the rest, correlated specifically to the spectral difference of the sonorities. These sonorities had an unusually high spectral difference, due either to their bright harmonic content (which creates a sharp delta between the attack and sustain of the transient) or their short duration (which creates a sharp delta between the attack and sustain/resonance of the transient). By placing each of these clusters in sequence, and the sounds within each cluster in sequence, this quality of shortness and brightness is clearly audible (see audio).
I treated this sequence as a kind of DNA for the piece. Large portions of it were copied into the score (sequences of around 20-30 transients. This process was done by hand, listening to each individual transient in the sequence, and looking up in the score of the Cage what the corresponding notes were). It was at this point that the machine learning methods involved in the piece are finished. From here, I began to sculpt and shape these longer sequences into shorter bursts. I also added repeat brackets at different moments, creating moments of ‚freeze‘ in the piece’s hurtling forward momentum.
Figure 3a: Loop A designates the first several (circa 20) sonorities in the cluster sequence, looped over and over. This sequence served as a scaffolding from which the piece was composed around.
Figure 3b: This is the same page of the score, after notes have been removed, transforming the work into short bursts of sound.
Conclusion
Many of the cutting edge applications of machine learning in audio are towards the improvement of automated transcription, neural audio synthesis, and other tasks which have a clear goal and benchmark to test against. My particular application of machine learning in this piece is not for optimizing any task like this. Rather, the act of clustering audio served more as a means to explore the Sonatas and Interludes from a vantage point that I had not yet seen them from. Similar to my previous works that involve machine learning, being aware of how the machine learning methods are implemented is an essential first step in mindfully composing a work using such methods. As suggested by the title, residual – i serves as a proof of concept for a possible larger set of companion pieces, in which machine learning methods are used as a means to critically reexamine and „re-hear“ a familiar piece of music.
Listen to a full performance of residual – i here.
*These three features are measurements typically used to categorize the timbre and spectral content of an audio signal. The spectral centroid represents the center of mass in a spectrum. The spectral difference represents the average delta in energy between adjacent windows of the spectrum. The spectral covariance represents the spectral variability of a signal, i.e. how much the signal varies between its frequency bins.
Inspiriert vom „Infinite Bad Guy“ Projekt und all den sehr unterschiedlichen Versionen, wie manche Leute ihre Fantasie zu diesem Song beflügelt haben, dachte ich, vielleicht könnte ich auch damit experimentieren, eine sehr lockere, instrumentale Coverversion von Billie Eilish’s „Bad Guy“ zu erstellen.
Betreuer: Prof. Dr. Marlon Schumacher
Eine Studie von: Kaspars Jaudzems
Wintersemester 2021/22
Hochschule für Musik, Karlsruhe
Zur Studie:
Ursprünglich wollte ich mit 2 Audiodateien arbeiten, eine FFT-Analyse am Original durchführen und dessen Klanginhalt durch Inhalt aus der zweiten Datei „ersetzen“, lediglich basierend auf der Grundfrequenz. Nachdem ich jedoch einige Tests mit einigen Dateien durchgeführt hatte, kam ich zu dem Schluss, dass diese Art von Technik nicht so präzise ist, wie ich es gerne hätte. Daher habe ich mich entschieden, stattdessen eine MIDI-Datei als Ausgangspunkt zu verwenden.
Sowohl die erste als auch die zweite Version meines Stücks verwendeten nur 4 Samples. Die MIDI-Datei hat 2 Kanäle, daher wurden 2 Dateien zufällig für jede Note jedes Kanals ausgewählt. Das Sample wurde dann nach oben oder unten beschleunigt, um dem richtigen Tonhöhenintervall zu entsprechen, und zeitlich gestreckt, um es an die Notenlänge anzupassen.
Die zweite Version meines Stücks fügte zusätzlich einige Stereoeffekte hinzu, indem 20 zufällige Pannings für jede Datei vor-generiert wurden. Mit zufällig angewendeten Kammfiltern und Amplitudenvariationen wurde etwas mehr Nachhall und menschliches Gefühl erzeugt.
Akusmatische Studie Version 1
Akusmatische Studie Version 2
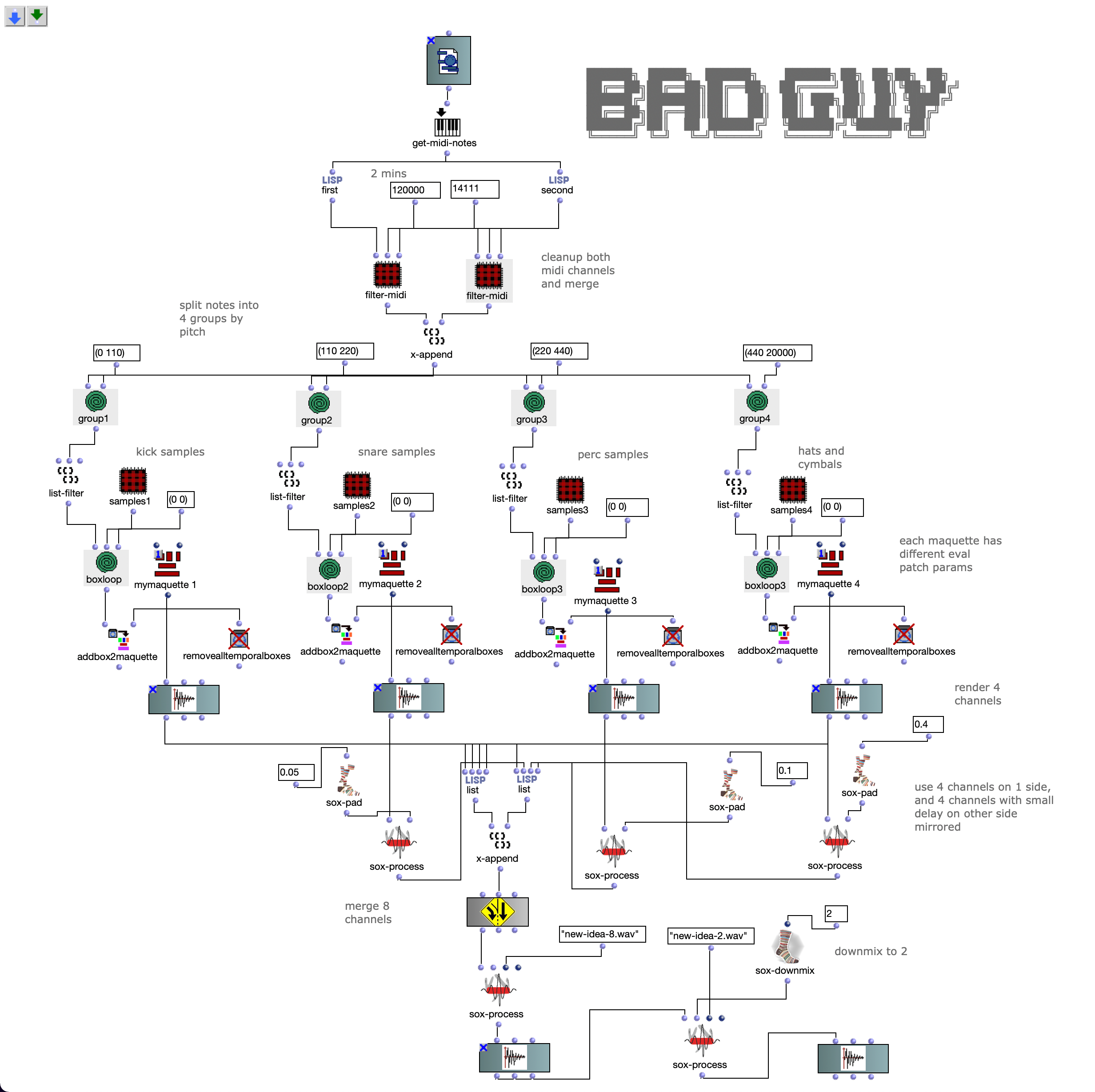
Die dritte Version war eine viel größere Änderung. Hier werden die Noten beider Kanäle zunächst nach Tonhöhe in 4 Gruppen eingeteilt. Jede Gruppe umfasst ungefähr eine Oktave in der MIDI-Datei.
Dann wird die erste Gruppe (tiefste Töne) auf 5 verschiedene Kick-Samples abgebildet, die zweite auf 6 Snares, die dritte auf perkussive Sounds wie Agogo, Conga, Clap und Cowbell und die vierte Gruppe auf Becken und Hats, wobei insgesamt etwa 20 Samples verwendet werden. Hier wird eine ähnliche Filter-und-Effektkette zur Stereoverbesserung verwendet, mit dem Unterschied, dass jeder Kanal fein abgestimmt ist. Die 4 resultierenden Audiodateien werden dann den 4 linken Audiokanälen zugeordnet, wobei die niedrigeren Frequenzen kanale zur Mitte und die höheren kanale zu den Seiten sortiert werden. Für die anderen 4 Kanäle werden dieselben Audiodateien verwendet, aber zusätzliche Verzögerungen werden angewendet, um Bewegung in das Mehrkanalerlebnis zu bringen.
Akusmatische Studie Version 3
Die 8-Kanal-Datei wurde auf 2 Kanäle in 2 Versionen heruntergemischt, einer mit der OM-SoX-Downmix-Funktion und der andere mit einem Binauralix-Setup mit 8 Lautsprechern.
Akusmatische Studie Version 3 – Binauralix render
Erweiterung der akousmatischen Studie – 3D 5th-order Ambisonics
Die Idee mit dieser Erweiterung war, ein kreatives 36-Kanal-Erlebnis desselben Stücks zu schaffen, also wurde als Ausgangspunkt Version 3 genommen, die nur 8 Kanäle hat.
Ausgangspunkt Version 3
Ich wollte etwas Einfaches machen, aber auch die 3D-Lautsprecherkonfiguration auf einer kreativen weise benutzen, um die Energie und Bewegung, die das Stück selbst bereits gewonnen hatte, noch mehr hervorzuheben. Natürlich kam mir die Idee in den Sinn, ein Signal als Quelle für die Modulation von 3D-Bewegung oder Energie zu verwenden. Aber ich hatte keine Ahnung wie…
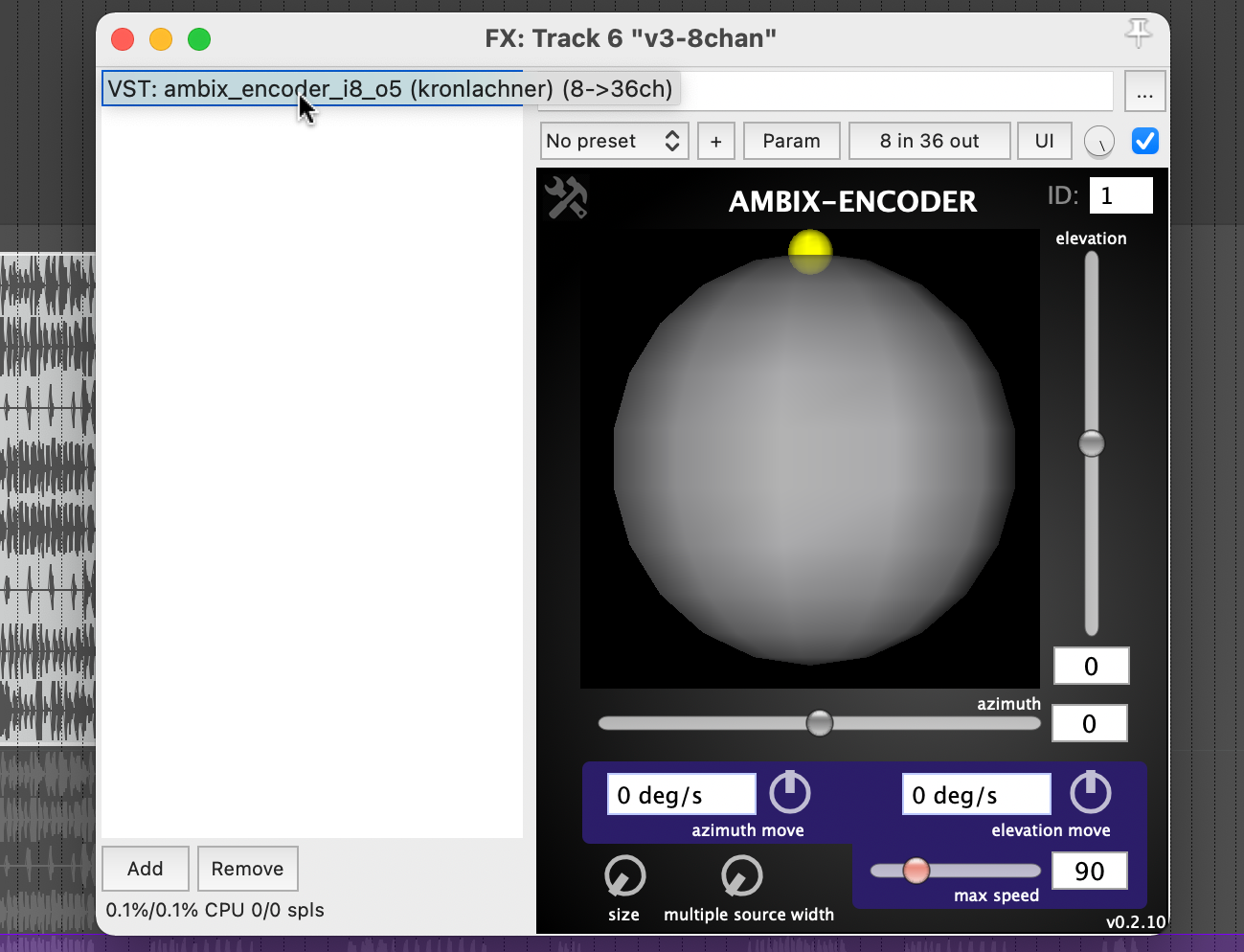
Plugin „ambix_encoder_i8_o5 (8 -> 36 chan)“
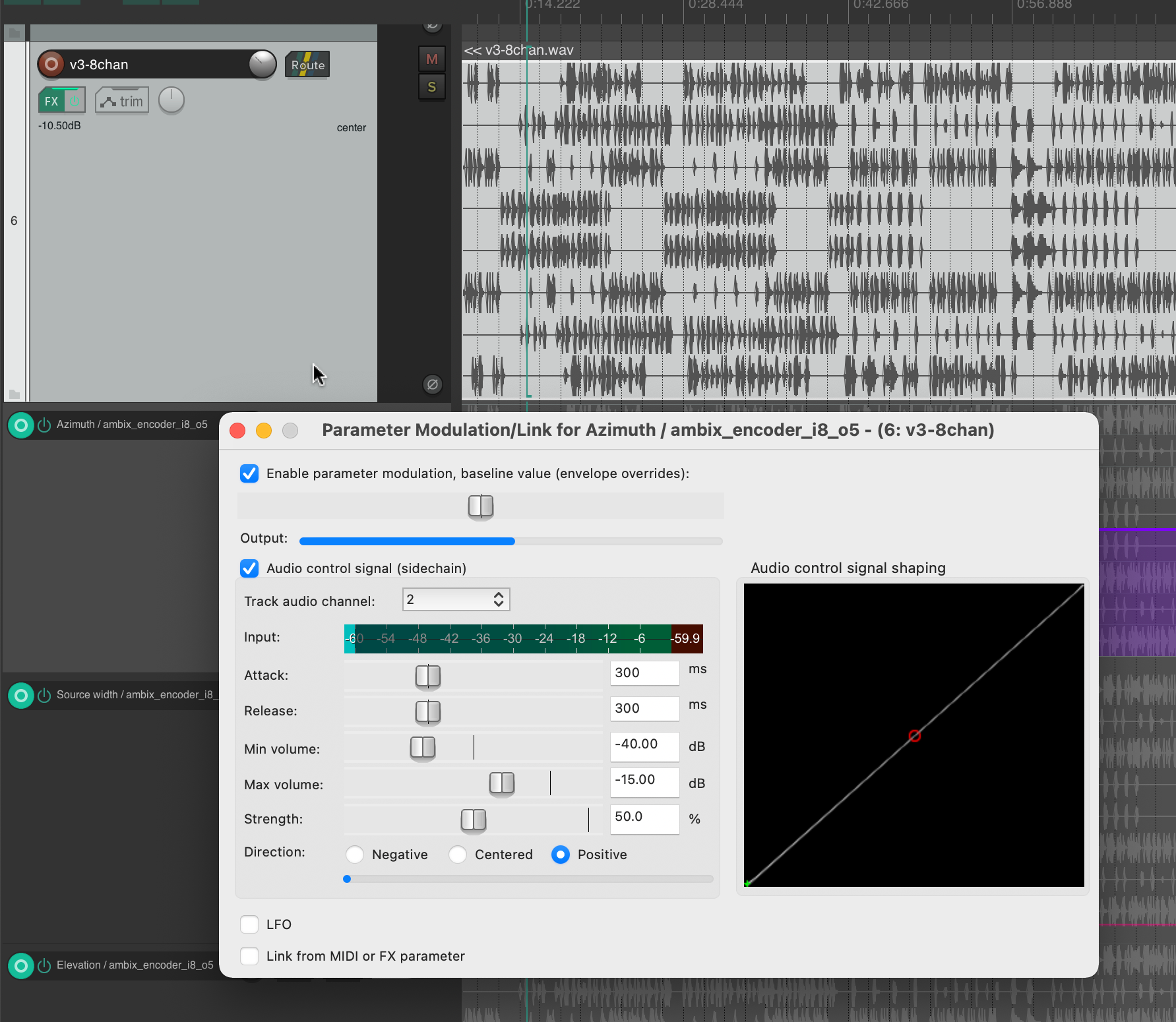
Bei der Recherche zur Ambix Ambisonic Plugin (VST) Suite bin ich auf das Plugin „ambix_encoder_i8_o5 (8 -> 36 chan)“ gestoßen. Dies schien aufgrund der übereinstimmenden Anzahl von Eingangs- und Ausgangskanälen perfekt zu passen. In Ambisonics wird Raum/Bewegung aus 2 Parametern übersetzt: Azimuth und Elevation. Energie hingegen kann in viele Parameter übersetzt werden, aber ich habe festgestellt, dass sie am besten mit dem Parameter Source Width ausgedrückt wird, weil er die 3D-Lautsprecherkonfiguration nutzt, um tatsächlich „nur“ die Energie zu erhöhen oder zu verringern.
Da ich wusste, welche Parameter ich modulieren muss, begann ich damit zu experimentieren, verschiedene Spuren als Quelle zu verwenden. Ehrlich gesagt war ich sehr froh, dass das Plugin nicht nur sehr interessante Klangergebnisse lieferte, sondern auch visuelles Feedback in Echtzeit. Bei der Verwendung beider habe ich mich darauf konzentriert, ein gutes visuelles Feedback zu dem zu haben, was im Audiostück insgesamt vor sich geht.
Dies half mir, Kanal 2 für Azimuth, Kanal 3 für Source Width und Kanal 4 für Elevation auszuwählen. Wenn wir diese Kanäle auf die ursprüngliche Eingabe-Midi-Datei zurückverfolgen, können wir sehen, dass Kanal 2 Noten im Bereich von 110 bis 220 Hz, Kanal 3 Noten im Bereich von 220 bis 440 Hz und Kanal 4 Noten im Bereich von 440 bis 20000 Hz zugeordnet ist. Meiner Meinung nach hat diese Art der Trennung sehr gut funktioniert, auch weil die Sub-bass frequenzen (z. B. Kick) nicht moduliert wurden und auch nicht dafur gebraucht waren. Das bedeutete, dass der Hauptrhythmus des Stücks als separates Element bleiben konnte, ohne den Raum oder die Energiemodulationen zu beeinflussen, und ich denke, das hat das Stück irgendwie zusammengehalten.
Akusmatische Studie Version 4 – 36 channels, 3D 5th-order Ambisonics – Datei war zu groß zum Hochladen
Abstract: Spectral Select erkundet den spektralen Inhalt des einen, sowie den Amplitudenverlauf eines zweiten Samples und vereinigt diese in einem neuen musikalischen Kontext. Der durch Iteration entstehende meditative Charakter des Outputs wird durch lautere Amplituden-Peaks sowohl kontrastiert, als auch strukturiert. In einer überarbeiteten Version wurde Spectral Select im Ambisonics HOA-5 Format spatialisiert.
Betreuer: Prof. Dr. Marlon Schumacher
Eine Studie von: Anselm Weber
Wintersemester 2021/22 Hochschule für Musik, Karlsruhe
Zur Studie: In welchen Ausdrucksformen äußert sich die Verbindung zwischen Frequenz und Amplitude ? Sind beide Bereiche intrinsisch miteinander Verbunden und wenn ja, was könnten Ansätze sein, diese Ordnung neu zu gestalten ? Derartige Fragen beschäftigen mich bereits seid einiger Zeit. Daher ist der Versuch ebendieser Neugestaltung Kernthema bei Spectral Select. Inspiriert wurde ich dazu von AudioSculpt von IRCAM, welches wir in unserem Kurs: „Symbolische Klangverarbeitung und Analyse/Synthese“ gemeinsam mit Prof. Dr. Marlon Schumacher und Brandon L. Snyder kennenlernten und zum Teil nachbauten.
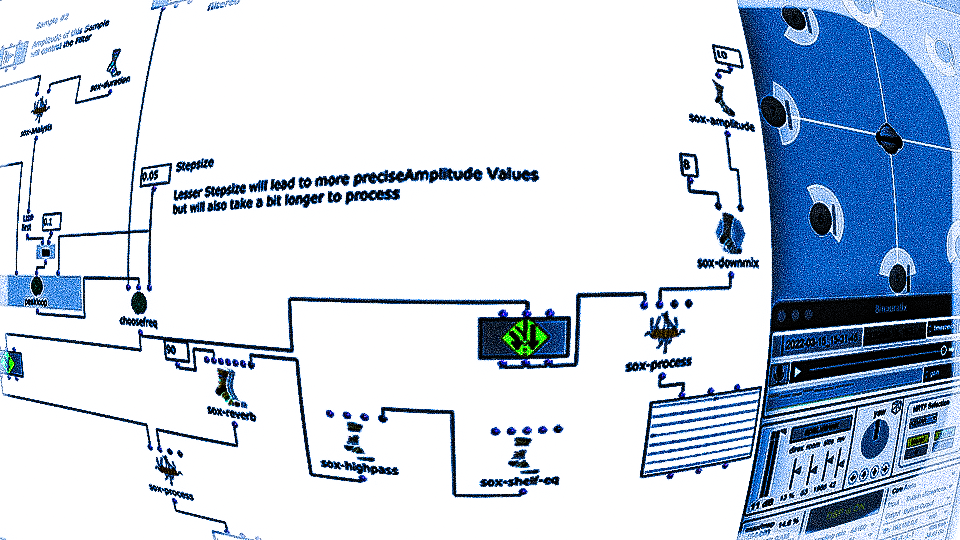
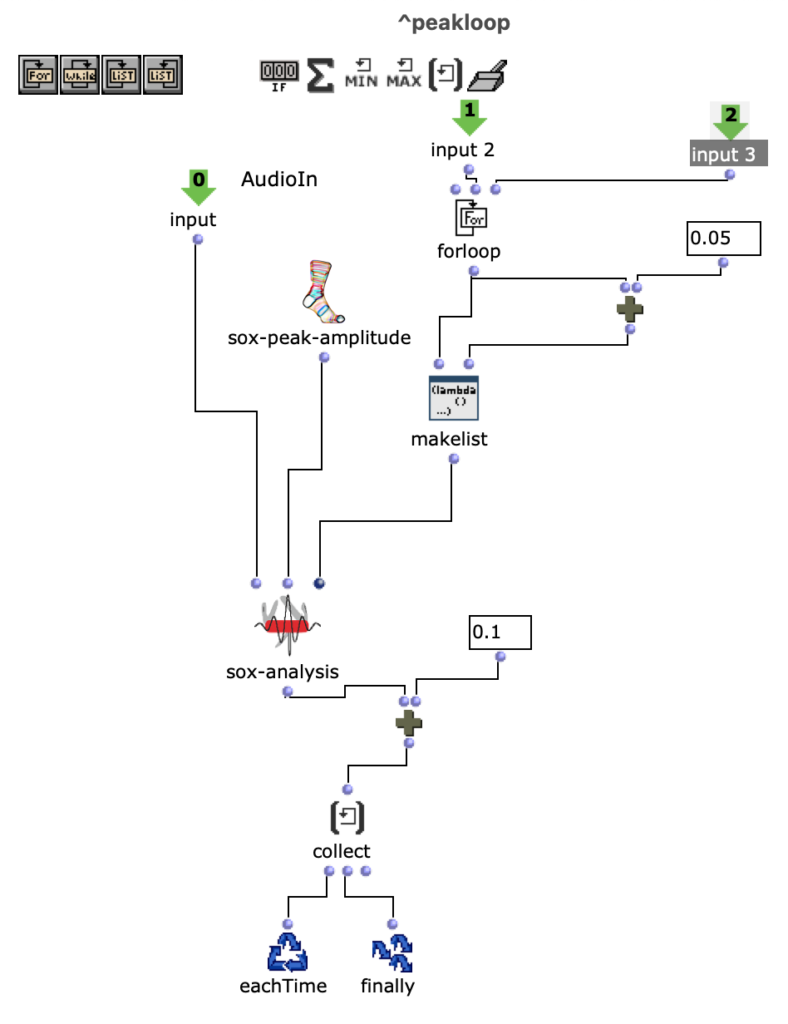
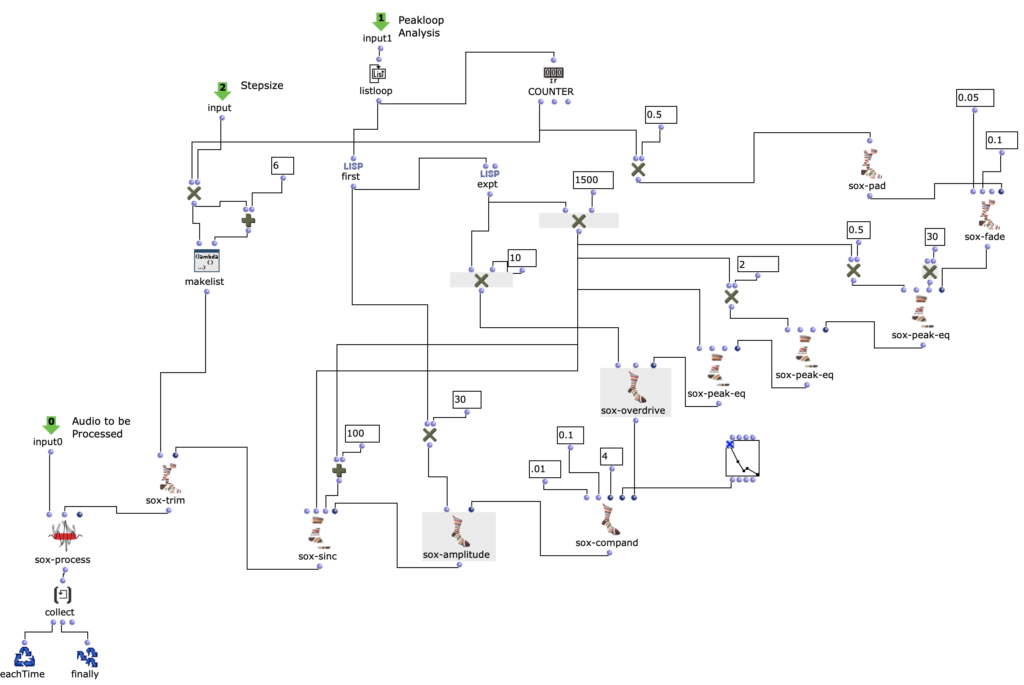
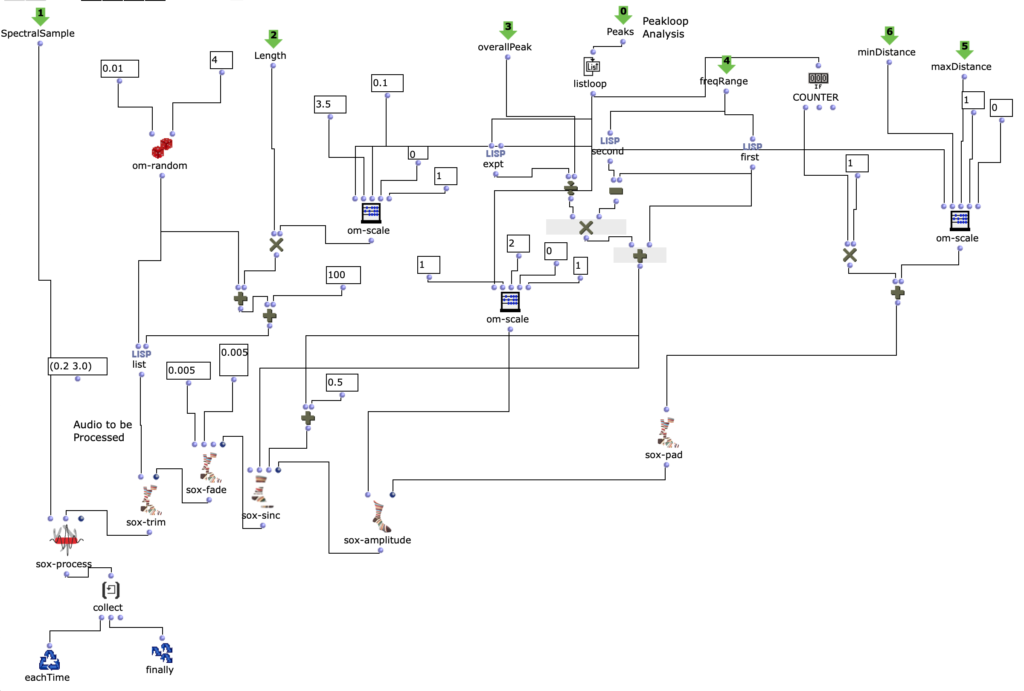
Spectral Edit funktioniert nach einem ähnlichen Prinzip, doch anstatt interessante Bereiche innerhalb eines Spektrums eines Samples von einem Benutzer herausarbeiten zu lassen, wurde entschieden, ein zweites Audiosample heranzuziehen. Dieses weitere Sample (im Verlauf dieses Artikels ab sofort als „Amplitudenklang“) bestimmt durch seinen Verlauf, wie das erste Sample (ab sofort als „Spektralklang“) durch OM-Sox verarbeitet werden soll. Um dies zu erreichen wird mit zwei Loops gearbeitet: Zunächst werden im ersteren „peakloop“ einzelne Amplitudenpeaks aus dem Amplitudenklang herausanalysiert. Daraufhin dient diese Analyse im Herzstück des Patches, dem „choosefreq“ Loop zur Auswahl interessanter Teilbereiche aus dem Spektralsample. Lautstarke Peaks filtern hierbei schmalere Bänder aus höheren Frequenzbereichen und bilden einen Kontrast zu schwächeren Peaks, welche etwas breiter Bänder aus tieferen Frequenzbereichen filtern.
peakloop – Analyse
choosefreq Loop – Audio Processing
Wie klein die jeweiligen Iterationsschritte sind, wirkt sich dabei sowohl auf die Länge, als auch auf die Auflösung des gesamten Outputs aus. So können je nach Sample-Material sehr viele kurze Grains oder weniger, aber dafür längere Teilabschnitte erstellt werden. Beide dieser Parameter sind jedoch frei und unabhängig voneinander wählbar.
Im beigefügten Stück wurde sich beispielsweise für eine relativ hohe Auflösung (also eine erhöhte Anzahl an Iterationsschritten) in Kombination mit längerer Dauer des ausgeschnittenem Samples entschieden. Dadurch entsteht ein eher meditativer Charakter, wobei kein Teilabschnitt zu 100% dem anderen gleichen wird, da es ständig minimale Veränderungen unter den Peak-Amplituden des Amplitudenklangs gibt. Das noch relativ rohe Ergebnis dieses Algorithmus ist die erste Version meiner akusmatischen Studie.
Akusmatische Studie Version 1
Der darauffolgende Überarbeitungsschritt galt vor allem einer präziseren Herausarbeitung der Unterschiede zwischen den einzelnen Iterationsschritten. Dazu wurde eine Reihe an Effekten eingesetzt, welche sich wiederum je nach Peak-Amplitude des Amplitudenklangs unterschiedlich verhalten. Um dies zu ermöglichen, wurde die Effektreihe direkt in den Peakloop integriert.
Akusmatische Studie Version 2
Im dritten und letztem Überarbeitungsschritt erfolgte die Spatialisierung des Audios auf 8 Kanäle. Hierbei klingen die einzelnen Kanäle ineinander und ändern ihre Position im Uhrzeigersinn. Somit bleibt der Grundcharakter des Stückes bestehen, jedoch ist es nun zusätzlich möglich, das „Durcharbeiten“ des choosefreq Loops räumlich zu verfolgen. Damit diese Räumlichkeit erhalten bleibt, wurde der Output anschließend mithilfe von Binauralix für den Upload in binaural Stereo umgewandelt.
Akusmatische Studie Version 3 – Binaural
Spectral Select – Ambisonics
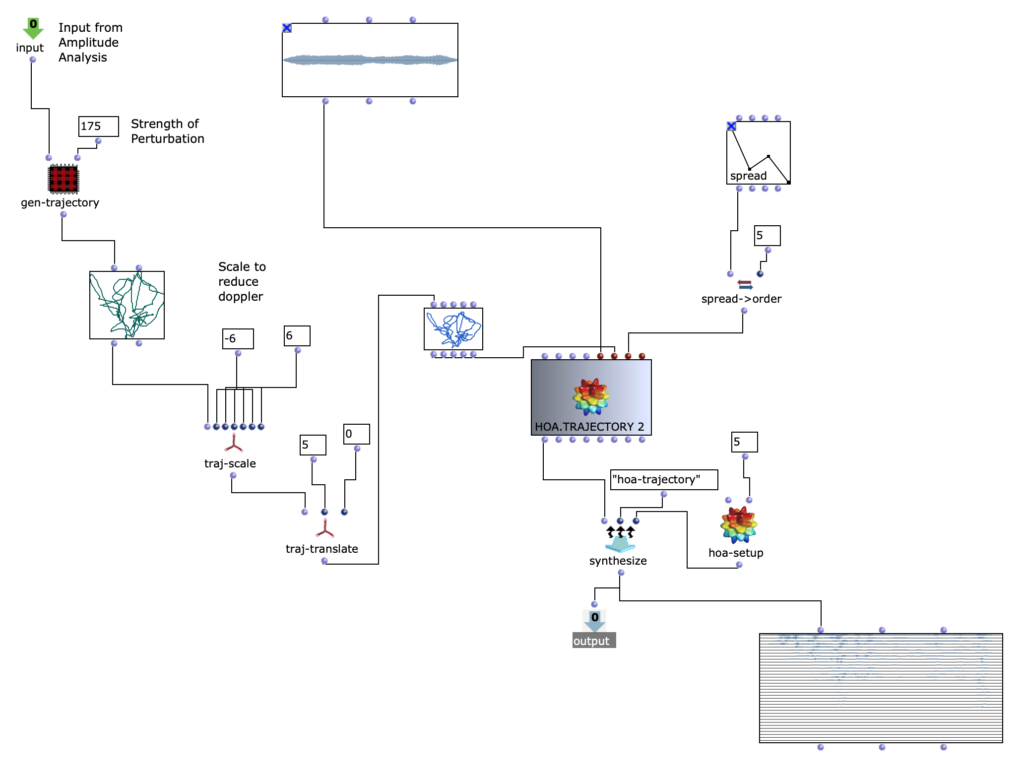
Im Zuge einer weiteren Überarbeitung wurde Spectral Select über die spatialisation class „Hoa-Trajectory“ von OM-Prisma neu spatialisiert und in das Ambisonics Format gebracht. Damit sich dieser Schritt konzeptionell und klanglich gut in die bisherigen Bearbeitungen eingliedert, soll der Amplitudenklang auch bei der Raumposition eine wichtige Rolle spielen. Die Möglichkeiten mithilfe von Open-Music und OM-Prisma Klänge zu spatialisieren sind zahlreich. Letzten Endes wurde entschieden, mit Hoa-Trajectory zu arbeiten. Hierbei ist die Klangquelle nicht an eine feste Position im Raum gebunden und kann mit einer Trajektorie beschrieben werden, welche auf die Gesamtdauer des Audio-Inputs skaliert wird.
Spatialisierung mit HOA.TRAEJECTORY
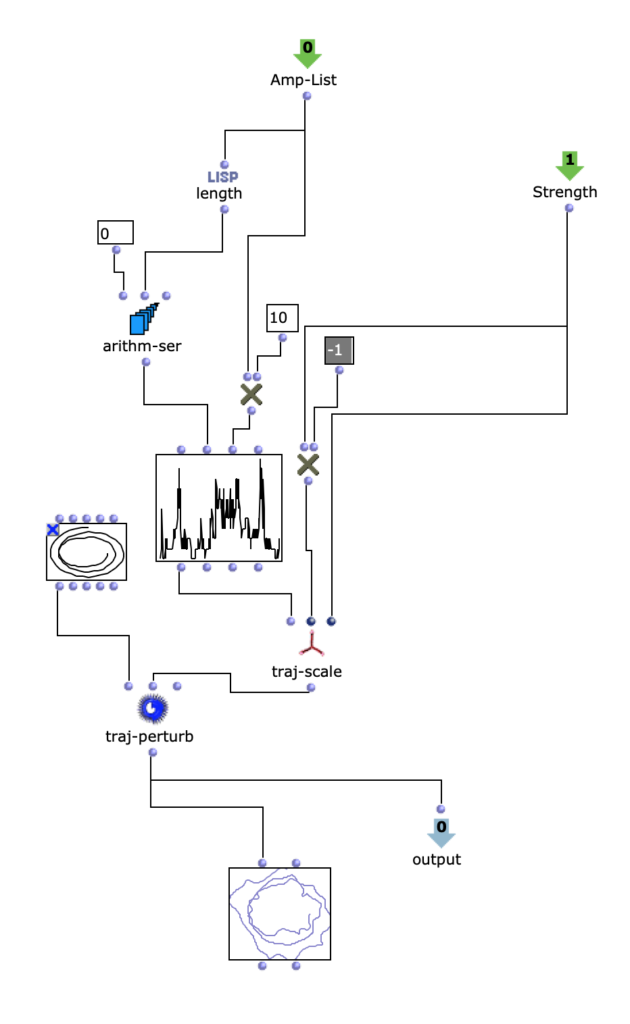
Die Trajektorie wird in Abhängigkeit der Amplituden-Analyse im vorhergehenden Schritt erstellt. Dabei wird eine simple, dreidimensionale Kreis Bewegung, welche sich in Spiralbewegung nach unten dreht, mit einer komplexeren, zweidimensionalen Kurve perturbiert. Die Y-Werte der komplexeren Kurve entsprechen dabei den herausanalysierten Amplitudenwerten des Amplitudenklanges. Somit ergeben sich je nach skalierung der Amplitudenkurve mehr oder weniger starke Abweichungen der Kreisbewegung. Höhere Amplitudenwerte sorgen also für ausuferndere Bewegungen im Raum.
Interessant hierbei ist, dass OM-Prisma auch Doppler-Effekte mitberücksichtigt. Dadurch ist zusätzlich hörbar, dass bei höheren Amplitudenwerten extremere Abstände zur Hörposition in der selben Zeit zurückgelegt werden. Dadurch nimmt dieser Arbeitsschritt unmittelbar Einfluss auf die Klangfarbe des gesamten Stückes. Je nach Skalierung der Trajektorie können schnelle Bewegungen dadurch stark überbetont werden, allerdings können (ab einer zu großen Entfernung) auch Artfakten entstehen. Damit ein besserer Eindruck Ensteht folgen 2 verschiedene durchläufe des Algorithmus mit unterschiedlichen Abständen zum Hörer.
Version mit extremen Doppler Effekten wodurch Artfakte enstehen können – Binaural Stereo
Version mit näherem Abstand und moderateren Doppler Effekten– Binaural Stereo
Spektralklang sowie Amplitudenklang wurden in diesem Beispiel im Gegensatz zu den vorherigen Klangbeispielen ausgetauscht. Es handelt sich hierbei um ein längeres Soundfile zur Analyse der Amplituden und einen weniger verzerrten Drone als Spektralklang. Die Idee hinter diesem Projekt ist ohnehin, mit verschiedenen Klangdateien zu experimentieren. Daher wurde auch der alter Algorithmus noch einmal überarbeitet um mehr Flexibilität bei unterschiedlichen Klangdateien zu bieten:
Überarbeitete skalierbare Version des alten Algorthimus zur Auswahl aus dem Spektralklang
Außerdem wird nun aus dem Spektralklang auf der Zeitachse randomisiert ausgewählt. Dadurch soll jeglicher formgebender Zusammenhang aus der Magnitude des Amplitudenklangs stammen und jegliche Klangfarbe aus dem Spektralklang extrahiert werden.
In diesem Artikel stelle ich meine Ideen, kreativen Prozesse und technischen Daten zum für die Klasse „Symbolische Klangverarbeitung und Analyse/Synthese“ bei Prof. Marlon Schumacher programmierter Patch vor. Die Idee dieses Textes ist es, die technischen Lösungen für meine kreativen Ideen aufzuzeigen und das gewonnene Wissen zu teilen und so dem Leser bei seinen Ideen zu helfen. Der Zweck dieses Patches ist, Klänge aus dem Alltag zu nehmen und sie mit Hilfe mehrerer Prozesse innerhalb von Open Music in eine eigene Komposition umzuwandeln.
Die Ausgangsidee des Stücks war es, Alltagsgeräusche, zum Beispiel ein Geräusch eines Wasserkochers, in einen anderen, bearbeiteten Klang zu verwandeln, indem technische Lösungen in Open Music implementiert wurden. Dieser Patch verarbeitet und führt mehrere Dateien zu einer Komposition zusammen. Es gibt drei Iterationen des Patches, an dem ich während des Semesters gearbeitet habe. Ich werde sie chronologisch nacheinander beschreiben.
Die ursprüngliche Idee für den Patch stammt von musique concréte. Ich wollte aus konkreten Klängen (nicht in Open Music synthetisiert, sondern aufgenommen) ein 2-Minuten-Stück machen. Dieser Patch besteht aus drei Subpatches, die mit der Maquette im Hauptpatch verbunden sind.
Dieser Beitrag handelt über die drei Iterationen einer akusmatischen Studie von Zeno Lösch, welche im Rahmen des Seminars „Symbolische Klangverarbeitung und Analyse/Synthese“ bei Prof. Dr. Marlon Schumacher an der HFM Karlsruhe durchgeführt wurden. Es wird über die grundlegende Konzeption, Ideen, aufbauende Iterationen sowie die technische Umsetzung mit OpenMusic behandelt.
Meine Inspiration für diese Study habe ich von dem Freeze Effekt der GRM Tools.
Dieser Effekt ermöglicht es ein Sample zu layern und ihn gleichzeitig in verschiedenen Geschwindigkeiten abzuspielen.
Mit diesem Prozess kann man eigenständige Kompositionen, Sound-Objekte, Klanggebilde u.s.w. erstellen.
Meine Idee ist es dasselbe mit Open Music zu programmieren.
Dazu habe ich die Maquette verwendet und om-loops.
In der OpenMusicPatch findet man die verschiedenen Prozesse des layern des Ausgangsmaterials.
Das Ausgangsmaterial ist eine „gefilterte“ Violine. Diese wurde mit dem Prozess der Cross-Synthesis erstellt. Dieser Prozess des Ausgangsmaterials wurde nicht in Open Music erstellt.
Ausgangsmaterial
Musik kann nicht ohne Zeit existieren. Unsere Wahrnehmung verbindet die verschiedenen Klänge und sucht einen Zusammenhang. In diesem Prozess, auch vergleichbar mit Rhythmus, wird das einzelne Objekt mit anderem Objekten in Verbindung gesetzt. Digitale Klangmanipulation ermöglicht es mit Prozessen aus einem Klang andere zu erstellen, welche im Zusammenhang zu dem gleichen stehen.
Zum Beispiel ich Präsentiere den Klang in einer Form und verändere ihn an einem anderen Zeitpunkt in der Komposition. Es entsteht meistens ein Zusammenhang, insofern der Hörer diesen nachvollziehen kann.
Man kann ähnlich wie bei Noten eine Transposition bzw. die Tonhöhe verändern.
Bei einer Note wird dadurch die Frequenz verändert. Bei einem digitalen Material kann es zu sehr spannenden Ergebnissen führen. Bei einem Klavier sind die Obertöne bei jeder Note in einem Zusammenhang zum Grundton. Diese sind festgelegt und sind mit traditionellen Noten nicht veränderbar.
Bei digitalen Material spielt der Effekt, der transponiert, eine sehr wichtige Rolle. Je nach Art des Effekts habe ich verschiedene Möglichkeiten das Material zu manipulieren nach meinen eigenen Regeln.
Der Nachteil bei Instrumenten ist es, dass zum Beispiel bei einer Violine, der Spieler nur einmal die Note spielen kann. Zehnmal die gleiche Note bedeutet zehn Violinen.
In OpenMusic ist es möglich das „Instrument“ beliebig oft zu spielen (insofern es die Rechenleistung des Computers schafft).
Prozess
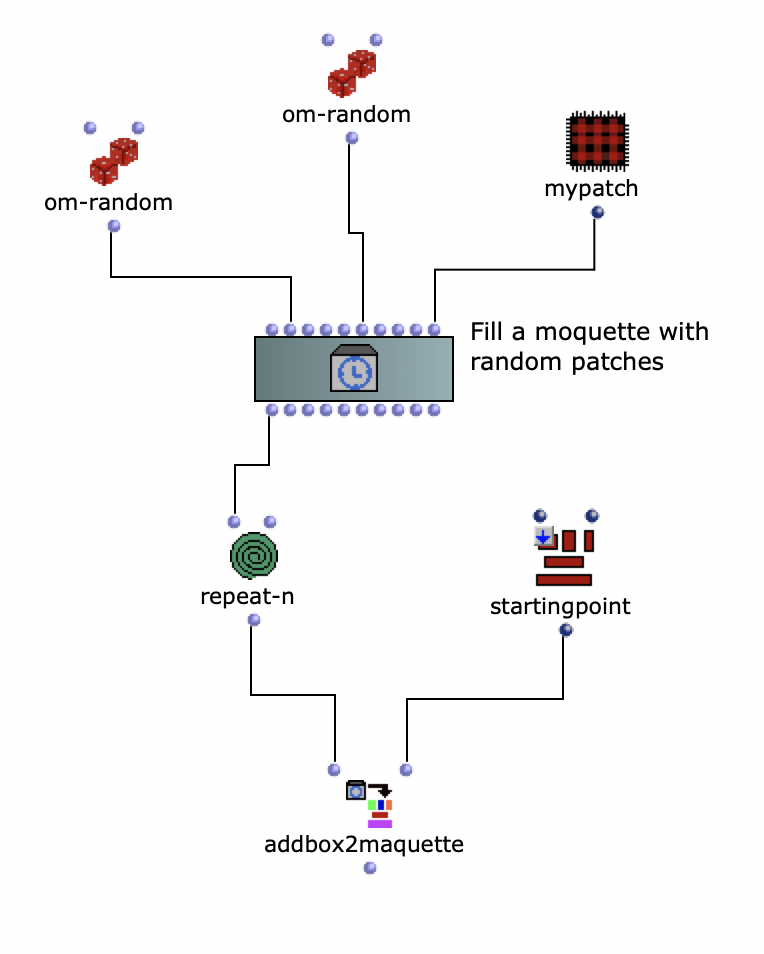
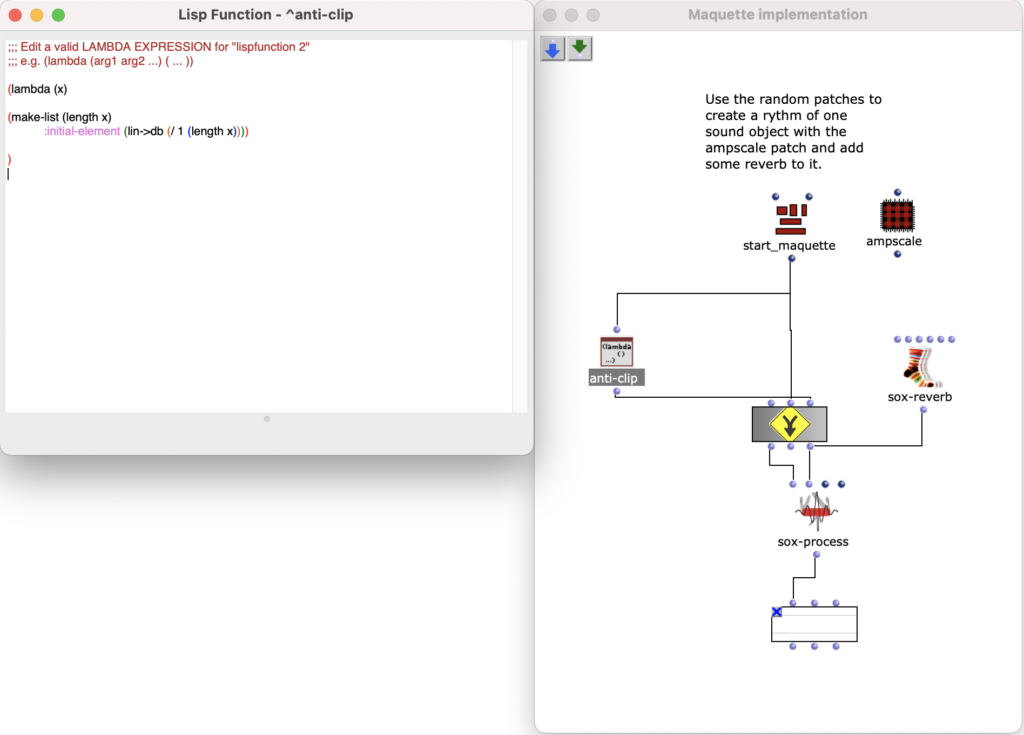
Um das Grm-Freeze nachzubauen, wurde zuerst eine moquette mit leeren Patches gefüllt.
Füllen einer Moquette mit leeren Patches
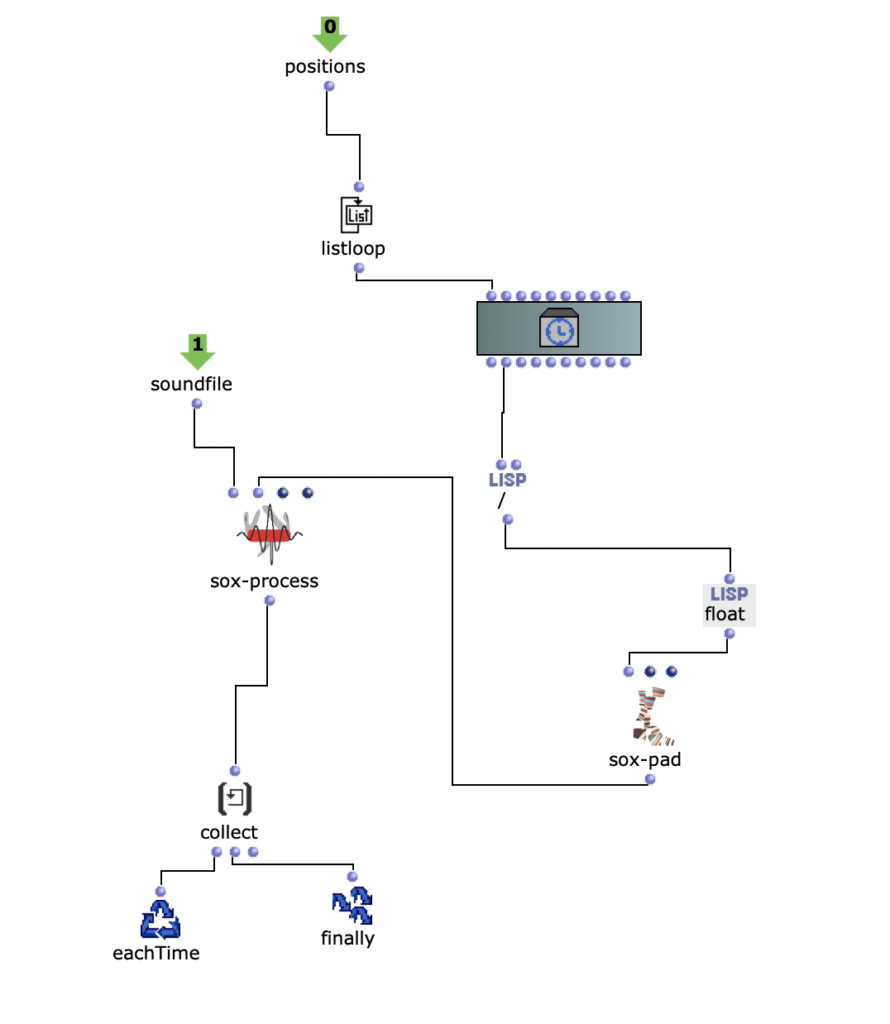
Anschließend wurde aus der Moquette mit einem om-loop das soundfile an die Positionen der leeren Patches gerendert.
Loop für soundfile Positionen
Um clipping zu vermeiden wurde folgender Code verwendet.
Sox-Mix und Anti Clip
Layer Study erste Iteration
Das Ausgangsmaterial wird am Anfang präsentiert. Im Laufe der Studie wird es immer wieder verändert und verschiedenartig gestapelt.
In der Studie selbst wird auch mit der Dynamik gespielt. Je nach Algorithmus der Klangstapelung wird die Dynamik in jedem Soundobjekt verändert. Da es sich um mehr als einen Klang in der Zeit handelt werden diese Klänge normalisiert, je nach wie viele Klänge in dem Algorithmus präsent sind um Clipping zu vermeiden.
Die Studie beginnt mit dem Ausgangsmaterial. Dieses wird anschließend in einer verschiedenen zeitlichen Abfolge präsentiert.
Dieser Layer wird dann gefiltert und er ist auch leiser. Der nächste Entwickelt sich zu einem „halligerm“ Klang. Ein Kontinuum. Das Kontinuum bleibt es ist wird wieder anders Präsentiert.
Im vorletzten Klang sind eine Form von glissandi zu hören, welche wieder in einem Klang enden, der ähnlich ist wieder zweite, aber lauter ist.
Der Prozess um den Klang zu stapeln und zu verändern ist bei jeder Sektion sehr ähnlich.
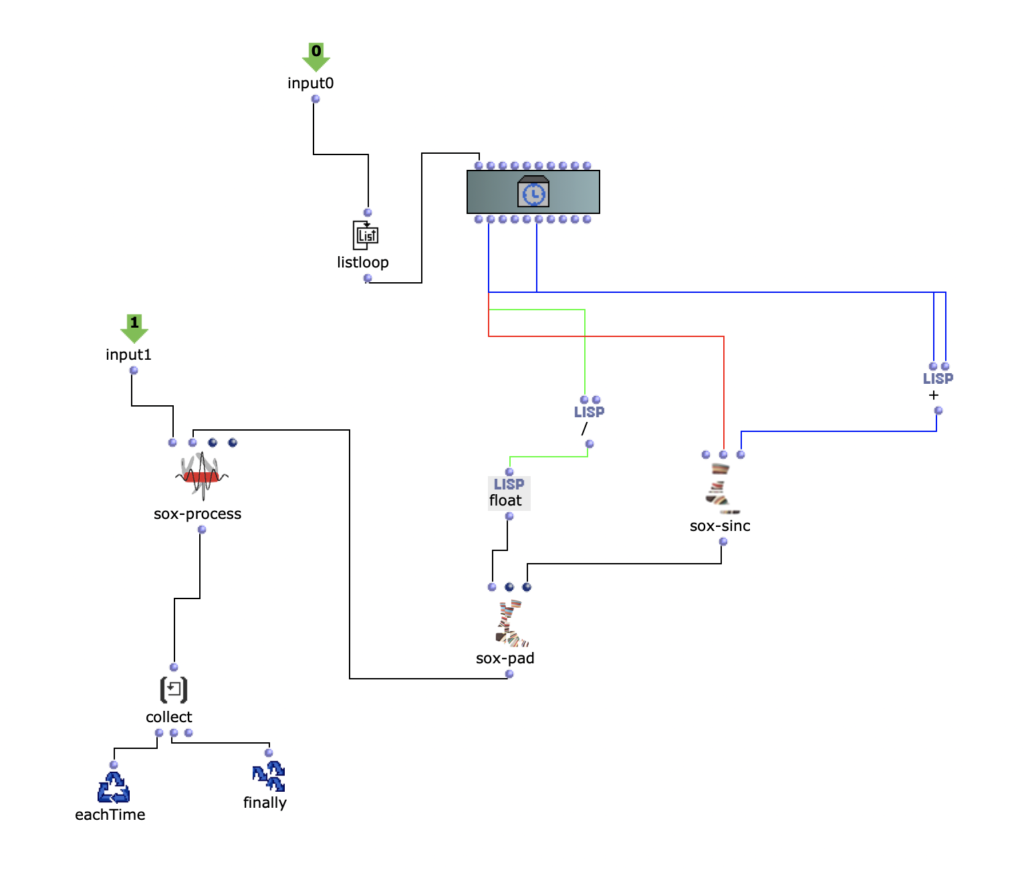
Die Position wird von der leeren Patch in der Moquette gegeben.
Anschließend wird die y-Position und x-Position Parameter für eine Modulation
Implementierung der x- und y-Positionen als ModulationsparameterLayer Study erste Iteration
Layer Study zweite Iteration
Ich habe für jede Sektion versucht ein anderes Stereobild zu erzeugen.
Es wurden verschiedene Räume simuliert.
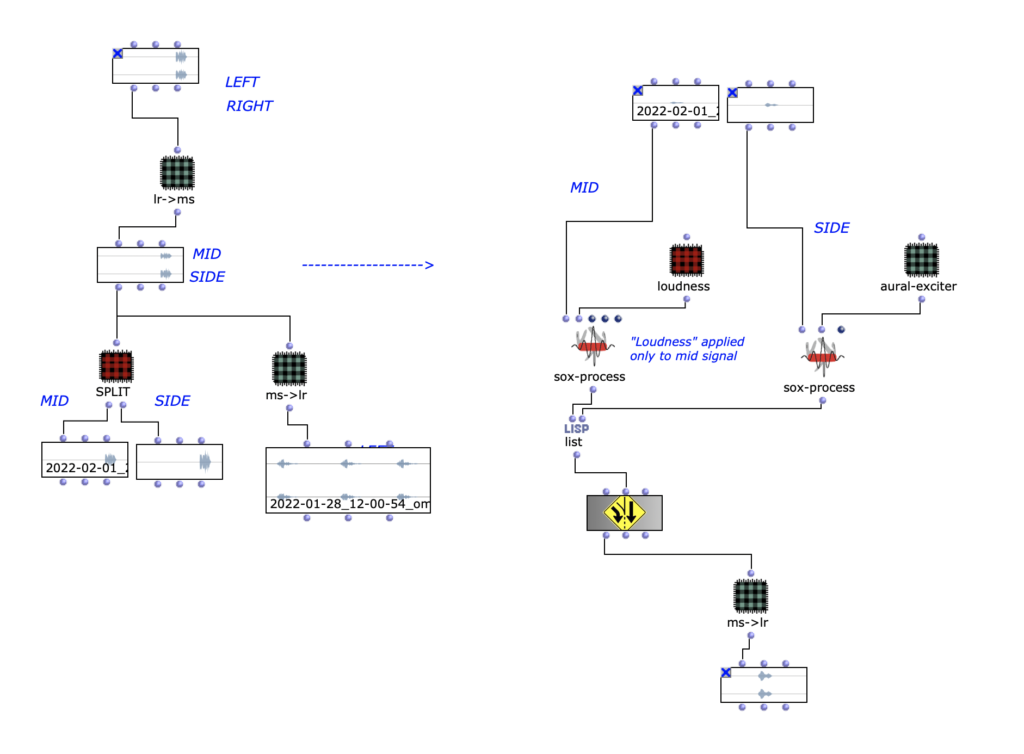
Eine Technik, die dabei verwendet wurde ist das Mid/Side.
Bei dieser Technik wird aus einem Stereosignal das Mid und Side mit folgendem Prozess extrahiert:
Mid = (L + R) * 0.5
Side = (L – R) * 0.5
Zudem wurde ein Aural Exciter werdet.
Bei diesem Prozess wird das Signal mit einem Hochpassfilter gefiltert, verzerrt und dem Eingangssignal wieder hinzugefügt. Man kann dadurch eine bessere Definition erreichen.
Durch das Mid/Side wird der Aural Exciter nur auf einem der beiden angewendet und es wird als „definierter“ Wahrgenommen.
Um den Prozess wieder zu einem Stereo signal zu kommen wird folgender Prozess angewendet:
L = Mid + Side
R = Mid – Side
Mid Side Prozess
Um den Klang weiter zu verräumlichen wurde mit Hilfe eines Allpassfilters und einem Kammfilter die Phase von Mid oder Side Anteil verändert.
Dekorrelation der Phase
Layer Study Stereo
Layer Study dritte Iteration
Bei dieser iteration wurde das Stereofile auf acht Lautsprecher aufgeteilt.
Es wurden die verschiedenen Sektionen der Stereokomposition extrahiert und verschiedene Techniken der Aufteilung verwendet.
Bei einen dieser wurde ein unterschiedliches fade in und fade out für jeden Kanal verwendet.
In einer akousmatischen Ausführung einer Komposition kann man dieses fade in und fade out mit den Reglern eines Mixers erziehlen.
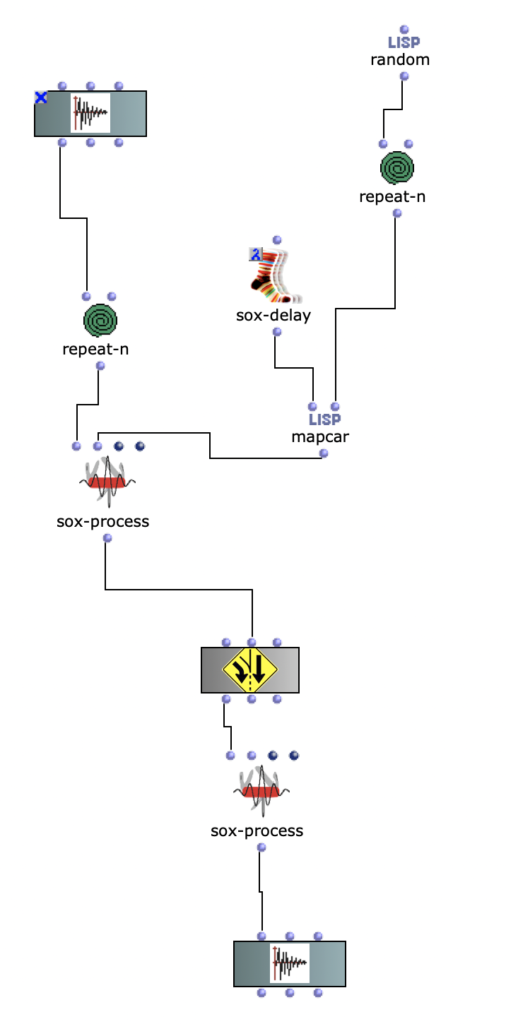
Dazu wurde ein mapcar und repeat-n verwendet.
Random Fades für Multichannel
Bei den anderen Prozessen wurde die Position der jeweiligen Kanäle verändert. Es wurde ein Delay verwendet.
A link to download the applications can be found at the end of this blogpost. This project was also presented as a paper at the 2022 International Conference on Technologies for Music Notation and Representation (TENOR 2022).
Modularity in Sound Synthesis Tools
This blogpost walks through the structure and usage of two applications of machine learning (ML) methods for sound notation and synthesis. The first application is a modular sample replacement engine that uses a supervised classification algorithm to segment and transcribe a drum beat, and then reconstruct that same drum beat with different samples. The second application is a texture synthesis engine that uses an unsupervised clustering algorithm to analyze and sort large numbers of audio files.
The applications were developed in OpenMusic using the OM-SoX modular synthesis/analysis framework. This was so that the applications could be as modular as possible. Modular, meaning that they could be customized, extended, and integrated into a user’s own OpenMusic workflow. We believe this modularity offers something new to the community of ML and sound synthesis/analysis tools currently available. The approach to sound synthesis and analysis used here involves reading and querying many separate audio files. Such an approach can be encompassed by the larger term of „corpus-based concatenative synthesis/analysis,“ for which there are already several effective tools: the Caterpillar System, Audioguide, and OM-Pursuit. Additionally, OM-AI, ml.*, and zsa.descriptors are existing toolkits that integrate ML methods into Computer-Aided Composition (CAC) environments. While these tools are very precise, the internal workings of them are not immediately clear. By seeking for our applications to be modular, we mean that they can be edited, extended and integrated into existing CAC programs. It also means that they can be opened and up, examined, and reverse-engineered for a user’s own education.
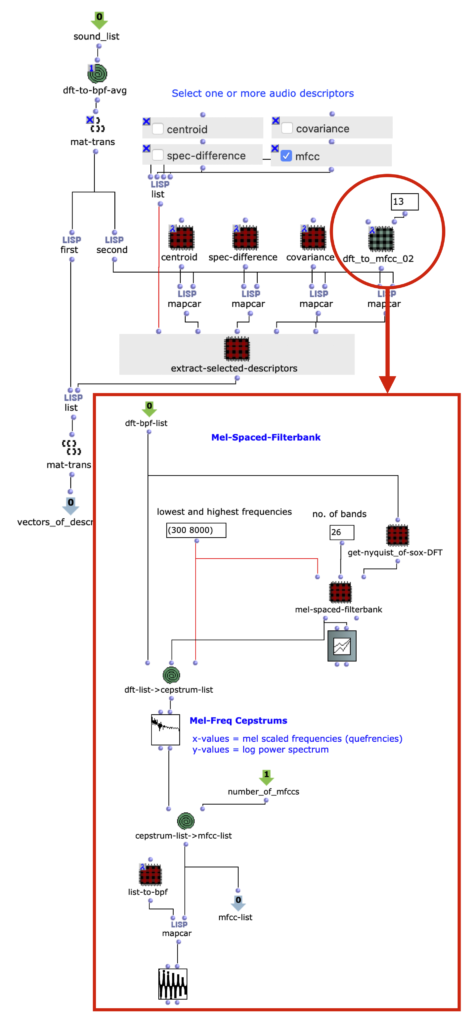
One example of this is in figure 1, our audio analysis engine. Audio descriptors are implemented as subpatches in lambda mode, and can be selected as needed for the input audio.
Figure 1: Interchangeable audio descriptors are set as patches in lambda mode. Here, a patch extracting 13 MFCCs is being used.
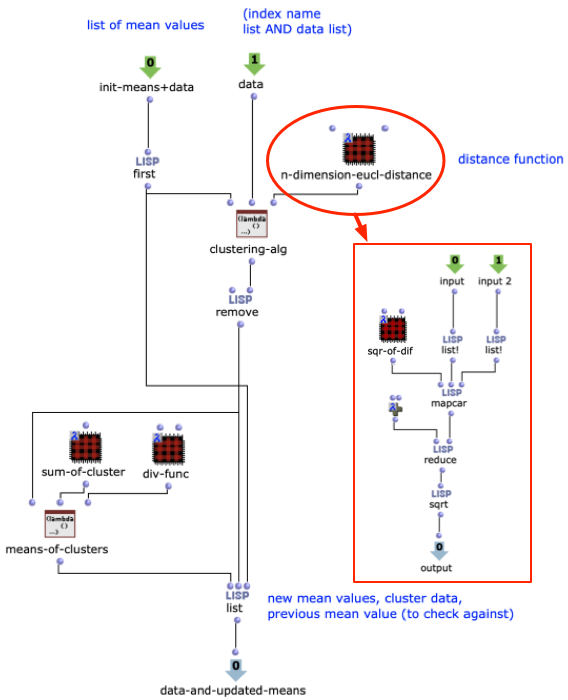
Another example is in figure 2, a customizable distance function in our texture synthesis application. This is the ML clustering algorithm that drives the application. Being a patch built from smaller OpenMusic objects, it is not only a tool for visualizing the algorithm at work, it also allows a user to edit it. For example, the n-dimension euclidean distance function could be substituted with another distance function, if needed.
Figure 2: A simple k-means clustering algorithm, built within an OpenMusic abstraction. The distance function takes the form of a subpatcher in lambda mode.
With the modularity of the project introduced, we will on the next page move on to the two specific applications.
Momentan umfasst die Library zwei Funktionen, die sowohl mit CommonLisp, als auch mit schon bestehenden Funktionen aus dem OM-Package geschrieben sind.
Zudem ist die Komposition im Umfang der zu kontollierenden Parametern, momentan auf die Harmonik und die Stimmführung begrenzt.
Für die Zukunft möchte ich ebenfalls eine Funktion schreiben, welche mit den Parametern Metrik und Einsatzabstände, die Komposition auch auf zeitlicher Ebene erlaubt.
Entwicklung: Lorenz Lehmann
Betreuung und Beratung: Prof. Dr. Marlon Schumacher
Mein herzlicher Dank für die freundliche Unterstützung gilt Joseph Branciforte und
In dieser Unterrichtseinheit wird die Sprache Common LISP eingeführt. Hierzu betrachten wir Besonderheiten dieser Sprache, insbesondere die Syntax: sog. „S-Expressions“ (symbolic expressions) und Prefix (oder „Polish“) Notation. Des Weiteren befassen wir uns mit dem Konzept der Evaluierung von Formen unter Berücksichtigung der Äquivalenz von Daten und Funktionen: „A lisp form is a lisp datum that is also a program, that is, it can be evaluated without an error.„
Wir haben uns mit der Evaluierungsreihenfolge studiert. Lisp evaluiert Formen rekursiv. Hierzu ein kleines Beispiel aus diesem online LISP Tutorial. Folgende form soll evaluiert werden:
(+ 33 (* 2.3 4)) 9)
The + function is looked up.
33 is evaluated (its value is 33).
(* 2.3 4) is evaluated:
The * function is looked up.
2.3 is evaluated (its value is 2.3)
4 is evaluated (its value is 4)
2.3 and 4 are passed to the * function.
The * function returns 9.2. This is the value of (* 2.3 4).
9 is evaluated (its value is 9).
33, 9.2, and 9 are passed to the + function.
The + function returns 51.2. This is the value of (+ 33 (* 2.3 4) 9).
The Lisp system returns 51.2.
Wir haben sodann verschiedene Datentypen kennengelernt: symbols, floats, integers und ratios.
Wir haben unsere ersten Programmierversuche gestartet und unsere ersten kleinen LISP forms geschrieben. Dabei haben wir sog. „primitive functions“ (Funktionen, die bereits in der Sprache implementiert sind) verwendet, um Operationen mit Daten auszuführen. Diese waren: (*für die u.s. Tabellen nehmen wir an, die Variable A hätte den Wert 10 und Variable B den Wert 20) :
Arithmetische Operatoren
+, -, *, /, mod, rem, incf, decf
Operator
Description
Example
+
Adds two operands
(+AB) will give 30
–
Subtracts second operand from the first
(- A B) will give -10
*
Multiplies both operands
(* A B) will give 200
/
Divides numerator by de-numerator
(/ B A) will give 2
mod, rem
Modulus Operator and remainder of after an integer division
(mod B A) will give 0
incf
Increments operator increases integer value by the second argument specified
(incf A 3) will give 13
decf
Decrements operator decreases integer value by the second argument specified
(decf A 4) will
Prädikatsfunktionen
equalp, symbolp, numberp, oddp, evenp
Operator
Description
Example
equalp
Checks if the values of the two arguments are equal
(= A B) is not true.
symbolp
Checks if the value of the argument is a symbol
(symbolp A) is not true
numberp
Checks if the value of the argument is a number
(numberp A) is true.
oddp
Checks if the value of the argument (integer) is odd
(oddp A) is not true
evenp
Checks if the value of the argument (integer) is even
(evenp A) is true
Vergleichsoperatoren
=, /=, >, <, >=, <=, max, min
Operator
Description
Example
=
Checks if the values of the operands are all equal or not, if yes then condition becomes true.
(= A B) is not true.
/=
Checks if the values of the operands are all different or not, if values are not equal then condition becomes true.
(/= A B) is true.
>
Checks if the values of the operands are monotonically decreasing.
(> A B) is not true.
<
Checks if the values of the operands are monotonically increasing.
(< A B) is true.
>=
Checks if the value of any left operand is greater than or equal to the value of next right operand, if yes then condition becomes true.
(>= A B) is not true.
<=
Checks if the value of any left operand is less than or equal to the value of its right operand, if yes then condition becomes true.
(<= A B) is true.
max
It compares two or more arguments and returns the maximum value.
(max A B) returns 20
min
It compares two or more arguments and returns the minimum value.
(min A B) returns 20
Logische Operatoren
Hierfür nehmen wir an, A hat den Wert NIL (false) und B hat den Wert 5 (true).
Operator
Description
Example
and
It takes any number of arguments. The arguments are evaluated left to right. If all arguments evaluate to non-nil, then the value of the last argument is returned. Otherwise nil is returned.
(and A B) will return NIL.
or
It takes any number of arguments. The arguments are evaluated left to right until one evaluates to non-nil, in such case the argument value is returned, otherwise it returns nil.
(or A B) will return 5.
not
It takes one argument and returns t if the argument evaluates to nil.
(not A) will return T.
Danach haben wir die Macro Funktion „defun“ kennen gelernt, um unsere eigenen Funktionen zu definieren. Dies haben wir dann mit der Programmierung eines kleinen Würfelspiels zur Anwendung gebracht.

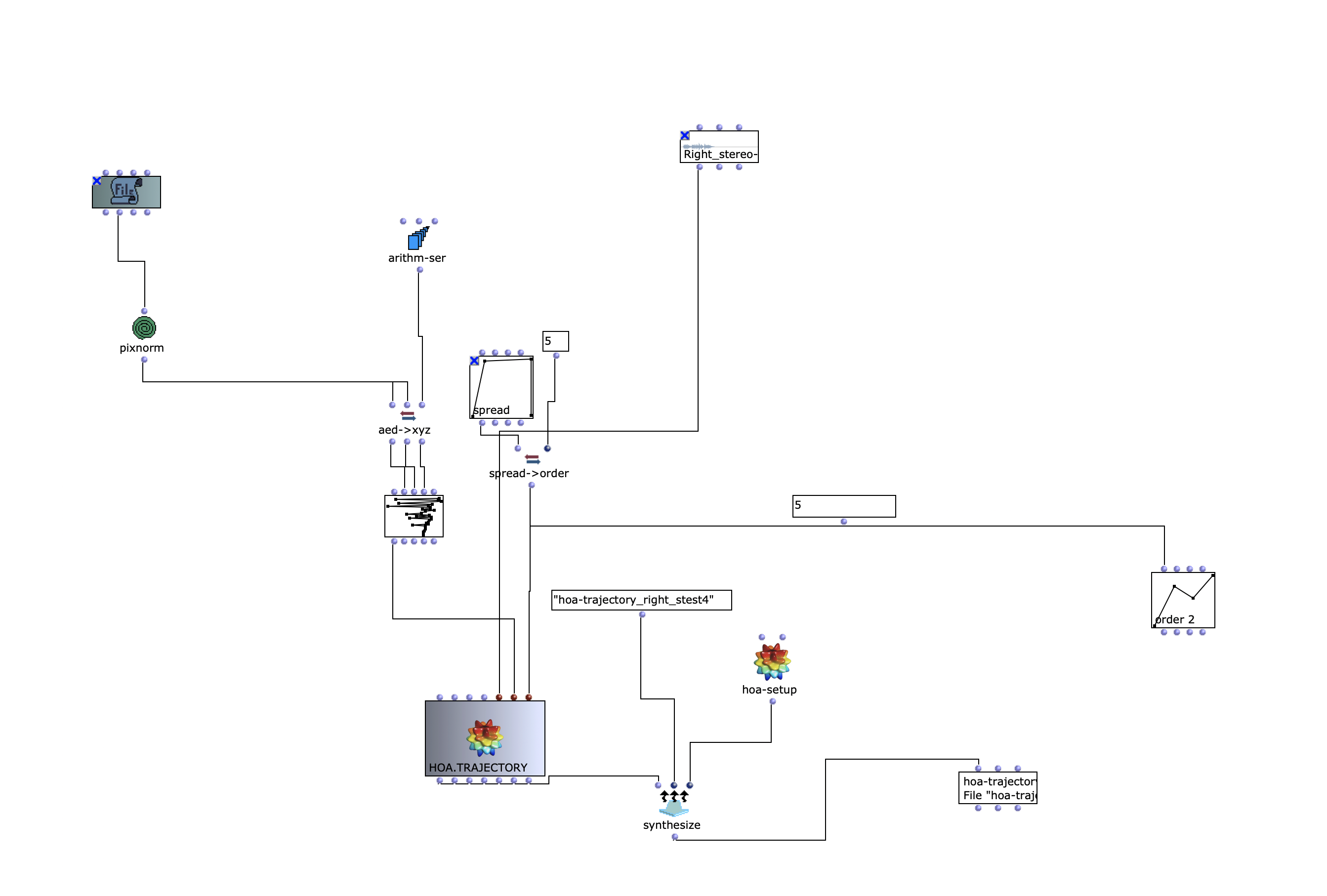
 Die Stereo und Monofiles wurden zuerst in 5th Order Ambisonics Codiert (36 Kanäle) und schließlich mit dem binauralen Encoder in zwei Kanäle umgewandelt.
Die Stereo und Monofiles wurden zuerst in 5th Order Ambisonics Codiert (36 Kanäle) und schließlich mit dem binauralen Encoder in zwei Kanäle umgewandelt. 
 Andere Effekte zur Nachbearbeitung(Detune, Reverb) wurden von mir selbst programmiert und sind auf Github verfügbar. Der Reverb basiert auf einen Paper von James A. Moorer About this Reverberation Business von 1979 und wurde in C++ geschrieben. Der Algorythmus vom Detuner wurde von der HTML Version vom Handbuch „The Theory and Technique of Electronic Music“ von Miller Puckette in C++ geschrieben. Das Ergebnis der letzen Iteration ist hier zu hören. Alex Player - Best audio player
Andere Effekte zur Nachbearbeitung(Detune, Reverb) wurden von mir selbst programmiert und sind auf Github verfügbar. Der Reverb basiert auf einen Paper von James A. Moorer About this Reverberation Business von 1979 und wurde in C++ geschrieben. Der Algorythmus vom Detuner wurde von der HTML Version vom Handbuch „The Theory and Technique of Electronic Music“ von Miller Puckette in C++ geschrieben. Das Ergebnis der letzen Iteration ist hier zu hören. Alex Player - Best audio player