Abstract:
Spectral Select erkundet den spektralen Inhalt des einen, sowie den Amplitudenverlauf eines zweiten Samples und vereinigt diese in einem neuen musikalischen Kontext. Der durch Iteration entstehende meditative Charakter des Outputs wird durch lautere Amplituden-Peaks sowohl kontrastiert, als auch strukturiert.
In einer überarbeiteten Version wurde Spectral Select im Ambisonics HOA-5 Format spatialisiert.
Betreuer: Prof. Dr. Marlon Schumacher
Eine Studie von: Anselm Weber
Wintersemester 2021/22
Hochschule für Musik, Karlsruhe
Zur Studie:
In welchen Ausdrucksformen äußert sich die Verbindung zwischen Frequenz und Amplitude ? Sind beide Bereiche intrinsisch miteinander Verbunden und wenn ja, was könnten Ansätze sein, diese Ordnung neu zu gestalten ?
Derartige Fragen beschäftigen mich bereits seid einiger Zeit. Daher ist der Versuch ebendieser Neugestaltung Kernthema bei Spectral Select.
Inspiriert wurde ich dazu von AudioSculpt von IRCAM, welches wir in unserem Kurs: „Symbolische Klangverarbeitung und Analyse/Synthese“ gemeinsam mit Prof. Dr. Marlon Schumacher und Brandon L. Snyder kennenlernten und zum Teil nachbauten.
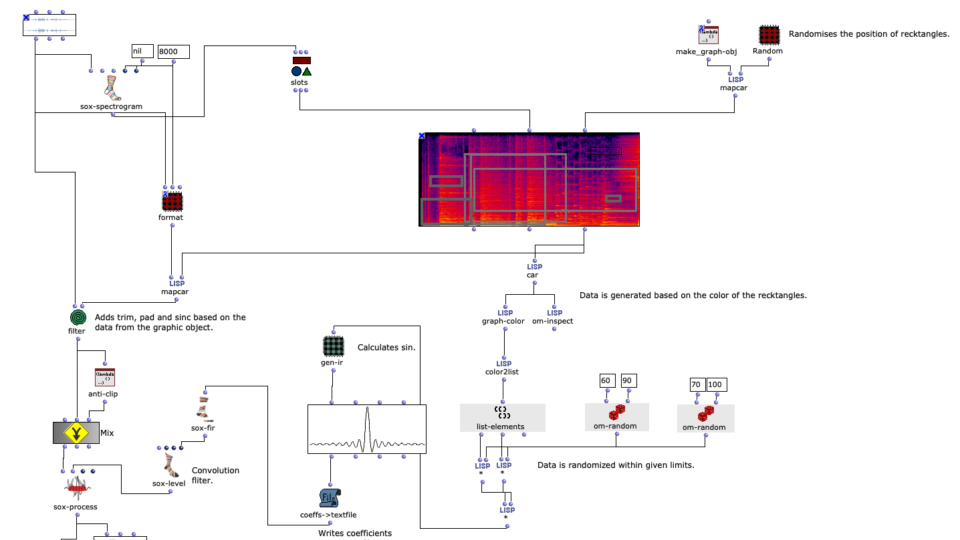
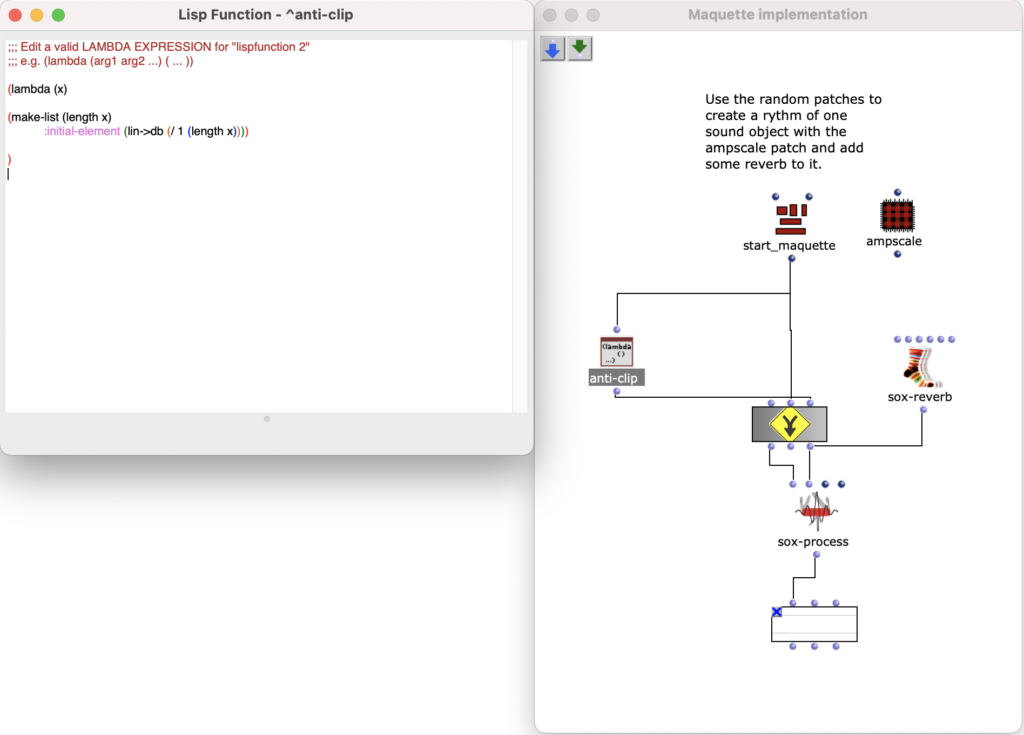
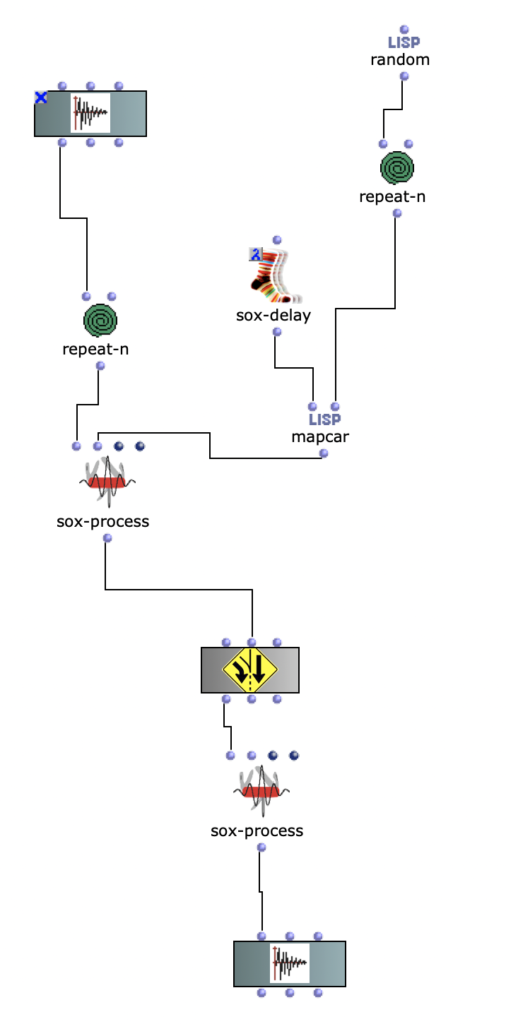
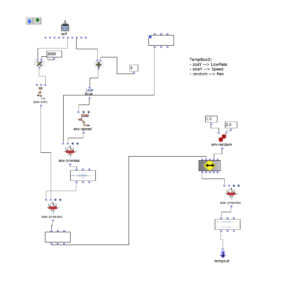
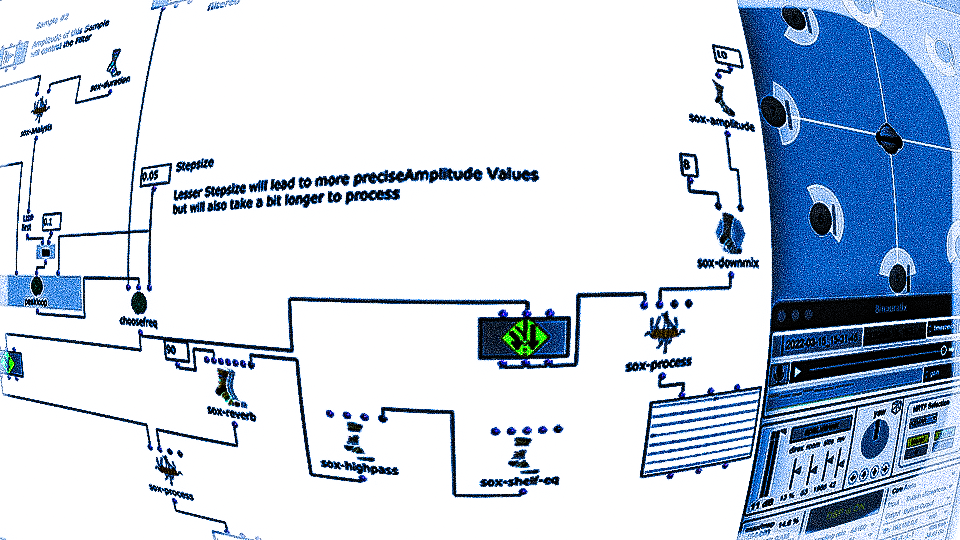
Spectral Edit funktioniert nach einem ähnlichen Prinzip, doch anstatt interessante Bereiche innerhalb eines Spektrums eines Samples von einem Benutzer herausarbeiten zu lassen, wurde entschieden, ein zweites Audiosample heranzuziehen. Dieses weitere Sample (im Verlauf dieses Artikels ab sofort als „Amplitudenklang“) bestimmt durch seinen Verlauf, wie das erste Sample (ab sofort als „Spektralklang“) durch OM-Sox verarbeitet werden soll.
Um dies zu erreichen wird mit zwei Loops gearbeitet:
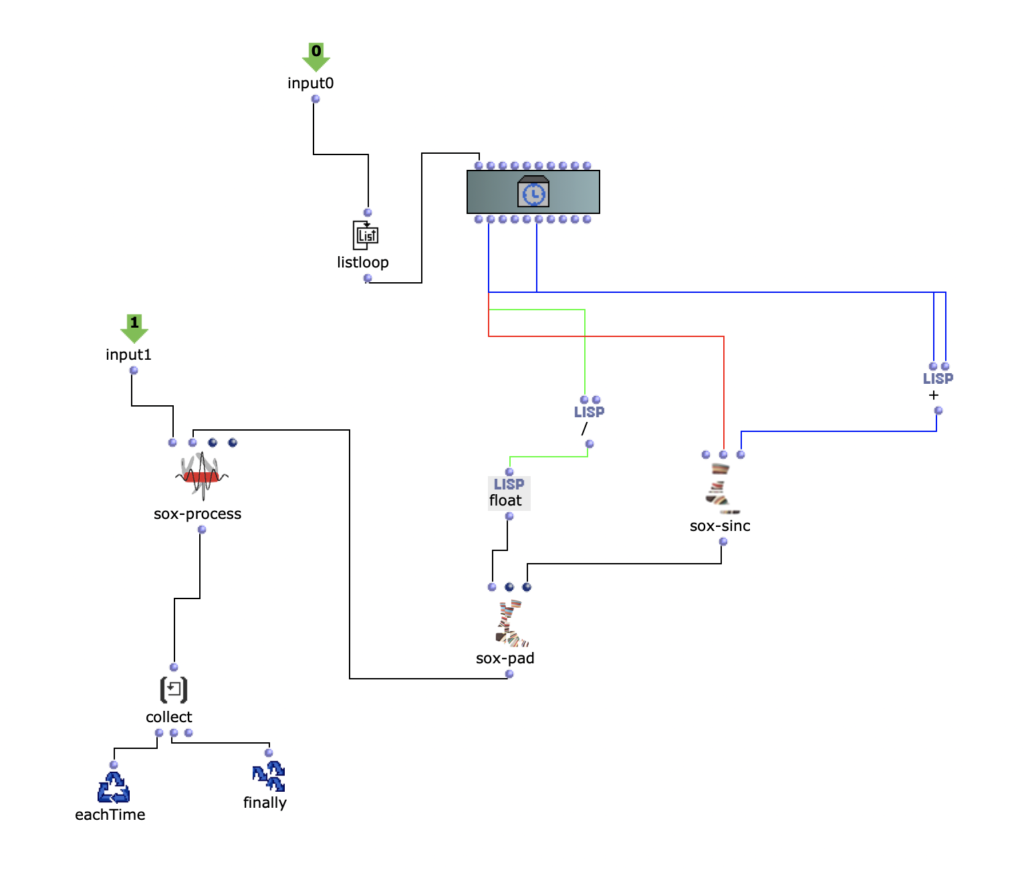
Zunächst werden im ersteren „peakloop“ einzelne Amplitudenpeaks aus dem Amplitudenklang herausanalysiert. Daraufhin dient diese Analyse im Herzstück des Patches, dem „choosefreq“ Loop zur Auswahl interessanter Teilbereiche aus dem Spektralsample. Lautstarke Peaks filtern hierbei schmalere Bänder aus höheren Frequenzbereichen und bilden einen Kontrast zu schwächeren Peaks, welche etwas breiter Bänder aus tieferen Frequenzbereichen filtern.
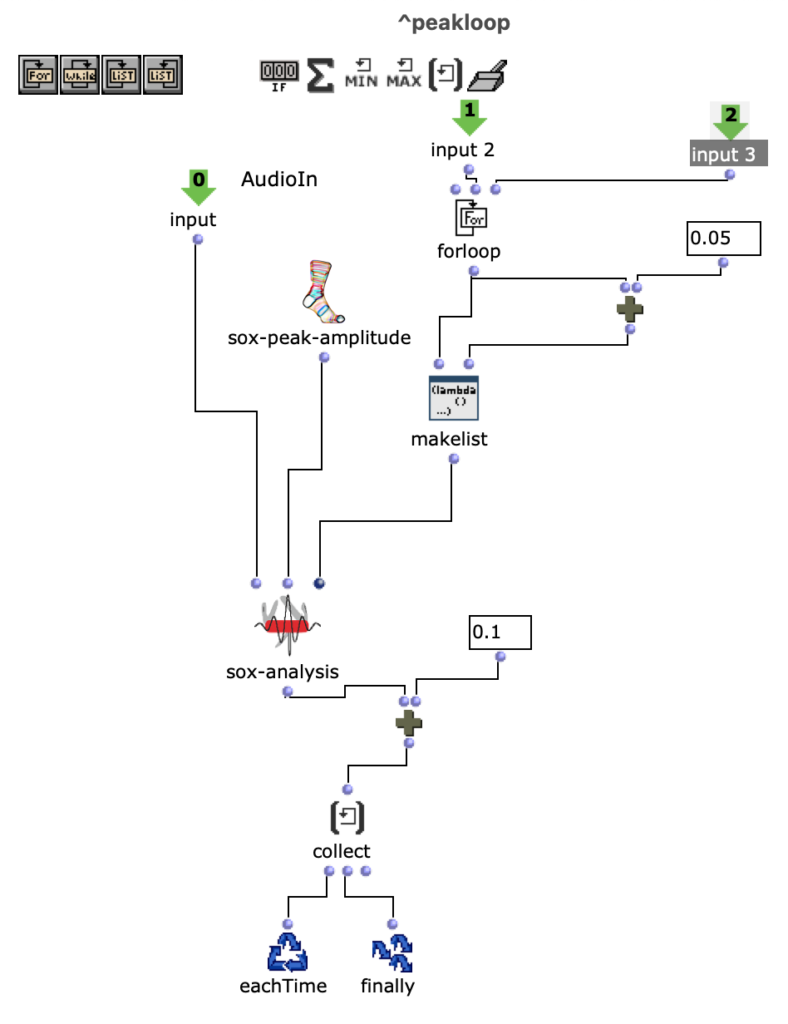
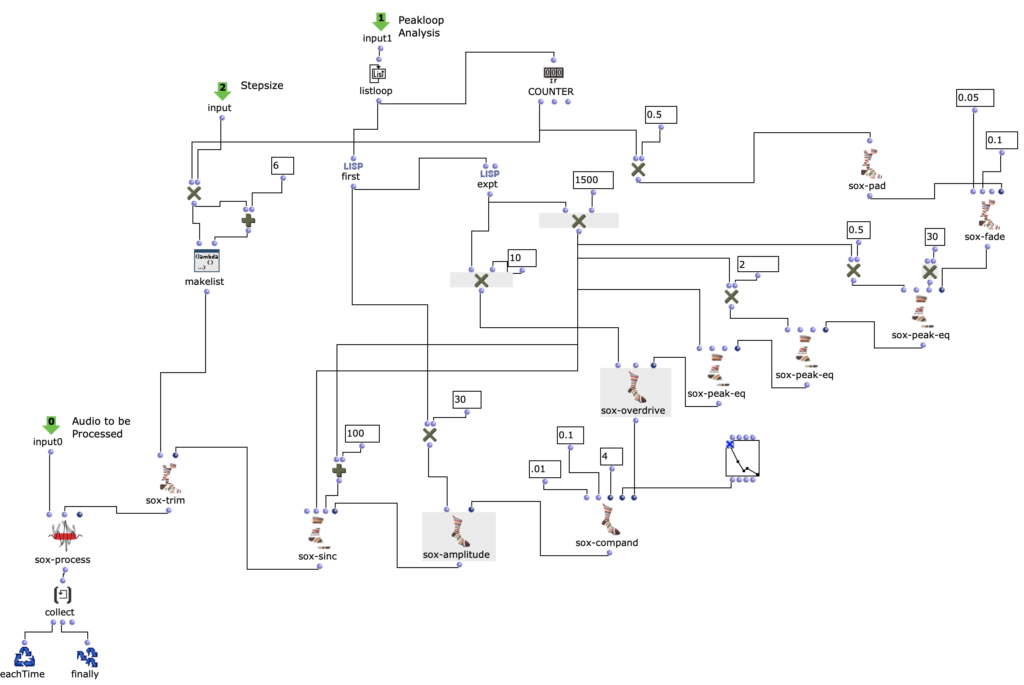
Wie klein die jeweiligen Iterationsschritte sind, wirkt sich dabei sowohl auf die Länge, als auch auf die Auflösung des gesamten Outputs aus. So können je nach Sample-Material sehr viele kurze Grains oder weniger, aber dafür längere Teilabschnitte erstellt werden. Beide dieser Parameter sind jedoch frei und unabhängig voneinander wählbar.
Im beigefügten Stück wurde sich beispielsweise für eine relativ hohe Auflösung (also eine erhöhte Anzahl an Iterationsschritten) in Kombination mit längerer Dauer des ausgeschnittenem Samples entschieden. Dadurch entsteht ein eher meditativer Charakter, wobei kein Teilabschnitt zu 100
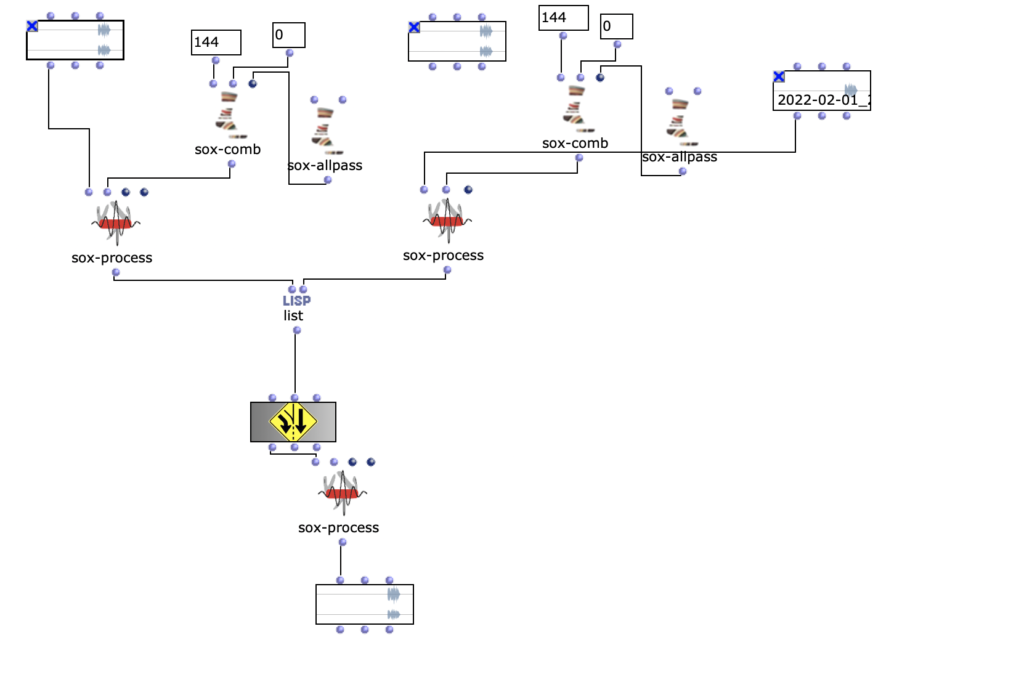
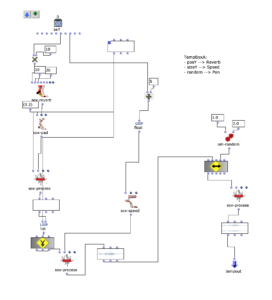
Der darauffolgende Überarbeitungsschritt galt vor allem einer präziseren Herausarbeitung der Unterschiede zwischen den einzelnen Iterationsschritten. Dazu wurde eine Reihe an Effekten eingesetzt, welche sich wiederum je nach Peak-Amplitude des Amplitudenklangs unterschiedlich verhalten. Um dies zu ermöglichen, wurde die Effektreihe direkt in den Peakloop integriert.
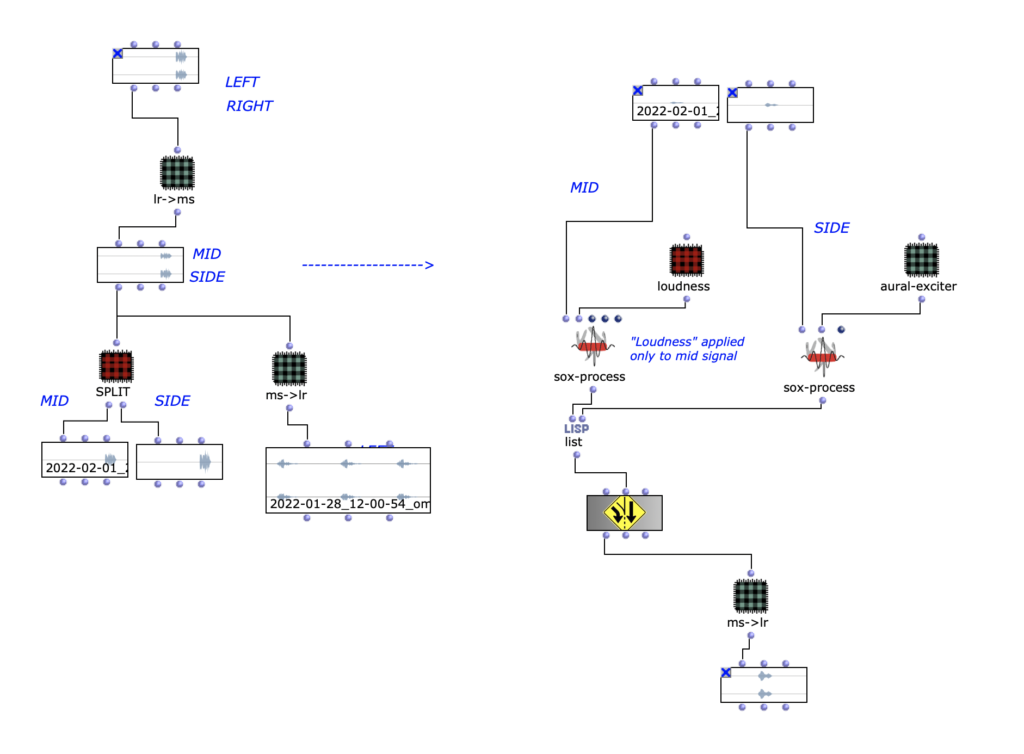
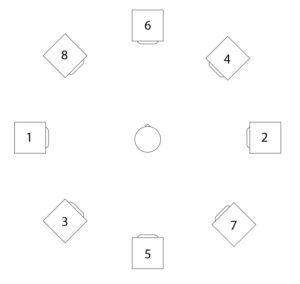
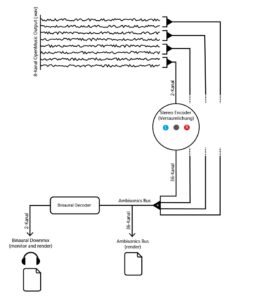
Im dritten und letztem Überarbeitungsschritt erfolgte die Spatialisierung des Audios auf 8 Kanäle.
Hierbei klingen die einzelnen Kanäle ineinander und ändern ihre Position im Uhrzeigersinn. Somit bleibt der Grundcharakter des Stückes bestehen, jedoch ist es nun zusätzlich möglich, das „Durcharbeiten“ des choosefreq Loops räumlich zu verfolgen. Damit diese Räumlichkeit erhalten bleibt, wurde der Output anschließend mithilfe von Binauralix für den Upload in binaural Stereo umgewandelt.
Spectral Select – Ambisonics
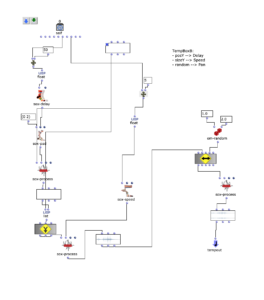
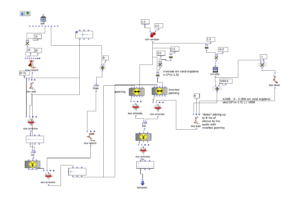
Im Zuge einer weiteren Überarbeitung wurde Spectral Select über die spatialisation class „Hoa-Trajectory“ von OM-Prisma neu spatialisiert und in das Ambisonics Format gebracht.
Damit sich dieser Schritt konzeptionell und klanglich gut in die bisherigen Bearbeitungen eingliedert, soll der Amplitudenklang auch bei der Raumposition eine wichtige Rolle spielen.
Die Möglichkeiten mithilfe von Open-Music und OM-Prisma Klänge zu spatialisieren sind zahlreich. Letzten Endes wurde entschieden, mit Hoa-Trajectory zu arbeiten. Hierbei ist die Klangquelle nicht an eine feste Position im Raum gebunden und kann mit einer Trajektorie beschrieben werden, welche auf die Gesamtdauer des Audio-Inputs skaliert wird.
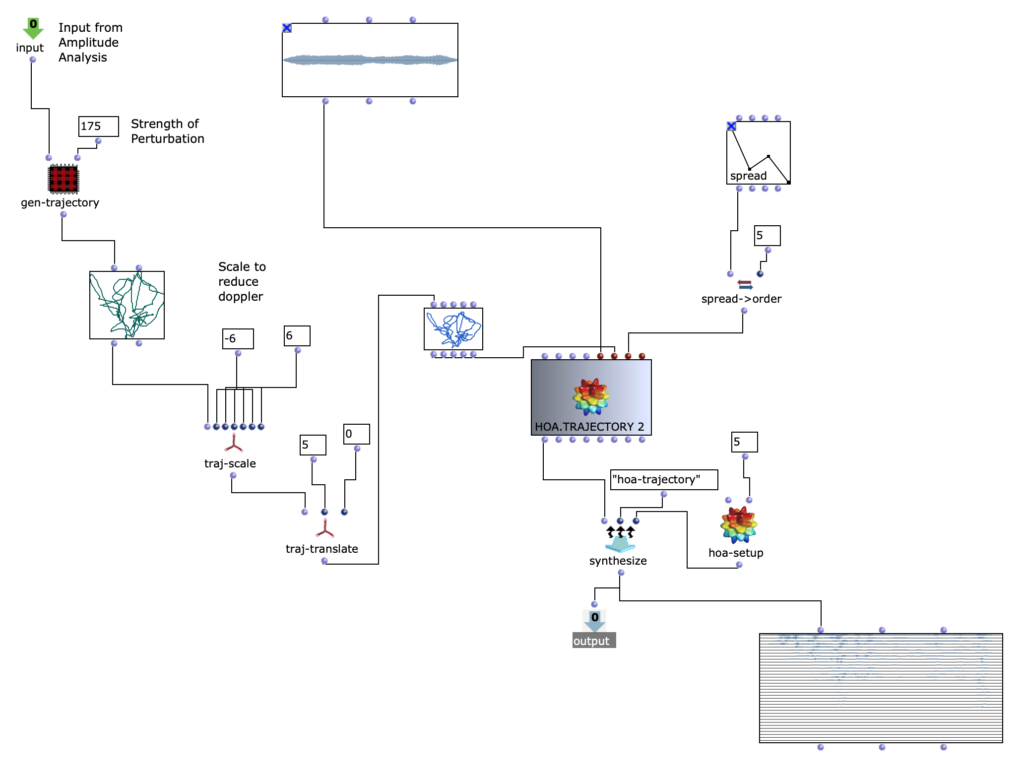
Die Trajektorie wird in Abhängigkeit der Amplituden-Analyse im vorhergehenden Schritt erstellt.
Dabei wird eine simple, dreidimensionale Kreis Bewegung, welche sich in Spiralbewegung nach unten dreht, mit einer komplexeren, zweidimensionalen Kurve perturbiert. Die Y-Werte der komplexeren Kurve entsprechen dabei den herausanalysierten Amplitudenwerten des Amplitudenklanges.
Somit ergeben sich je nach skalierung der Amplitudenkurve mehr oder weniger starke Abweichungen der Kreisbewegung. Höhere Amplitudenwerte sorgen also für ausuferndere Bewegungen im Raum.
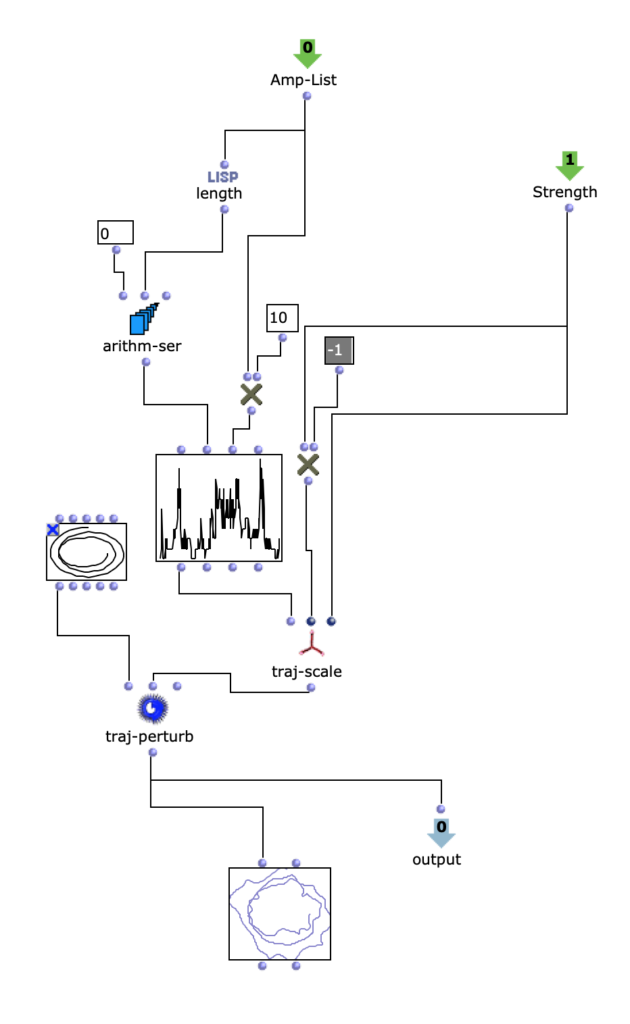
Interessant hierbei ist, dass OM-Prisma auch Doppler-Effekte mitberücksichtigt. Dadurch ist zusätzlich hörbar, dass bei höheren Amplitudenwerten extremere Abstände zur Hörposition in der selben Zeit zurückgelegt werden. Dadurch nimmt dieser Arbeitsschritt unmittelbar Einfluss auf die Klangfarbe des gesamten Stückes.
Je nach Skalierung der Trajektorie können schnelle Bewegungen dadurch stark überbetont werden, allerdings können (ab einer zu großen Entfernung) auch Artfakten entstehen.
Damit ein besserer Eindruck Ensteht folgen 2 verschiedene durchläufe des Algorithmus mit unterschiedlichen Abständen zum Hörer.
Version mit näherem Abstand und moderateren Doppler Effekten – Binaural Stereo
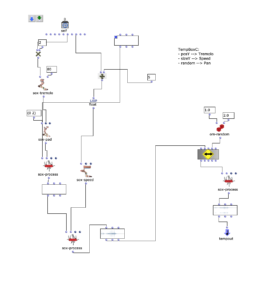
Spektralklang sowie Amplitudenklang wurden in diesem Beispiel im Gegensatz zu den vorherigen Klangbeispielen ausgetauscht. Es handelt sich hierbei um ein längeres Soundfile zur Analyse der Amplituden und einen weniger verzerrten Drone als Spektralklang.
Die Idee hinter diesem Projekt ist ohnehin, mit verschiedenen Klangdateien zu experimentieren.
Daher wurde auch der alter Algorithmus noch einmal überarbeitet um mehr Flexibilität bei unterschiedlichen Klangdateien zu bieten:
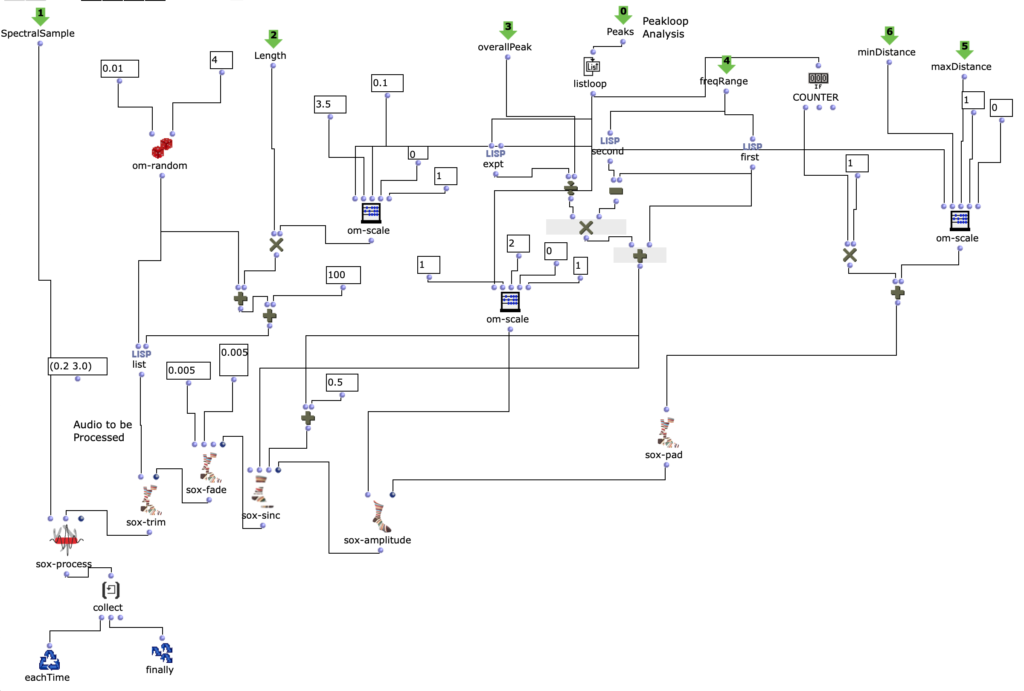
Außerdem wird nun aus dem Spektralklang auf der Zeitachse randomisiert ausgewählt. Dadurch soll jeglicher formgebender Zusammenhang aus der Magnitude des Amplitudenklangs stammen und jegliche Klangfarbe aus dem Spektralklang extrahiert werden.